一种基于模糊强化学习的交叉口交通信号控制方法与流程
- 国知局
- 2024-10-09 15:16:49
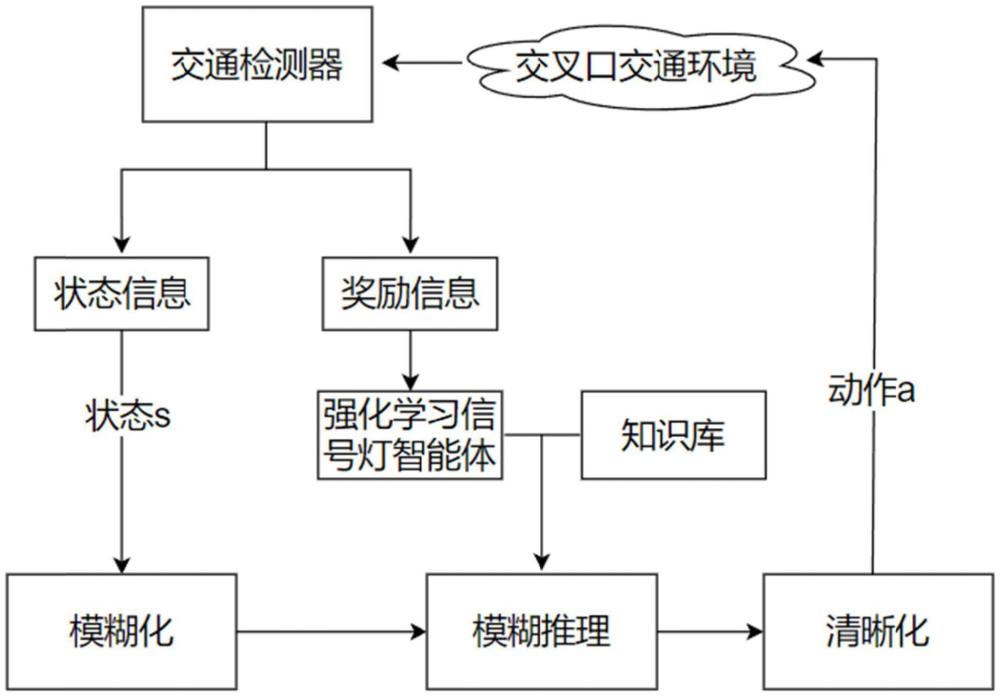
本发明涉及交通信号控制,具体涉及一种基于模糊强化学习的交叉口交通信号控制方法。
背景技术:
1、随着汽车的普及,交通拥堵仍是社会亟待解决的严重交通问题。
2、目前在交通信号控制领域,基本上是采用多种检测技术,即通过建立数学模型,然后根据当前车辆到达情况来预测下一时段车辆到达情况,加以配置多种控制配时方案。虽然该方法相比于定时控制,控制效率有所提高,但是面对复杂的、不确定性因素多的城市交通场景,控制效果仍不理想,依然存在交叉口车辆等待时间过长的问题。
3、现有技术中试图通过强化学习模型来解决上述问题,但面临模型难以收敛、不稳定的问题,即学习过程非常缓慢或在某些情况下无法达到最优解。
技术实现思路
1、为了解决上述技术问题,本发明提供了一种基于模糊强化学习的交叉口交通信号控制方法,所述方法包括:
2、通过设置车辆状态变量、信号灯动作变量以及奖励函数来构建强化学习信号灯智能体;
3、输入到达交叉口的车辆状态数据,并执行模糊推理策略选择输出信号灯动作;
4、得到新的所述车辆状态数据和当前奖励值,并将数据放入经验回放池;
5、待所述经验回放池的数据达到一定容量,抽取一批数据进行训练直至达到停止条件;
6、使用训练好的所述强化学习信号灯智能体进行所述交叉口的交通信号控制。
7、进一步的,所述通过设置车辆状态变量、信号灯动作变量以及奖励函数来构建强化学习信号灯智能体,包括:
8、在所述交叉口的各车道设置检测点以检测到达所述交叉口的各车道的车辆状态数据;
9、将检测到的所述车辆状态数据发送给信号灯的模糊控制器,所述模糊控制器控制每个相位的时长策略。
10、进一步的,所述车辆状态变量:包括定义当前绿灯相位的车辆到达率为q1、下一相位的车辆到达率为q2,将所述q1和q2输入到所述模糊控制器进行模糊化处理;
11、所述信号灯动作变量:包括定义当前绿灯相位延长时间g,将所述g输入到所述模糊控制器进行模糊化处理;
12、采用三角形隶属度函数将所述车辆到达率的论域和所述绿灯相位延长时间的论域分别分为5个模糊子集,并定义所述三角形隶属度函数的关键三个点为a、b、c,其中,b是函数顶点、且表示隶属度为1,a和c是函数的两端点、且在a和c两点之外表示隶属度为0,所述三角形隶属度函数的表达式是:
13、
14、其中,x为输入变量。
15、进一步的,所述执行模糊推理策略选择输出信号灯动作,包括:
16、利用当前绿灯相位的车辆到达率、下一相位的车辆到达率和当前绿灯相位延长时间来建立模糊规则表,用于完成所述车辆状态变量输入到所述信号灯动作变量输出的映射。
17、进一步的,采用重心法实现去模糊化处理以用于将输出的所述信号灯动作变量转换为具体的绿灯延长时间的数值,所述重心法的具体计算公式是:
18、
19、其中,u'是对应绿灯延长时间的精确输出值,ui是触发第i个模糊规则的隶属函数的中心值,xi为被触发第i条规则的所有输入变量的隶属度的乘积,i为触发模糊规则的个数。
20、进一步的,所述方法还包括:
21、输出动作到所述模糊控制器中,交叉口通过所述奖励函数产生所述奖励值反馈到所述强化学习信号灯智能体;
22、所述强化学习信号灯智能体根据当前交叉口的车辆状态、执行的信号灯动作和环境反馈的所述奖励值进行学习更新,并执行模糊推理策略选择输出信号灯动作。
23、进一步的,所述奖励函数的表达式是:
24、r=β1r1+β2r2
25、其中,β1、β2为奖励函数的权重、且权重之和为1,r1为所述交叉口的各车道车辆排队的总长度,r2为当前车辆的等待时间之和。
26、进一步的,所述停止条件包括达到最大迭代次数或学习收敛。
27、与现有技术相比,本发明具有如下有益效果:
28、本发明通过获取交叉口的车辆状态信息,将交叉口的信号灯作为强化学习的智能体,并将强化学习中的车辆状态矢量作为模糊控制器的输入变量,通过经验回放池得到模糊规则输出部分为强化学习的信号灯动作空间,与交叉口的交通环境实现交互,获得奖励值,不断迭代训练,使得交叉口的车流得到最佳的调度,道路的通行效率实现最优。这种方法克服了强化学习模型训练难以收敛不稳定的弊端,解决了交叉口车辆等待时间过长的问题。
技术特征:1.一种基于模糊强化学习的交叉口交通信号控制方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于模糊强化学习的交叉口交通信号控制方法,其特征在于,所述通过设置车辆状态变量、信号灯动作变量以及奖励函数来构建强化学习信号灯智能体,包括:
3.根据权利要求2所述的基于模糊强化学习的交叉口交通信号控制方法,其特征在于,
4.根据权利要求3所述的基于模糊强化学习的交叉口交通信号控制方法,其特征在于,所述执行模糊推理策略选择输出信号灯动作,包括:
5.根据权利要求4所述的基于模糊强化学习的交叉口交通信号控制方法,其特征在于,采用重心法实现去模糊化处理以用于将输出的所述信号灯动作变量转换为具体的绿灯延长时间的数值,所述重心法的具体计算公式是:
6.根据权利要求2所述的基于模糊强化学习的交叉口交通信号控制方法,其特征在于,所述方法还包括:
7.根据权利要求1所述的基于模糊强化学习的交叉口交通信号控制方法,其特征在于,所述奖励函数的表达式是:
8.根据权利要求1所述的基于模糊强化学习的交叉口交通信号控制方法,其特征在于,所述停止条件包括达到最大迭代次数或学习收敛。
技术总结本发明公开一种基于模糊强化学习的交叉口交通信号控制方法,所述方法包括通过设置车辆状态变量、信号灯动作变量以及奖励函数来构建强化学习信号灯智能体;输入到达交叉口的车辆状态数据,并执行模糊推理策略选择输出信号灯动作;得到新的所述车辆状态数据和当前奖励值,并将数据放入经验回放池;待所述经验回放池的数据达到一定容量,抽取一批数据进行训练直至达到停止条件;使用训练好的所述强化学习信号灯智能体进行所述交叉口的交通信号控制。该方法克服了强化学习模型训练难以收敛不稳定的弊端,解决了交叉口车辆等待时间过长的问题。技术研发人员:宋志洪,罗毅东,陈家旭,苟启文,徐亮受保护的技术使用者:安徽科力信息产业有限责任公司技术研发日:技术公布日:2024/9/29本文地址:https://www.jishuxx.com/zhuanli/20241009/308185.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表