一种室内空间关键字个性化查询方法
- 国知局
- 2024-09-05 15:03:29
本发明涉及空间关键字查询,具体是一种室内空间关键字个性化查询方法。
背景技术:
1、目前,大部分空间关键字的研究主要集中在室外环境下的欧式空间和路网空间,而针对室内环境(如大型商场、医院和图书馆等复杂场景)的空间关键字查询研究相对较少。随着室内基于位置的服务(location based service, lbs)的发展,越来越多的文本类型数据在室内环境中生成,传统的查询方法已经无法满足人们日益增长的需求。因此,如何高效地检索室内环境下的空间关键字相关信息成为一个迫切需要解决的问题。
2、尽管对室内空间关键字查询方法的研究已经取得了一定进展,但仍存在研究空白,特别是在用户个性化查询需求的分析方面有待进一步探讨。不同用户对相同的查询请求可能有着不同的期望和需求,个性化查询直接影响了查询结果的准确性和用户满意度。如果一种方法能够快速且准确地返回满足室内环境下用户个性化查询需求的结果,那么它不仅填补了现有研究的空白,还能显著提升用户的室内查询体验。
技术实现思路
1、针对现有技术的以上缺陷和改进需求,本发明提供了一种室内空间关键字个性化查询方法,其目的在于,通过构建一种新的iskir-tree索引,能够有效提高对室内空间关键字查询的处理效率,通过基于iskir-tree索引的剪枝操作对数据集进行有效的精炼,从而减少查询的时间开销和资源消耗,通过综合考虑文本相似性、空间近邻性和用户偏好度的得分函数对剪枝后得到的优先队列中的数据点进行打分并排序,从而返回满足用户个性化查询需求的结果。
2、为了解决上述技术问题,本发明通过以下技术方案来实现:
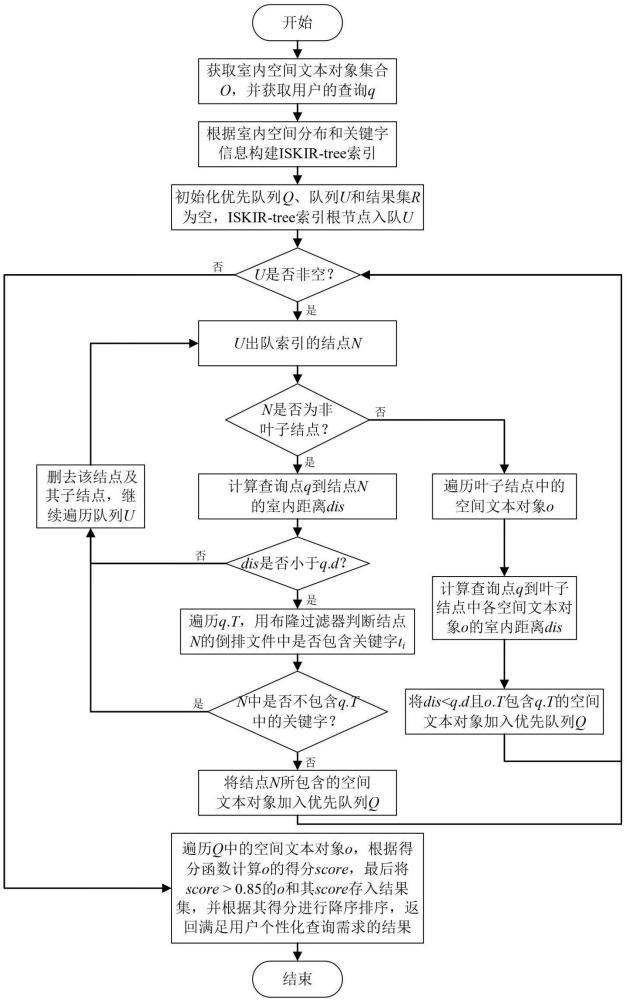
3、本发明提供一种室内环境下的空间关键字查询处理方法,包括以下步骤:
4、步骤1:根据室内空间文本对象集合的室内分区分布及其包含的关键字信息为用户的查询构建iskir-tree索引;
5、步骤2:从iskir-tree索引的根结点开始遍历,根据结点的距离矩阵计算查询点 q到结点的室内距离,若室内距离大于用户的查询中给定的偏好距离,则该结点可以被安全地剪枝,否则继续遍历;利用布隆过滤器对非结点中的关键字进行判断,若判断出用户查询的关键字不在该结点所包含的关键字集合中,则该结点可以被安全地剪枝,否则继续遍历;直至遍历全部索引后结束遍历后,将剪枝后得数据存入一个优先队列;
6、步骤3:根据一个综合考虑文本相似性、空间近邻性和用户偏好度的得分函数计算优先队列中的室内空间文本对象的得分,并根据其得分进行降序排序,获得得分高于0.85的室内空间文本集合作为结果集返回给用户。
7、可选的,步骤1中所述的室内空间文本对象集合 o={ o1, o2,..., o n},其中 o i表示一个室内空间文本对象;每个室内空间文本对象 o i都由一个二元组( loc, t)构成, o i .loc代表该室内空间文本对象的室内位置, o i .t代表该室内空间文本对象所包含的所有关键字的集合。
8、可选的,步骤1中所述的用户的查询即一个室内空间关键字个性化查询 q=( loc, t, pres, d),其中, q.loc代表查询点所在的室内位置, q. t代表查询中包含的关键字的集合, q. pres代表用户的查询偏好集合, q. d代表查询的偏好距离。
9、可选的,步骤1中所述的室内分区是指通过物理分隔手段(如墙壁、门或类似于门的通路等)在室内场景中划分出的具有明确功能和用途的独立空间,这些空间之间通常只能通过门或类似于门的通路相互到达。
10、优选的,步骤1的具体步骤如下:
11、步骤1.1:iskir-tree索引遵循自顶向下的构建思想,首先将室内空间按楼层结构进行划分,实现三维空间向二维空间的转换;
12、步骤1.2:然后,对于每一楼层,iskir-tree索引按照室内空间文本对象的室内分布进行构建;iskir-tree索引为每一个结点都维护该结点的倒排文件,包含文本倒排表和空间倒排表;其中,文本倒排表存储室内空间文本对象的关键字信息,空间倒排表存储室内空间文本对象对应的hilbert编码值;
13、对于非叶子结点,iskir-tree索引在倒排文件的基础上加入一个距离矩阵和一个布隆过滤器;其中,距离矩阵用于存储从该结点到达其子结点所在的通路门所需的室内距离,从而快速地计算查询点到该结点的室内距离;布隆过滤器通过多哈希函数生成哈希值并将这些值存储在位数组中,并利用位数组来快速地判断一个点是否在某个区域内,从而减少不必要的查询操作,提高查询的效率;
14、对于叶子结点,iskir-tree索引同样在倒排文件的基础上为其维护一个距离矩阵,与非叶子结点的距离矩阵不同的是,该距离矩阵用于存储其所包含的室内空间文本对象到其所在通路门的室内距离,从而高效地计算查询点到室内空间文本对象的室内距离。
15、可选的,所述的hilbert编码是利用hilbert空间填充曲线将室内空间文本对象的室内位置按照楼层顺序依次进行hilbert曲线编码,编码值随着楼层的递增而不断增加,从而使整个建筑的室内空间文本对象都有唯一对应的hilbert编码。
16、可选的,所述的通路门表示连通相邻室内分区的门或类似于门的通路。通路门可能具有方向性,例如航站门的登机口、大型超市的出入口等。
17、可选的,所述的布隆过滤器是一种空间效率高、概率型的数据结构,用于检测一个元素是否属于一个集合;布隆过滤器中存储通过多哈希函数生成的哈希值,其特点是在判断元素不属于集合时绝对准确,但在判断元素属于集合时可能会有一定的误判几率;在本发明中,布隆过滤器用于判断结点的倒排文件中是否不存在某个关键字,若判断某个关键字不存在,则对该结点进行剪枝操作,从而减少不必要的查询操作,提高整体查询性能。
18、优选的,步骤2中所述的室内距离的计算方法如下:
19、,
20、其中, v q表示 q所在的室内分区, v o表示 o所在的室内分区, d i, j和 d i, j '分别表示当前查询点 q去往室内空间文本对象 o需要经过的第一个通路门和最后一个通路门,| q, o|、| q, d i, j|和| d i, j ', o|表示从前者到后者的直线距离, dis( d i, j, d i, j ')表示从 d i, j到 d i, j '的最小距离。
21、优选的,步骤3中所述的文本相似性、空间近邻性、用户偏好度以及综合考虑文本相似性、空间近邻性和用户偏好度的得分函数的计算方法分别如下:
22、(1)查询点 q和室内空间文本对象 o之间的文本相似性的计算方法:
23、,
24、其中, ω代表 q.w中关键字所对应的权重, λ代表 o.t中关键字所对应的权重;∑( ω× λ) q.t∩o.t表示对 q.t与 o.t中相交的元素进行 ω× λ的加权并求和;∑( ω q.t∪ o.t +λ q.t∪ o.t +( ω× λ) q.t∩ o.t)表示对 q.t与 o.t的并集中的每个元素进行加权处理并求和。若该元素只属于 q.t,则只对其进行 ω加权;若该元素只属于 o.t,则只对其进行 λ加权;若该元素既属于 q.t又属于 o.t,则进行 ω× λ加权处理;
25、(2)查询点 q和室内空间文本对象 o之间的空间近邻性的计算方法:
26、,
27、其中, o. h表示室内空间文本对象 o的hilbert编码值, q. h表示查询点 q的hilbert编码值, dis( q, o)表示查询点 q与室内空间文本对象 o之间的室内距离, η是权重参数,用于平衡hilbert编码值对空间近邻性的影响;
28、(3)查询点 q和室内空间文本对象 o之间的用户偏好度的计算方法:
29、,
30、其中, p( q.t i∩ o.t i)表示查询 q中的关键字 t i和室内文本对象 o中的关键字 t i同时在用户搜索记录中出现的概率, p( q. t i)表示关键字 t i在用户搜索记录中出现的概率, p( o. t i)表示关键字 t i在用户搜索记录中出现的概率, ε=0.001,常数 ε用来避免除以零的情况;通常情况下,用户的偏好会随着时间的推移而发生变化,虽然用户的所有历史访问行为都可能会对最终的偏好程度产生影响,但近期的访问对其的影响更大;因此时间衰减因子 δ用于控制衰减的速度,而∆ t则代表当前查询时间与查询记录产生时间的差值,∆ t以天单位;
31、(4)综合考虑文本相似性、空间近邻性和用户偏好度的得分函数的计算方法:
32、,
33、其中, sim( q, o)表示查询点 q和室内空间文本对象 o之间的文本相似性, prox( q, o)表示查询点 q和室内空间文本对象 o之间的空间近邻性, pre( q, o)表示用户对查询点的偏好程度, α, β,γ∈(0,1)为三个平滑因子,作用是平衡文本相关性、空间近邻性和用户偏好度。
34、总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
35、(1)与传统的基于欧式和路网空间的查询方法不同,本发明提出的一种室内空间关键字个性化查询方法更适用于结构复杂的室内环境,并能够有效满足用户的个性化查询需求;
36、(2)本发明提出的iskir-tree索引融入了hilbert编码技术,能够更好地确定室内环境下的空间近邻性;此外,该索引还引入了布隆过滤器和距离矩阵,能够有效地处理室内环境下的空间关键字个性化查询;
37、(3)由于本发明基于iskir-tree索引进行了剪枝操作,可以在查询初期快速地删除掉不满足查询要求的数据,从而显著地提高查询的效率;
38、(4)由于本发明提出了一个综合考虑文本相似性、空间近邻性和用户偏好度的得分函数,利用这一得分函数对剪枝后得到的优先队列中的数据点进行打分并排序,生成结果集,可以筛选出满足用户个性化查询需求的结果,提高了查询的准确性。
本文地址:https://www.jishuxx.com/zhuanli/20240905/289271.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表