一种图像文本联合数据处理方法、设备及介质
- 国知局
- 2024-10-09 14:47:38
本发明涉及数据预处理,具体涉及一种图像文本联合数据处理方法、设备及介质。
背景技术:
1、近年来,深度学习技术在计算机视觉(computer vision,cv)和自然语言处理(natural language processing,nlp)领域取得了显著的进展,其中,图像识别是计算机视觉领域的一个核心任务,目的是让计算机能够识别和理解图像中的对象、场景和活动等。模型训练是指使用大量标注好的图像数据来训练深度学习模型,使其能够准确地识别图像中的内容。这个过程通常包括数据预处理、模型选择、损失函数定义、优化算法应用等步骤。
2、由于获取大量标注准确的训练数据成本高昂且耗时,图像数据增强成为一种提高模型泛化能力的技术手段。数据增强通过应用一系列随机变换(如旋转、缩放、裁剪、颜色调整等)来增加数据集的多样性,从而减少模型对原始训练数据的过拟合,并提高模型在未见数据上的鲁棒性。在跨模态模型的数据训练过程中,由于图像数据与文本数据这两种模态具有不同的表达方式,在对图像数据增强的过程中,可能采用如颜色抖动(colorjittering)或混合(mixup)的技术手段,而导致图像的视觉特征进而改变,而相应的文本不会进行相应的调整,以此使得图像与文本出现语义不一致的问题,模型在后续的训练过程中可能无法正确学习到图像和文本之间的关联,导致模型在实际应用中的精度下降,体验不好。
技术实现思路
1、针对现有技术存在的不足,第一方面,本发明提出一种图像文本联合数据处理方法,以解决现有技术中存在的在跨模态模型的数据训练过程中,在对图像数据增强的过程中,由于图像数据与文本数据这两种模态具有不同的表达方式,使得图像的视觉特征在增强后而改变,使得图像与文本出现语义不一致,而导致后续训练的模型在实际应用中的精度下降,体验不好的技术问题。
2、本发明采用的技术方案是,一种图像文本联合数据处理方法,包括:
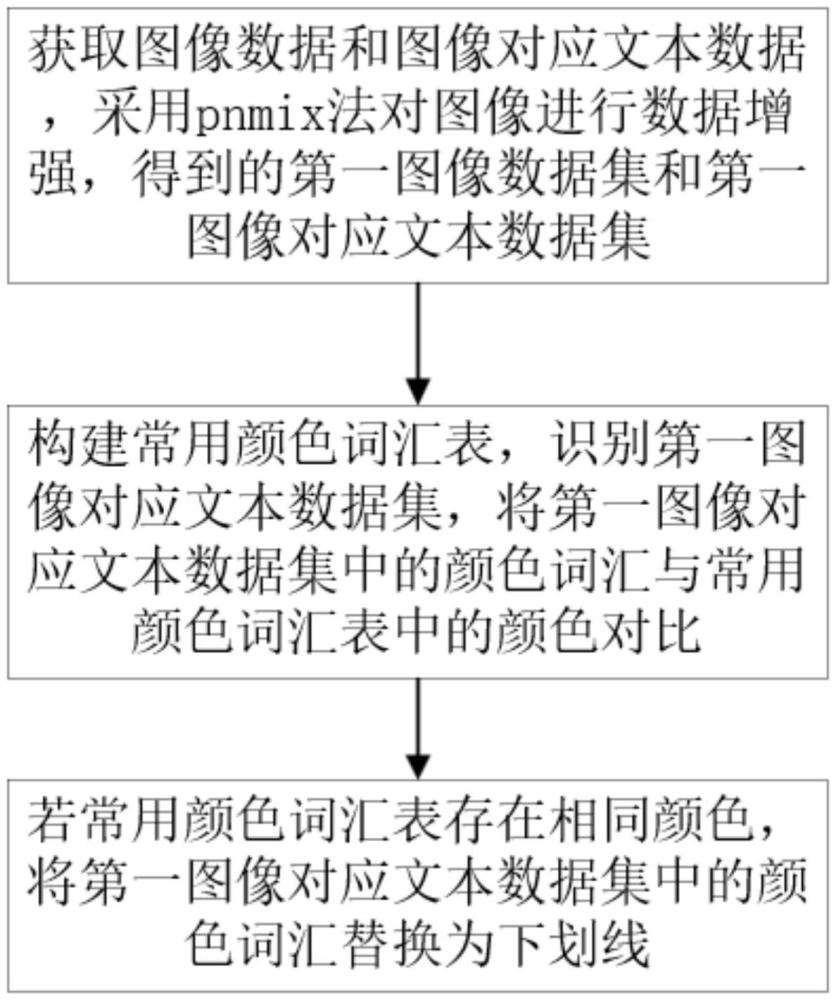
3、获取图像数据和图像对应文本数据,采用pnmix法对图像进行数据增强,得到的第一图像数据集和第一图像对应文本数据集;
4、构建常用颜色词汇表,识别第一图像对应文本数据集,将第一图像对应文本数据集中的颜色词汇与常用颜色词汇表中的颜色对比;
5、若常用颜色词汇表存在相同颜色,将第一图像对应文本数据集中的颜色词汇替换为下划线。
6、在一种可能的实施方式中,在若常用颜色词汇表存在相同颜色,将第一图像对应文本数据集中的颜色词汇替换为下划线中,包括:若常用颜色词汇表不存在颜色词汇,则不对第一图像对应文本数据集进行改变。
7、在一种可能的实施方式中,还包括:
8、根据第一图像对应文本数据集定位对应图像位置寻找当前颜色词汇对应的目标,并对当前目标进行颜色识别;
9、将识别出的颜色替换掉下划线。
10、在一种可能的实施方式中,根据第一图像对应文本数据集定位对应图像位置寻找当前颜色词汇对应的目标,并对当前目标进行颜色识别中,采用groundingdino法寻找当前颜色词汇对应的目标。
11、在一种可能的实施方式中,在获取图像数据和图像对应文本数据,采用pnmix法进行数据增强,得到的第一图像数据集和第一图像对应文本数据集中,包括:
12、对参与混合的两个输入图像a和b进行标准化处理,并计算每个图像在每个像素位置上的均值和标准差;
13、将图像a的每个像素值调整为减去其平均值再除以其标准差后的结果,同时将图像b的像素值调整为减去其平均值再除以其标准差后的结果;
14、取图像a的标准化像素值乘以图像b的标准差再加上图像b的平均值,以及图像b的标准化像素值乘以图像a的标准差再加上图像a的平均值,并取平均,得到混合像素值,重复上述步骤,将所有产生的混合像素值组合,得到增强图像数据;
15、将所有增强图像数据集合,并将所有图像对应文本数据组合,得到第一图像数据集和第一图像对应文本数据集。
16、在一种可能的实施方式中,计算每个图像在每个像素位置上的标准差,具体的计算公式如下:
17、
18、其中,x表示输入的图像数据,b、c、h、w分别表示输入数据的batchsize、通道数、高度和宽度,σb,h,w表示在通道的维度上计算得到的标准差。
19、在一种可能的实施方式中,取图像a的像素值减去图像a关于位置的均值,再除以图像a关于位置的标准差。取图像b的像素值减去图像b关于位置的均值,再除以图像b关于位置的标准差包括:
20、
21、其中,a和b分别表示输入的两个图像下标,x表示输入的图像数据。
22、在一种可能的实施方式中,取图像a的标准化像素值乘以图像b的标准差再加上图像b的平均值,以及图像b的标准化像素值乘以图像a的标准差再加上图像a的平均值,并取平均,得到混合像素值包括:
23、
24、其中,xpnmix表示最终的pnmix增强图像,μa和μb是位置归一化算法得到的两个输入图像的均值图像。
25、在一种可能的实施方式中,本发明提供一种电子设备,包括处理器以及与处理器通信连接,且用于存储所述处理器可执行指令的存储器,所述处理器用于执行第一方面中所述的图像文本联合数据处理方法。
26、在一种可能的实施方式中,本发明提供一种计算机可读取存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现第一方面中所述的图像文本联合数据处理方法。
27、由上述技术方案可知,本发明的有益技术效果如下:
28、本发明提供一种图像文本联合数据处理方法、设备及介质,其中方法中,首先通过pnmix法对图像数据进行数据增强,得到第一图像数据集和第一图像对应文本数据集,并构建常用颜色词汇表,以此对第一图像对应文本数据集中的颜色词汇数据进行识别对比,如果当前被识别的颜色词汇包含于常用颜色词汇表,则剔除当前颜色词汇,由此设置,能够有效避免当采用pnmix法进行图像增强时,减少造成的颜色失真,通过颜色词汇表与当前颜色词汇相比较,能够有效的对图像增强后的颜色进行剔除,以此避免了由于pnmix法过后增强的图像有可能出现失真,而导致后续模型训练识别精度差的技术问题。
技术特征:1.一种图像文本联合数据处理方法,其特征在于,包括:
2.根据权利要求1所述的图像文本联合数据处理方法,其特征在于,在若常用颜色词汇表存在相同颜色,将第一图像对应文本数据集中的颜色词汇替换为下划线中,包括:若常用颜色词汇表不存在颜色词汇,则不对第一图像对应文本数据集进行改变。
3.根据权利要求2所述的图像文本联合数据处理方法,其特征在于,还包括:
4.根据权利要求3所述的图像文本联合数据处理方法,其特征在于,根据第一图像对应文本数据集定位对应图像位置寻找当前颜色词汇对应的目标,并对当前目标进行颜色识别中,采用groundingdino法寻找当前颜色词汇对应的目标。
5.根据权利要求1所述的图像文本联合数据处理方法,其特征在于,在获取图像数据和图像对应文本数据,采用pnmix法进行数据增强,得到的第一图像数据集和第一图像对应文本数据集中,包括:
6.根据权利要求5所述的图像文本联合数据处理方法,其特征在于,计算每个图像在每个像素位置上的标准差,具体的计算公式如下:
7.根据权利要求5所述的图像文本联合数据处理方法,其特征在于,取图像a的像素值减去图像a关于位置的均值,再除以图像a关于位置的标准差。取图像b的像素值减去图像b关于位置的均值,再除以图像b关于位置的标准差包括:
8.根据权利要求5所述的图像文本联合数据处理方法,其特征在于,取图像a的标准化像素值乘以图像b的标准差再加上图像b的平均值,以及图像b的标准化像素值乘以图像a的标准差再加上图像a的平均值,并取平均,得到混合像素值包括:
9.一种电子设备,包括处理器以及与处理器通信连接,且用于存储所述处理器可执行指令的存储器,其特征在于,所述处理器用于执行上述权利要求1-8任一所述的图像文本联合数据处理方法。
10.一种计算机可读取存储介质,存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1-8任一项所述的图像文本联合数据处理方法。
技术总结本发明提供一种图像文本联合数据处理方法、设备及介质,包括:获取图像数据和图像对应文本数据,采用pnmix法对图像进行数据增强,得到的第一图像数据集和第一图像对应文本数据集;构建常用颜色词汇表,识别第一图像对应文本数据集,将第一图像对应文本数据集中的颜色词汇与常用颜色词汇表中的颜色对比;若常用颜色词汇表存在相同颜色,将第一图像对应文本数据集中的颜色词汇替换为下划线。以解决现有技术中存在的在跨模态模型的数据训练过程中,由于图像数据与文本数据这两种模态具有不同的表达方式,使得图像的视觉特征在增强后而改变,使得图像与文本出现语义不一致,而导致后续训练的模型在实际应用中的精度下降的技术问题。技术研发人员:陈文杰,龚俞宁受保护的技术使用者:重庆电子工程职业学院技术研发日:技术公布日:2024/9/29本文地址:https://www.jishuxx.com/zhuanli/20241009/306529.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表