一种基于Kubernetes系统的多集群监控方法与流程
- 国知局
- 2024-10-09 15:11:39
本发明涉及系统服务,特别涉及一种基于kubernetes系统的多集群监控方法。
背景技术:
1、kubernetes系统,是用于管理云平台中多个主机上的容器化的应用,让部署容器化的应用简单且高效,提供了应用部署,规划,更新,维护的一种机制。
2、目前,在kubernetes系统中,获取pod单元相关信息主要有两种方法,一种是:使用kubectl命令行工具和kubernetes集群进行交互,来获取相关的资源信息,但该方法依赖于命令行环境,只能基于支持kubectl命令行的工具环境中运行,对于集群服务和集群服务之间的调用缺乏灵活性;并且受到权限的限制,kubectl的使用权限取决于用户的kubernetes配置,会受到权限管理的限制,最重要的是,命令行的查询是即时进行的,不支持实时监听kubernetes中资源的变化。另外一种方法是:通过在客户端编写代码来查询kubernetes的信息,以编写程序的方式和集群进行交互,但这种方法同意存在缺陷,例如在企业中多个服务都需要查询kubernetes系统资源信息时,每一个集群服务都将需要编写一套相关的程序代码,不仅增加了工作的复杂性,同样也需要很多kubernetes集群的认证和授权。
3、因此,本发明提出一种基于kubernetes系统的多集群监控方法。
技术实现思路
1、为解决上述技术问题,本发明提供一种基于kubernetes系统的多集群监控方法,用以解决传统技术中集群服务之间交互不便,无法实时监测pod单元资源状态情况的问题。
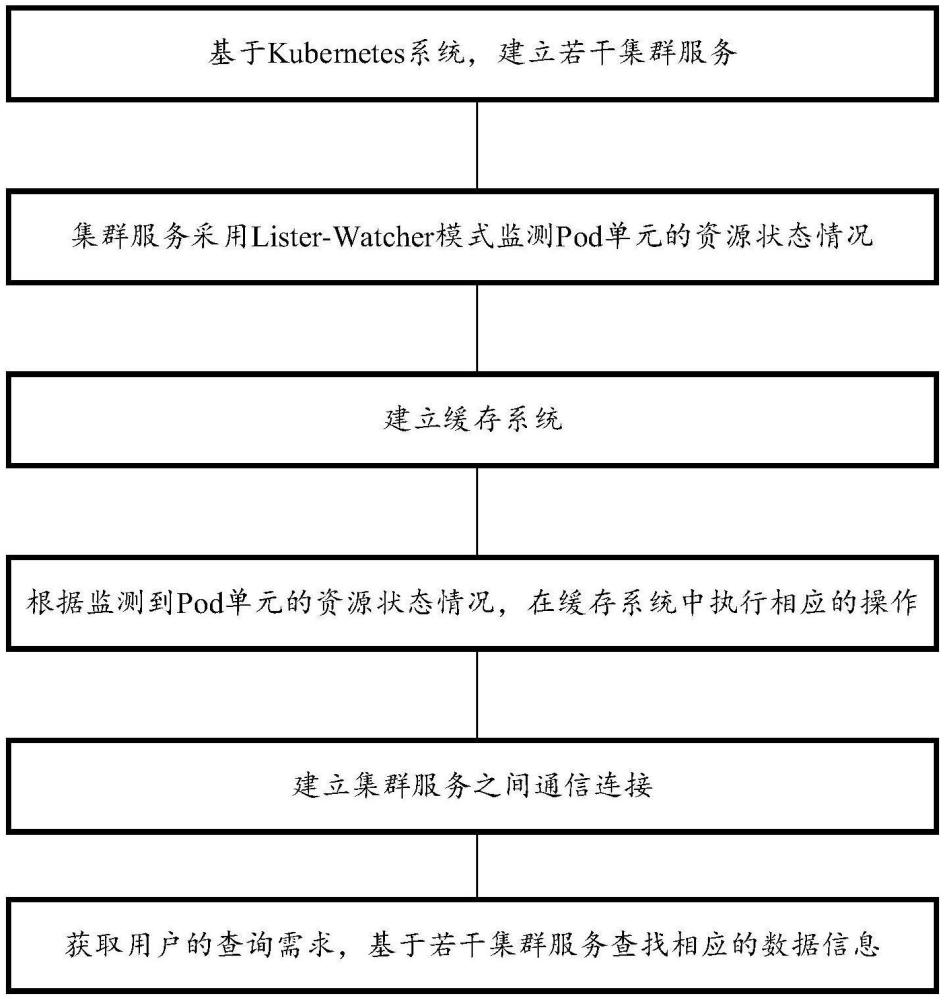
2、本发明实施例中提供了一种基于kubernetes系统的多集群监控方法,包括:
3、基于kubernetes系统,建立若干集群服务;
4、所述集群服务采用lister-watcher模式监测pod单元的资源状态情况;
5、建立缓存系统;
6、根据监测到pod单元的资源状态情况,在缓存系统中执行相应的操作;
7、建立所述集群服务之间通信连接;
8、获取用户的查询需求,基于若干集群服务查找相应的数据信息。
9、优选的,本发明提供一种基于kubernetes系统的多集群监控方法,
10、kubernetes系统,包括控制节点和若干分布节点;所述控制节点,用于管理kubernetes系统的资源状态和节点配置;所述分布节点,用于管理相应的pod单元;
11、所述控制节点,包括:kubernetes api服务器、系统控制器和节点调度器;所述kubernetes api服务器,用于提供api接口供分布节点与控制节点之间的数据交互;所述系统控制器,用于监测系统内所有分布节点的资源状态,并执行相应的节点配置操作;所述节点调度器,用于向所述分布节点调度相应的应用程序;
12、所述分布节点,包括:节点控制器、运行控制器和代理服务器;所述节点控制器,用于与所述控制节点建立通信连接,获取相应的应用程序;所述运行控制器,用于运行所述应用程序,对管理的pod单元执行相应的操作;所述代理服务器,用于分布节点之间进行通信。
13、优选的,本发明提供一种基于kubernetes系统的多集群监控方法,所述步骤:基于kubernetes系统,建立若干集群服务,之后还包括:
14、初始化集群服务;
15、获取任务事件,分析所有集群服务的工作性能,选择集群服务,用于处理所述任务事件;包括:
16、获取所述任务事件的处理时间周期t;
17、在处理时间周期t=[t1,…,ts]内获取所有集群服务的工作性能;包括:
18、构建所述集群服务的评估矩阵;设第i个集群服务在tj时刻的工作性能为pi(tj);
19、pi(tj)=αmi(tj)i∈[1,n],j∈[1,s]
20、其中,α为权重影响矩阵,mi(t)为对第i个集群服务在tj时刻进行工作性能评估的函数;
21、
22、其中,分别为影响集群服务mi(t)工作性能的网卡状态、接口状态、通道状态、进程状态、集群服务之间的连接状态关于tj时刻的抽象模型,设共有n个集群服务;
23、构建在tj时刻所有集群服务的工作性能评估矩阵
24、p(tj)=[p1(tj),…,pn(tj)];进一步根据处理时间周期t,构建所有集群服务关于所述任务事件的评估矩阵组p=[p(t1),…,p(tn)];
25、随机选择所述评估矩阵组中的任一工作性能矩阵进行关于集群服务的工作性能寻优,获取tj时刻对于任务事件的最优集群服务;
26、以tj时刻对于任务事件的最优集群服务的工作性能评估值,作为标准阈值,在所述评估矩阵组中的每个工作性能评估矩阵进行遍历寻找关于处理时间周期t的最优处理时刻的最优集群服务spi(tj);
27、根据获取的最优处理时刻的最优集群服务spi(tj),基于tj时刻将所述任务事件加载到相应的最优集群服务spi(tj)的进程状态中;在tj时刻调用spi(tj)处理所述任务事件。
28、优选的,本发明提供一种基于kubernetes系统的多集群监控方法,
29、所述lister-watcher模式,通过lister单元和watcher单元来实现;
30、所述lister单元,用于监测所述pod单元中特定资源的状态和数据;
31、所述watcher单元,用于监测所述pod单元中所有资源的变换状态。
32、优选的,本发明提供一种基于kubernetes系统的多集群监控方法,所述步骤:所述集群服务采用lister-watcher模式监测pod单元的资源状态情况,包括:
33、采用lister-watcher模式,初始化监听器;
34、所述监听器按照预设时间周期从kubernetes api服务器读取所述pod单元的资源状态情况;包括:
35、当有新的pod单元接入所述kubernetes api服务器时,通过读取函数读取pod单元中的数据信息;
36、当所述pod单元中的数据信息更新时,通过更新函数对比,获取所述pod单元中的数据更新信息。
37、优选的,本发明提供一种基于kubernetes系统的多集群监控方法,所述步骤:建立缓存系统,包括:
38、获取pod单元的ip地址,作为所述pod单元的索引标识;
39、根据所述索引标识,建立相应的缓存模块,存储所述pod单元的数据信息;包括:
40、所述缓存模块采用三级缓存架构,分别构建l1级缓存、l2级缓存和l3级缓存;
41、获取pod单元的历史数据信息和历史查询请求;
42、将所述历史数据信息按照l1级缓存、l2级缓存、l3级缓存的存储空间随机在缓存模块中存储;
43、按照历史查询请求,向所述缓存模块中的数据信息发出检索请求,获取历史查询请求对应的历史数据信息在l1级缓存、l2级缓存、l3级缓存中的命中率和查询时间;
44、根据命中率和查询时间,对缓存模块中的历史数据信息基于l1级缓存、l2级缓存、l3级缓存进行存储调整,重复上述步骤,直至获取的命中率和查询时间的损失函数满足阈值要求,将缓存模块中l1级缓存、l2级缓存所存储的历史数据信息进行信息类型识别,分别标记为l1类型数据和l2类型数据;
45、
46、其中,l为损失函数,a为历史数据信息,βa1为在第a条历史数据信息中实际命中率rha与预估命中率pha的偏差对损失函数的影响权重系数,βa2为在第a条历史数据信息中实际查询时间rta与预估查询时间pta的偏差对损失函数的影响权重系数,δ0为损失函数校正项;
47、在缓存模块接收到所述数据信息时,进行信息类型识别,将l1类型数据的数据信息存储于缓存模块中的l1级缓存,将l2类型数据的数据信息存储于缓存模块中的l2级缓存,将所述数据信息中的除l1类型数据、l2类型数据的数据信息存储于l3级缓存中;
48、所述pod单元与所述索引标识、所述缓存模块一一对应。
49、优选的,本发明提供一种基于kubernetes系统的多集群监控方法,所述步骤:根据监测到pod单元的资源状态情况,在缓存系统中执行相应的操作,包括:
50、当有新的pod单元接入所述kubernetes api服务器时,通过读取函数读取pod单元中的数据信息,获取数据信息中pod单元的ip地址,在所述缓存系统中建立索引标识,并将所述数据信息存储至相应的缓存模块;
51、当所述pod单元中的数据信息更新时,通过更新函数对比,获取所述pod单元中的数据更新信息,在所述缓存系统中根据数据更新信息中的ip地址,更新索引标识,并将所述数据更新信息存储至缓存模块;
52、当所述pod单元销毁时,将所述缓存系统中相应的索引标识和缓存模块中的数据信息删除;
53、当所述pod单元的ip地址变更时,在所述缓存系统中更新索引标识,并建立更新后索引标识与所述pod单元对应的缓存模块的对应关系。
54、优选的,本发明提供一种基于kubernetes系统的多集群监控方法,所述步骤:获取用户的查询需求,根据若干集群服务查找相应的数据信息,包括:
55、获取查询需求;
56、检测所述查询需求中是否包含相应的ip查询地址,当检测到ip查询地址时,转换为相应的查询索引;
57、基于当前集群服务,根据所述查询索引,在所述缓存系统中匹配相应的索引标识,获取对应的数据信息;若在当前集群服务中未匹配到相应的索引标识,则通过集群服务间的通信连接,进行跨集群的索引标识匹配,获取相应的数据信息;
58、当检测到所述查询需求中未包含相应的ip查询地址时,则提取所述查询需求中的关键信息,进行跨集群信息检索,获取相应的数据信息。
59、优选的,本发明提供一种基于kubernetes系统的多集群监控方法,所述步骤:当检测到所述查询需求中未包含相应的ip查询地址时,则提取所述查询需求中的关键信息,进行跨集群信息检索,获取相应的数据信息,包括:
60、分析所述查询需求,判断所述查询需求是否包含符合信息检索的信息要素;
61、当所述查询需求包含符合信息检索的信息要素时,基于所述查询需求进行要素提取,获取相应的信息要素;
62、对所述信息要素进行属性分析,将所述信息要素按照检索属性进行分类,判断每个检索属性下信息要素的语义丰富程度,选择语义丰富程度最高的检索属性下的信息要素作为关键信息,生成相应的查询索引;
63、根据获取的语义丰富程度最高的检索属性,建立标准查询索引;
64、计算所述标准查询索引与多集群服务中的数据信息的余弦相似度;
65、θ0,i=cos(l0,li)
66、其中,θ0,i为标准查询索引l0与第i个集群服务的数据信息li的余弦相似度;
67、将获取的余弦相似度作为相应集群服务的数据信息的权重影响因子;
68、遍历计算所述查询索引与每个集群服务中数据信息的离散度;
69、
70、其中,d(l01|li)为查询索引l01与第i个集群服务的数据信息li的离散度;
71、获取与所述查询索引离散度最低的集群服务的数据信息,分析离散度是否满足检索标准,当满足所述检索标准时,将检索到的数据信息向用户显示;
72、所述信息要素,包括pod单元名称、pod单元命名空间、pod单元注册信息以及pod单元标签信息。
73、与传统技术相比,本发明提出的一种基于kubernetes系统的多集群监控方法的有益效果在于:通过建立若干集群服务,采用lister-watcher模式实现了对pod单元的资源状态情况的监测,并在缓存系统中执行相应的操作;在获取到用户的查询需求时,通过集群服务之间的通信连接,实现了对相应数据信息的获取;与传统技术相比,上述方法无需依赖命令行环境,建立了集群服务与集群服务之间的通信连接,实现了数据信息的一致性和调用的灵活性,并且采用lister-watcher模式,实现了集群服务对pod单元的实时监测,无需对用户和集群进行授权管理,解决了传统技术中依赖于编写程序进行集群服务间交互的不便,有效地提高了对kubernetes系统中pod单元监测的即时性,实现了多集群服务的数据信息同步。
74、本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
75、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
本文地址:https://www.jishuxx.com/zhuanli/20241009/308007.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表