一种基于聚类算法的5G通信基站地址规划方法
- 国知局
- 2024-09-05 14:56:47
本发明涉及通信,具体是一种基于聚类算法的5g通信基站地址规划方法。
背景技术:
1、在当前的5g基站地址规划实践中,传统方法的局限性日益凸显,这些方法往往依赖于人工经验和覆盖预测模型,结合地理信息系统gis和现场勘测数据进行选址,这种依赖导致规划过程不仅耗时耗力,而且容易受到主观判断的影响,从而影响选址的精确性和全面性,此外,这些方法在处理复杂多变的地理环境和多样化的用户需求时显示出明显的不灵活性,难以适应快速城市化和信息化的趋势,因此,为了克服这些挑战并有效响应5g技术的推广需求,需要一种更高效自动化规划方法,这种方法能够综合利用多源数据,通过数据驱动的分析提供更精确、动态可调整的基站选址方案,旨在提升最终用户的网络体验并优化网络运营商的成本效益。
技术实现思路
1、本发明的目的在于提供一种基于聚类算法的5g通信基站地址规划方法,灵活选择k-means和dbscan算法,根据特征相关性不同选择合适算法,提高在处理复杂多变的地理环境和用户需求时的适应性和灵活性,能够有效地解决传统方法在人工依赖、精确性、灵活性和数据驱动等方面的局限性,提高了基站选址规划的科学性、准确性和效率。
2、本发明的目的可以通过以下技术方案实现:
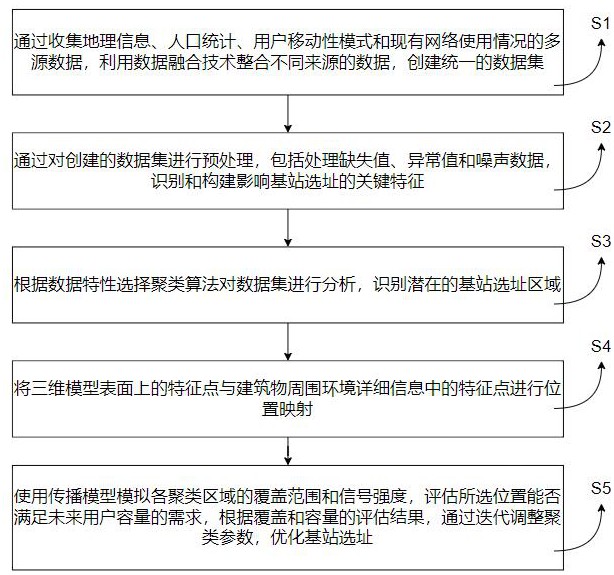
3、本技术提供了一种基于聚类算法的5g通信基站地址规划方法,包括如下步骤:
4、多源数据获取与融合,通过收集地理信息、人口统计、用户移动性模式和现有网络使用情况的多源数据,利用数据融合技术整合不同来源的数据,创建统一的数据集;
5、通过对创建的数据集进行预处理,包括处理缺失值、异常值和噪声数据,识别和构建影响基站选址的关键特征;
6、聚类分析,根据数据特性选择聚类算法对数据集进行分析,识别潜在的基站选址区域;
7、基站选址优化,使用传播模型模拟各聚类区域的覆盖范围和信号强度,评估所选位置能否满足未来用户容量的需求,根据覆盖和容量的评估结果,通过迭代调整聚类参数,优化基站选址。
8、进一步的,所述创建统一的数据集,具体包括:
9、对获取的每个数据源进行清洗,处理缺失值、异常值和噪声数据,将经过处理的不同来源的数据进行标准化处理;
10、根据数据之间的关联关系,通过地理坐标进行数据匹配和关联,建立数据之间的联系;
11、利用集成学习方法的数据融合技术,将已关联匹配的不同数据源整合到统一的数据集中。
12、进一步的,根据步骤s11进行标准化处理,具体将数据归一化到[0, 1]区间,通过最小-最大归一化进行,公式如下:
13、
14、其中,x是原始数据,和分别是数据集中的最小值和最大值;
15、归一化之后,使用以下公式将数据从[0, 1]区间转换到[-1, 1]区间,具体表示为:1;将处理后的数据将会落在[-1, 1]区间内,用于创建统一的数据集。
16、进一步的,所述数据匹配和关联,将卫星遥感数据、地形地貌信息以及政府发布的地理数据不同来源的数据进行精确匹配,利用空间索引结构对地理数据进行索引构建,将经过处理的数据以矢量形式表示;
17、根据每个地理要素与在空间中的位置,构建r树索引进行数据匹配与关联,其中节点代表矩形范围,叶子节点存储实际的地理要素数据,非叶子节点存储子节点的空间位置信息,再逐个将地理要素数据插入到r树中,根据其空间位置构建索引结构。
18、进一步的,对创建的数据集进行预处理,对于数据集中的缺失值,进行填充或使用特殊标记处理,通过四分位距识别和处理异常值,应用平滑技术减少数据中的随机波动,通过斯皮尔曼等级相关系数,来分析不同特征之间的相互关系,具体内容包括:
19、设定有两个变量x和y的数据集,计算数据集的斯皮尔曼等级相关系数:ρ = 1 -(6 * σd2) / (n3- n);
20、其中,σd2表示等级差的平方和;n表示观测值的数量,ρ的值介于-1到1之间,当相关系数趋于1 或 -1,表示特征之间存在强相关性;若相关系数趋于0,则说明特征之间没有相关性。
21、进一步的,当斯皮尔曼等级相关系数趋于1 或 -1,选择k-means算法,将相关系数趋于1或-1的特征作为聚类分析的输入特征,对选定的特征进行聚类分析,将数据点划分为不同的簇,确定聚类数目k值和迭代次数,运行k-means算法进行聚类。
22、进一步的,所述k-means算法包括:
23、确定需要划分的簇的数量k,选择k个数据点作为初始的质心;
24、对于每个数据点,计算其与各个质心的距离,将其分配给距离最近的质心所代表的簇;
25、质心的距离通过欧式距离进行计算,表示为:
26、
27、其中,表示为数据点,表示为质心,表示数据的i在第k维的特征值,表示质心j在第k维的坐标值,p是数据的维度;
28、对于每个簇,计算该簇所有数据点的均值,更新质心为该均值;
29、更新质心的公式表示为:
30、
31、其中,是簇中数据点的数量,求和遍历簇内的所有数据点;
32、重复步骤2和步骤3,直至质心不再发生变化或达到预设的迭代次数,并得到一组簇,每个簇具有一个质心,表示该簇的中心点。
33、进一步的,当相关系数趋于0,选择dbscan的聚类算法,将数据点划分为不同的簇,包括核心点、边界点和噪声点;
34、其中dbscan的聚类算法内容包括:
35、计算ε邻域,对于数据集中的每个点,计算其ε邻域中有多少个邻居;
36、标记核心点,当一个点的ε邻域中的点的数量大于或等于minpts时,则这个点就被标记为核心点;
37、寻找密度相连的点,以ε邻域半径为搜索范围,在ε邻域内寻找与核心点密度相连的点,分别设定p为待检测的数据点,o为另一个数据点,当点p在点o的ε邻域中,并且o是一个核心点,则p是与o密度相连的点;
38、标记噪声点和边界点,对没标记的点标记为噪声点,与某个核心点密度相连但不是核心点的点标记为边界点;
39、为簇标签赋值,为每个核心点或与其密度相连的点赋予独立的簇标签,当一个点与多个核心点密度相连时,将被赋予第一个找到的核心点的簇标签,所有的噪声点形成独立的簇。
40、进一步的,对k-means算法和dbscan算法得到的簇,计算簇内数据点的特征均值,再分析每个簇的质心,得到每个簇在特征空间的位置,确定簇的中心特征,对比不同簇的质心特征,分析簇之间的差异,当某些簇的质心在特征上相似时,则表示存在潜在的基站选址区域。
41、进一步的,使用传播模型模拟各聚类区域的覆盖范围和信号强度,以及评估所选位置是否能满足未来用户容量的需求,具体内容包括:
42、对于每个聚类区域,使用无线电波传播模型预测基站的信号覆盖范围,通过模拟生成强度地图,显示不同区域的预计信号质量;
43、结合区域内的用户密度数据和预测的网络负载情况,评估每个聚类区域内的基站是否能够处理预期的用户请求;
44、根据覆盖和容量的评估结果,对聚类参数进行调整,当某个区域的预测用户容量超过基站的处理能力时,则在区域内进一步细分,寻找更多的潜在站点;
45、重复上述步骤,直到找到满足覆盖范围和用户容量需求的基站地址区域。
46、本发明的有益效果为:
47、本发明通过多源数据获取与融合、数据预处理和聚类分析等步骤,解决当前5g基站地址规划实践中传统方法的局限性,该方法利用数据驱动,整合地理信息、人口统计、用户移动性模式和现有网络使用情况等多源数据,经过清洗、标准化处理,并通过斯皮尔曼等级相关系数分析特征相关性,在聚类分析阶段,根据相关系数选择k-means或dbscan算法进行紧密聚类或处理密度不均匀数据,有效识别潜在的基站选址区域,解决传统方法依赖人工经验和覆盖预测模型,容易受主观判断影响,耗时且精确性有限的问题;
48、进一步基站选址优化阶段,通过传播模型模拟覆盖范围和信号强度,评估未来用户容量需求,调整聚类参数优化基站选址,不仅减少了人工依赖和主观判断影响,提高了规划效率和准确性,还增强了适应复杂环境和多样化需求的能力,应对快速城市化和信息化趋势,从根本上解决了传统方法的不灵活性和局限性。
本文地址:https://www.jishuxx.com/zhuanli/20240905/288947.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。