一种模型市场环境下基于集成提升的单轮联邦学习方法
- 国知局
- 2024-10-09 15:22:01
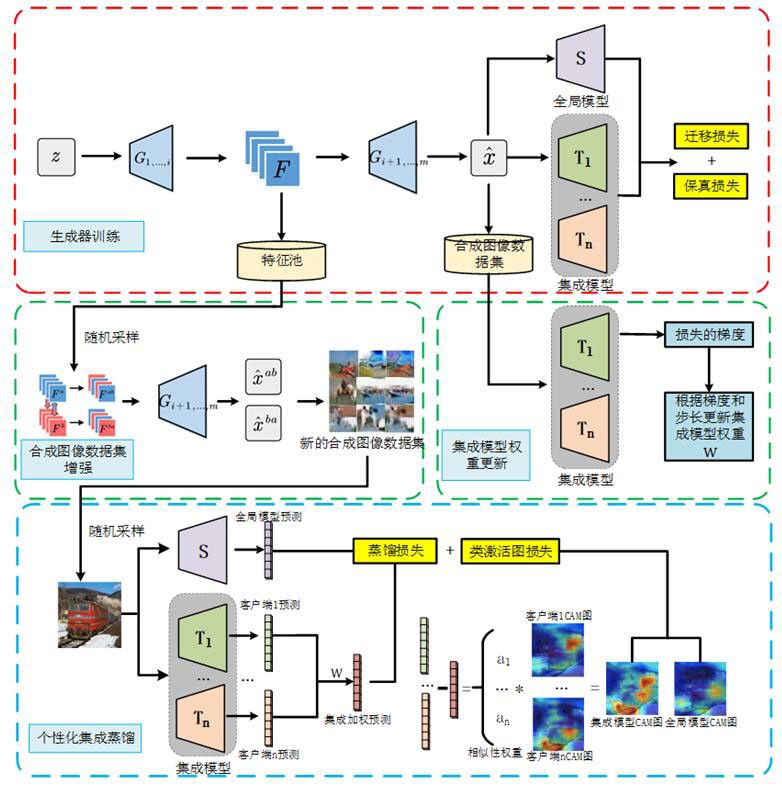
本发明涉及异构数据下的单轮联邦学习,尤其涉及一种模型市场环境下基于图像数据和集成提升的单轮联邦学习方法。
背景技术:
1、为了满足日益增长的机器学习和人工智能应用需求,同时提高资源的有效利用率,模型市场已经成为了科技前沿中的一个焦点领域。在模型市场中,模型消费者无需从零开始构建模型,这大大节省了模型消费者的时间和成本。
2、然而,在模型市场领域中,潜在的训练数据散布于全球范围内的多个数据提供者中,模型开发者需要收集这些图像数据来开发模型,这导致高昂的通信开销。因此,如何降低通信开销成为模型市场一个挑战。
3、此外,模型开发者集中处理图像数据的方式不可避免地会与日益严格的数据隐私保护法规发生冲突,尤其是当数据涉及敏感信息时,比如个人身份信息和健康记录等。因此,如何确保数据隐私成为模型市场的另一个挑战。为了应对这两种挑战并促进模型市场的发展,急需找到一种解决方案,能够在确保低通信开销以及数据隐私的同时,有效利用分散的图像数据资源。
4、为了应对上述的两个挑战,单轮联邦学习被引入作为一种革新的解决方案。单轮联邦学习是指在保护隐私的前提下多个客户端仅仅通过客户端到服务器端的一轮通信实现协作训练一个全局模型,这种方法不仅继承了传统联邦学习的核心优势,即保护图像数据隐私和利用分布式图像数据,它还特别针对减少通信开销进行了优化,成为模型市场对抗数据隐私、安全性问题以及高通信开销挑战的有效策略。
5、然而虽然单轮联邦学习目前受到广泛认可,但是它仍然面临着诸多挑战。例如,客户端之间存在计算能力、存储容量、通信带宽等方面的差异,这将导致客户端往往有不同的模型结构,在这种情况下,简单平均客户端模型的操作不再有效。
6、除了模型结构的差异,在单轮联邦学习中,多个客户端模型仅根据每个节点的一次更新进行服务器端的聚合,这样的步骤限制了模型优化的深度和广度,因为每个节点的训练图像数据可能只覆盖了总数据集的一小部分,这可能导致聚合后的全局模型无法达到理想的泛化能力,尤其是在客户端的数据分布存在显著差异的情况下。
技术实现思路
1、为了应对上述挑战,本发明提供了一种模型市场环境下基于数据和集成提升的单轮联邦学习方法,可以解决单轮联邦学习在模型异构的场景下,全局模型相较于在多轮联邦学习框架下训练的全局模型性能差的问题。本发明还公开了一种个性化加权的类激活图指导全局模型训练的方案,用于缓解单轮联邦学习中客户端的数据分布存在显著差异对全局模型性能的影响。
2、本发明提供了一种模型市场环境下基于集成提升的单轮联邦学习方法,包括以下步骤:
3、s1、客户根据自身计算资源和存储能力选择适合本地模型结构。
4、s2、客户端将更新后的本地模型上传至中央服务器。
5、s3、服务器接收到客户端上传的模型参数后,并将多个模型组成集成模型,其中默认集成权重为平均值。
6、s4、从高斯分布和均匀分布中采样得到高斯噪声和标签,将生成器高斯噪声和标签输入生成器得到合成图像数据,服务器利用集成模型和全局模型对合成图像数据的模型输出构建保真损失函数和迁移损失函数来训练生成器,如果本轮轮次不为第一轮,集成模型的集成权重是上一轮的集成权重。
7、s5、将生成器生成的合成图像数据及生成器中间层输出的特征分别存入合成图像数据集和特征池。
8、s6、根据集成模型对合成图像数据集的模型输出来构建交叉熵损失寻找使损失最小的集成权重,即使用梯度方向和固定步长更新集成权重。
9、s7、对特征池进行随机采样,并将采样结果输入生成器指定层获得多样性的新合成图像数据输出,并将其填充新的合成图像数据集。
10、s8、在获得新的合成图像数据集和新的集成权重之后,将新的合成图像数据输入集成模型和输入全局模型得到集成模型输出和全局模型输出。通过构建两个输出之间的蒸馏损失来更新全局模型,从而实现集成模型到全局模型知识的传输。
11、s9、重复s4到s8到指定轮次。
12、本发明与现有技术相比,其有益效果主要体现在以下几个方面:
13、本发明提出了一种基于图像数据和集成提升单轮联邦学习的方法,该方法通过保真和迁移损失生产出位于全局模型和集成模型决策边界之间的合成图像数据来加速集成蒸馏,为了防止生成的图像数据数量有限,以及通过多轮训练图像数据的多样性不足,本发明通过生成器特征通道混合来增加合成图像数据的数量和多样性。
14、此外,本发明使用合成图像数据集来更新集成模型权重的方法,全局模型的性能上界是集成模型的性能,通过训练权重的方式来提升集成模型的性能,极大提高了集成模型性能的上限,进而提高蒸馏过的全局模型的性能。此外,由于集成模型的性能提高,并且生成器的训练的保真损失中主要参照的是集成模型的输出,这可以进而提升合成图像数据的质量。
15、本发明还提出了一种个性化加权的类激活图指导全局模型训练的方法。该方法的一方面,因为类激活图本质上是全连接层权重矩阵和卷积层输出的特征图集合相乘得到的一张与训练图像相同大小的特征图,所以基于梯度的类激活图技术可以有效解决了无法对齐集成模型中异构客户模型之间中间特征的问题。另一方面,由于客户端存在数据异构的问题,导致不同客户端对相同图像数据的决策能力相差过大,本发明计算每个客户端输出和集成模型输出相似程度来加权得到类激活图,进而缓解了客户端数据异构的问题。
技术特征:1.一种模型市场环境下基于集成提升的单轮联邦学习方法,包括以下步骤:
2.根据权利要求1所述的一种模型市场环境下基于集成提升的单轮联邦学习方法,其特征在于,所述集成模型定义如下:
3.根据权利要求1所述的一种模型市场环境下基于集成提升的单轮联邦学习方法,其特征在于,
4.根据权利要求1所述的一种针对模型市场基于数据和集成提升的单轮联邦学习方法,其特征在于,在得到每批合成图像数据后,使用交叉熵损失函数对集成模型的集成权重梯度方向和固定步长μ每次更新集成权重w。
5.根据权利要求4所述的一种针对模型市场基于数据和集成提升的单轮联邦学习方法,其特征在于,所述交叉熵损失函如下所示:
6.根据权利要求1所述的一种模型市场环境下基于集成提升的单轮联邦学习方法,其特征在于,在填充特征池f之后,从特征池f进行随机采样,并将采样结果输入生成器指定层获得多样性的新合成图像数据xs*,并将其填充新的合成数据集
7.根据权利要求6所述的一种模型市场环境下基于集成提升的单轮联邦学习方法,其特征在于,利用集成模型输出和全局模型输出之间的蒸馏损失来更新全局模型,蒸馏损失如下所示:
8.根据权利要求1所述的一种模型市场环境下基于集成提升的单轮联邦学习方法,其特征在于,步骤s8替换为如下操作:
9.根据权利要求8所述的一种模型市场环境下基于集成提升的单轮联邦学习方法,其特征在于,计算客户模型的输出和集成模型输出相似程度公式如下:
10.根据权利要求8所述的一种模型市场环境下基于集成提升的单轮联邦学习方法,其特征在于,所述类激活图损失如下所示:
技术总结本发明公开了一种模型市场环境下基于集成提升的单轮联邦学习方法。本发明利用加权的集成模型以及生成器通道混合来提升合成图像数据的质量,然后利用合成图像数据调整集成权重。利用这种发法可以提升集成模型的性能,进而提升全局模型的性能。此外,由于模型市场下数据提供者数据异构会影响全局模型的训练,本发明根据集成模型与数据提供者模型输出的差异来加权每个数据提供者模型的类激活图,并使用该图指导全局模型。利用这种方法可以很好缓解对合成图像数据决策能力差的数据提供者对集成蒸馏效果的影响。技术研发人员:赵帅,畅龙涛,任思琪受保护的技术使用者:浙江工商大学技术研发日:技术公布日:2024/9/29本文地址:https://www.jishuxx.com/zhuanli/20241009/308516.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表