一种基于语义计划指导的重排序多模态摘要生成方法
- 国知局
- 2024-10-09 15:26:25
本发明涉及自然语言处理领域中的多模态摘要任务,具体地涉及一种基于语义计划指导的重排序多模态摘要生成方法。
背景技术:
1、在当今数字时代,人们通过社交媒体、新闻网站、短视频平台等渠道获取信息。这些信息不仅包括文本,还涉及大量的图像、音频和视频等多媒体内容。这些多模态数据能够以更直观、生动和丰富的方式传递信息,提供更全面和真实的观察和体验。然而,面对海量的多模态数据,读者或用户常常需要花费大量时间和精力来理解和获取关键信息。为了解决这一问题,研究者开始关注如何利用多模态数据生成简洁、准确和有吸引力的摘要。通过多模态摘要任务,研究人员和从业者希望能够综合利用文本、图像、音频等多模态数据的信息,以更全面、准确和丰富的方式生成摘要,为用户提供更好的信息呈现和阅读体验。因此,有必要设计一种基于语义计划指导的重排序多模态摘要生成方法。
技术实现思路
1、为了克服现有多模态摘要技术忽略了对语义指导和摘要重排序技术的探索,本发明提出了一种基于语义计划指导的重排序多模态摘要生成方法,包括:
2、一种一种基于语义计划指导的重排序多模态摘要生成方法,所述基于语义计划指导的重排序多模态摘要生成方法包括如下步骤:
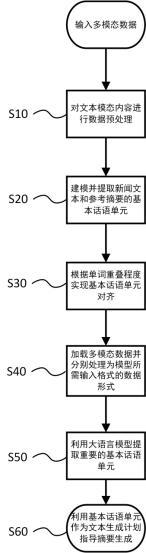
3、步骤1:对新闻多模态数据集中的文本模态内容进行数据预处理;
4、步骤2:建模并提取新闻多模态数据集中的原始新闻文本和参考摘要的基本话语单元;
5、步骤3:根据原始文本和参考摘要间的基本话语单元的单词重叠程度实现基本话语单元对齐;
6、步骤4:加载多模态数据并分别处理为模型所需输入格式的数据形式;
7、步骤5:利用大语言模型bart结合复制机制提取重要的基本话语单元作为文本生成计划;
8、步骤6:利用提取的基本话语单元作为文本生成计划指导摘要生成。
9、根据一个优选的实施方式,步骤1还包括:
10、对新闻文本使用spacy进行分词、词形还原和词性标注等数据预处理,然后对每个句子划分(用于基本话语单元提取)进行处理,将划分的单词与对应的原句子的单词进行比较,并根据情况进行调整。具体调整方式包括:
11、如果划分的单词与原句子的单词完全匹配,则不做任何调整;
12、如果划分的单词是原句子的单词的一部分,则将划分的单词替换为原句子的单词,并在划分的单词后插入剩余的部分;
13、如果原句子的单词是划分的单词的一部分,则将原句子的单词替换为划分的单词,并在原句子的单词后插入剩余的部分;
14、最后将预处理后的文档划分数据保存到指定目录中用于提取基本话语单元。
15、根据一个优选的实施方式,步骤2还包括:
16、首先利用从其他大型数据集上经过很好训练的elmo词表示模型用于编码文本进而捕获有用的特征信息,将文本句子中的所有单词嵌入为词向量,然后将词向量输入到bilstm模型中用于建模文本上下午序列关系,将bilstm建模得到的前向和后向隐藏层状态进行连接输入crf统计模型中用于计算每个句子中每个单词作为基本话语单元开始的条件概率,搜索并选择最大条件概率的单词对原始句子进行划为基本话语单元。
17、根据一个优选的实施方式,步骤3还包括:
18、计算原始文本和参考摘要间基本话语单元的rouge分数相似性矩阵;通过使用贪婪算法来选择原始文本中与参考摘要最相关的基本话语单元,迭代地选择与当前参考摘要基本话语单元集合产生最高rouge-1和rouge-2分数的基本话语单元,并将其视为重要基本话语单元,作为文本生成计划的参考标签。
19、根据一个优选的实施方式,步骤4还包括:
20、读取语义分割后得到的文本基本话语单元文件,使用基本话语单元并结合开始token标记<cls>和分隔token标记<sep>重新构建原始句子,得到由基本话语单元为元素的句子,将文本按照空格等分隔符分割成单词,再使用bpe算法,将常见的字符序列逐步合并为子词,形成一个子词词表;添加起始符、分隔符和结束符,为文本序列添加特殊标记以供模型识别;将分割后的单词或子词转换为对应的编码表示,通常是一个整数;
21、读取图像数据,然后转换为rgb红、绿和蓝三个颜色模式,再将图像按照其宽度和高度的较小值进行等比例缩放大小调整为256x256的像素尺寸,从图像中心进行裁剪保留图像中心区域;图像转换为pytorch tensor对象;对图像进行标准化处理,将图像的每个通道进行减均值除以标准差的操作,以使图像的像素值在均值为0、标准差为1的范围内。
22、根据一个优选的实施方式,步骤5还包括:
23、将分词后的基本话语单元文本数据添加可学习的位置嵌入,以指示其在文档中的位置;然后使用一个预先训练好的bart编码器进行编码获取文本语义和语法信息特征,提取每个基本话语单元编码后的隐藏状态,将平均池化应用在话语单元中每个单词的编码特征上(包括开始令牌和停止令牌),将池化后的特征与结束输入标记的嵌入连接起来;输入到bart解码器中提取出解码器隐藏状态;处理后的图像输入到vision transformer中进行图像块的嵌入获取到图像的编码特征;
24、然后使用跨模态注意力机制(cmha)将文本和图像的信息进行交互和融合,从图像中提取有用的上下文信息,再输入到多层感知机中进行dropout操作,通过线性层进行映射,接着应用tanh激活函数,再次进行dropout操作,最后通过线性层得到文本中每个基本话语单元的概率分布,然后选取前k个概率值最大的基本话语单元作为文本生成计划。
25、根据一个优选的实施方式,步骤6还包括:
26、利用提取的基本话语单元作为文本生成计划指导摘要生成:将原始的文本内容替换为提取的基本话语单元,然后进行抽象摘要得到最终的摘要结果;
27、将提取的基本话语单元使用bart编码器进行编码获取特征,再次使用跨模态注意力机制(cmha)提取文本与图像相关信息,输入到bart模型的解码器中,首先使用多头自注意力机制对当前输入进行编码,以捕捉输入序列内部的依赖关系,通过逐步生成目标序列的每个token来完成生成过程;
28、在每个时间步,解码器会预测下一个单词的概率分布,并根据该分布结合束搜索策略选择对下一个令牌进行采样或选择概率最高的令牌作为生成结果。
29、本发明的有益效果:
30、通过学习提取重要基本话语单元作为关键语义信息进而指导摘要生成,使得模型能够关注到多模态数据中的核心信息,进而生成准确的摘要结果;
31、使用跨模态注意力将文本和图像的信息交互和融合,充分利用多模态数据提供丰富的上下文信息,同时通过对重要基本话语单元进行重排序再摘要,提高摘要的精炼度和一致性,减少生成时间和资源消耗,并增加生成摘要的多样性,有助于提高摘要生成的效率和质量。
技术特征:1.基于语义计划指导的重排序多模态摘要生成方法,其特征在于,包括:
2.如权利要求1所述的基于语义计划指导的重排序多模态摘要生成方法,其特征在于,步骤1包括:
3.如权利要求1所述的基于语义计划指导的重排序多模态摘要生成方法,其特征在于,步骤2包括:
4.如权利要求1所述的基于语义计划指导的重排序多模态摘要生成方法,其特征在于,步骤3包括:
5.如权利要求1所述的基于语义计划指导的重排序多模态摘要生成方法,其特征在于,步骤4包括:
6.如权利要求1所述的基于语义计划指导的重排序多模态摘要生成方法,其特征在于,步骤5包括:
7.如权利要求1所述的基于语义计划指导的重排序多模态摘要生成方法,其特征在于,步骤6包括:
技术总结本发明公开了一种基于语义计划指导的重排序多模态摘要生成方法,涉及自然语言处理领域中的多模态摘要任务,包括:对新闻多模态数据集中的文本模态内容进行数据预处理;建模并提取新闻多模态数据集中的原始新闻文本和参考摘要的基本话语单元;根据原始文本和参考摘要间的基本话语单元的单词重叠程度实现基本话语单元对齐;加载多模态数据并分别处理为模型所需输入格式的数据形式;利用大语言模型BART结合复制机制提取重要的基本话语单元作为文本生成计划;利用提取的基本话语单元作为文本生成计划指导摘要生成。本发明通过提取基本话语单元作为关键语义信息指导多模态摘要生成,生成简洁、准确、丰富和多样化的摘要,方便用户快速获取关键信息、节省阅读时间,帮助用户更准确地搜索和获取感兴趣的新闻内容。技术研发人员:邓川鹏,赵旭剑受保护的技术使用者:西南科技大学技术研发日:技术公布日:2024/9/29本文地址:https://www.jishuxx.com/zhuanli/20241009/308743.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。