基于谱分解的数据处理方法及系统、设备、介质
- 国知局
- 2024-09-05 14:56:48
本发明涉及计算机视觉,尤其涉及一种基于谱分解的数据处理方法及系统、设备、介质,通过使用张量分解将大量图片的信息压缩至少量的图片内的方法,使得神经网络在蒸馏后的图片训练后的效果和在原始图片上训练后效果保持一致。
背景技术:
1、在现有的深度学习框架中,大量的数据给模型训练带来显著的收益。然而,大量的数据会对存储空间构成挑战(storage space challenge)。同时,将原始数据提供给模型训练也会带来信息安全和知识泄漏的风险(knowledge leakage)。因此,将整个数据集的信息蒸馏成少量图片能够表达的形式已经成为最近数据处理方法的趋势。
2、在现有的各种进行样本蒸馏的数据处理方法中,基于核心集选择(coresetselection)的算法在现成的数据集中选择具有代表性的子集,但是这一类方法会在没有杰出样本的数据集中表现糟糕。后续有研究人员提出基于优化(optimization-based)的方法,其由于性能优秀而被广泛使用。这类方法使用原始样本和蒸馏样本(distillateddataset)训练两个神经网络,并记录其优化过程的两个轨迹,其核心思想原始样本和蒸馏样本效果一致,所以这两个轨迹应该保持一致。通过构造轨迹一致的优化目标,对蒸馏样本进行优化。然而,这种方法是在像素空间(pixel space)上进行,图像像素空间通常是低秩(low-rank)的,所以直接在像素空间上进行蒸馏样本的学习是不高效的,限制了这种数据处理方法的效果。
3、本发明提供了一种基于谱分解的数据处理方法及系统、设备、介质,通过使用张量分解将大量图片的信息压缩至少量的图片内的方法,使得神经网络在蒸馏后的图片训练后的效果和在原始图片上训练后效果保持一致。
技术实现思路
1、本发明提供了一种基于谱分解的数据处理方法及系统、设备、介质,通过使用张量分解将大量图片的信息压缩至少量的图片内的方法,使得神经网络在蒸馏后的图片训练后的效果和在原始图片上训练后效果保持一致。
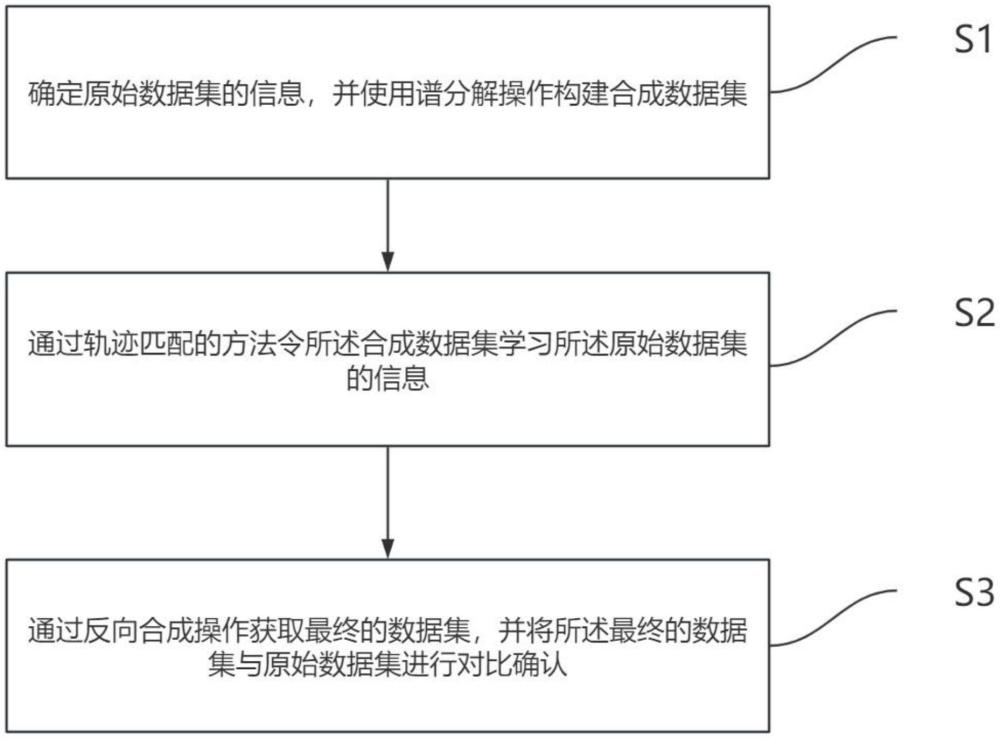
2、本发明通过下述技术方案实现:一种基于谱分解的数据处理方法,包括以下步骤:
3、步骤s1,确定原始数据集的信息,并使用谱分解操作构建合成数据集;
4、步骤s2,通过轨迹匹配的方法令所述合成数据集学习所述原始数据集的信息;
5、步骤s3,通过反向合成操作获取最终的数据集,并将所述最终的数据集与原始数据集进行对比确认。
6、为了更好地实现本发明,进一步地,所述步骤s1中确定原始数据集的信息包括:确定原始数据集的四维信息并表示为n×c×h×w,其中n表示数据集总张数,c表示数据集中图片的通道数,h和w表示图片长和宽。
7、为了更好地实现本发明,进一步地,所述步骤s1中使用谱分解操作构建合成数据集的方法包括:
8、定义构成合成数据集的两个组成成分,分别为四维的张量和每个维度对应定义的变换矩阵所述四维的张量表示为所述变换矩阵表示为其中,t1×t2×t3×t4是设置的超参数;
9、使用谱分解设置所述超参数对所述合成数据集进行分解。
10、为了更好地实现本发明,进一步地,所述步骤s2包括:
11、步骤s21,使用相同的网络结构和初始化方法,定义两个相同的任意结构的神经网络;步骤s22,分别用所述原始数据集和所述合成数据集去训练所述神经网络,将训练过程的参数保存下来,将不同更新步骤的网络参数定义为轨迹,通过训练得到两组训练轨迹;
12、步骤s23,将两组训练轨迹进行一致性约束,在训练完成后,得到更新后的变换矩阵和四维的张量通过梯度的后向传播,更新所述合成数据集,令所述合成数据集学习所述原始数据集的信息。
13、为了更好地实现本发明,进一步地,所述步骤s22包括:
14、在训练过程中,损失函数选用l2标准化损失函数,随机选取整个训练过程中的一部分作为网络初始化信息和轨迹信息;
15、在l2标准化损失函数的基础上结合分布损失函数,将在所述合成数据集上训练的神经网络,在所述原始数据集上进行测试。
16、为了更好地实现本发明,进一步地,所述l2标准化损失函数表示为:其中,表示所述合成数据集训练神经网络得到的轨迹,t表示起点,n表示该轨迹的更新的次数,表示使用所述原始数据集训练网络得到的轨迹,m表示其更新次数,n的取值小于m;
17、所述分布损失函数表示为:其中,表示原始数据集,l表示交叉熵分类函数;所述在l2标准化损失函数的基础上结合分布损失函数表示为:
18、
19、为了更好地实现本发明,进一步地,所述步骤s3包括:将所述更新后的变换矩阵和四维的张量进行矩阵乘法相乘,获得并得到一个新的合成数据集,形状定义为u1×u2×u3×u4,通过与原始数据集进行对比得到u1×u2×u3×u4=m×c×h×w。
20、本发明还提供了一种基于谱分解的数据处理系统,包括构建单元、学习单元和对比确认单元,其中:
21、构建单元,用于确定原始数据集的信息,并使用谱分解操作构建合成数据集;
22、学习单元,用于通过轨迹匹配的方法令所述合成数据集学习所述原始数据集的信息;
23、对比确认单元,用于通过反向合成操作获取最终的数据集,并将所述最终的数据集与原始数据集进行对比确认。
24、本发明还提供了一种电子设备,该电子设备包括处理器和存储器;处理器中包括上述第二方面所记载的基于谱分解的数据处理系统。
25、本发明还提供了一种计算机可读存储介质,该计算机可读存储介质包括指令;当指令在上述第三方面所记载的电子设备上运行时,使得电子设备执行上述第一方面所记载的方法。
26、本发明与现有技术相比,具有以下优点及有益效果:
27、(1)本发明提供一种基于谱分解的数据处理方法及系统、设备、介质,通过使用张量分解将大量图片的信息压缩至少量的图片内的方法,使得神经网络在蒸馏后的图片训练后的效果和在原始图片上训练后效果保持一致;
28、(2)本发明提供一种基于谱分解的数据处理方法及系统、设备、介质,使得处理后的数据集和原始的数据集差别很大,可以很好的保护图片隐私,同时在视觉上效果更加丰富。
技术特征:1.一种基于谱分解的数据处理方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于谱分解的数据处理方法,其特征在于,所述步骤s1中确定原始数据集的信息包括:
3.根据权利要求1所述的一种基于谱分解的数据处理方法,其特征在于,所述步骤s1中使用谱分解操作构建合成数据集的方法包括:
4.根据权利要求1所述的一种基于谱分解的数据处理方法,其特征在于,所述步骤s2包括:
5.根据权利要求4所述的一种基于谱分解的数据处理方法,其特征在于,所述步骤s22包括:在训练过程中,损失函数选用l2标准化损失函数,随机选取整个训练过程中的一部分作为网络初始化信息和轨迹信息;
6.根据权利要求5所述的一种基于谱分解的数据处理方法,其特征在于,包括:
7.根据权利要求4所述的一种基于谱分解的数据处理方法,其特征在于,所述步骤s3包括:将所述更新后的变换矩阵和四维的张量进行矩阵乘法相乘,获得并得到一个新的合成数据集,形状定义为u1×u2×u3×u4,通过与原始数据集进行对比得到u1×u2×u3×u4=m×c×h×w。
8.一种基于谱分解的数据处理系统,其特征在于,包括构建单元、学习单元和对比确认单元,其中:
9.一种电子设备,其特征在于,包括处理器和存储器;所述处理器用于运行如权利要求8所述的基于谱分解的数据处理系统。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质包括指令;当指令在如权利要求9所述的电子设备上运行时,使得所述电子设备执行如权利要求1-7任一项所述的方法。
技术总结本发明涉及计算机视觉技术领域,公开了一种基于谱分解的数据处理方法及系统,方法包括:步骤S1,确定原始数据集的信息,并使用谱分解操作构建合成数据集;步骤S2,通过轨迹匹配的方法令所述合成数据集学习所述原始数据集的信息;步骤S3,通过反向合成操作获取最终的数据集,并将所述最终的数据集与原始数据集进行对比确认。系统包括构建单元、学习单元和对比确认单元。本发明还公开了一种电子设备及计算机可读存储介质。本发明通过使用张量分解将大量图片的信息压缩至少量的图片内的方法,使得神经网络在蒸馏后的图片训练后的效果和在原始图片上训练后效果保持一致。技术研发人员:刘帅成,程深,杨少雷,洪铭波受保护的技术使用者:电子科技大学技术研发日:技术公布日:2024/9/2本文地址:https://www.jishuxx.com/zhuanli/20240905/288948.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。