一种多芯粒并行仿真同步的方法
- 国知局
- 2024-10-15 10:24:02
本发明涉及并行仿真领域,尤其涉及一种多芯粒并行仿真同步的方法。
背景技术:
1、目前主流的cpu并行仿真器有gem5(binkert, n., beckmann, b., black, g.,reinhardt, s.k., saidi, a., basu, a., et al.:the gem5 simulator. sigarchcomput. archit. news 39(2), 1–7 (aug 2011))和sniper(trevor e. carlson, wimheirman, and lieven eeckhout. 2011. sniper: exploring the level ofabstraction for scalable and accurate parallel multi-core simulation. inproceedings of 2011 international conference for high performance computing,networking, storage and analysis (sc '11). association for computingmachinery, new york, ny, usa, article 52, 1–12)。gem5主要面临的问题是由于采用单线程des内核,限制了其对多核系统仿真的性能以及可拓展性。sniper在多核并行仿真上有较大优势,但由于其基于trace仿真,模拟的精确度相对较低。目前主流的gpu仿真器是gpgpu-sim(ali bakhoda, george l yuan, wilson wl fung, henry wong, and tor maamodt. 2009. analyzing cuda workloads using a detailed gpu simulator. inperformance analysis of systems and software, 2009. ispass 2009. ieeeinternational symposium on. ieee, 163–174.)。
2、除了这几个基本的仿真器,许多研究提出了一些面向多核并行的仿真器,相比原来的仿真器提高了其并行仿真的能力以及可扩展性。daniel sanchez 和 christoskozyrakis提出了zsim仿真器(daniel sanchez and christos kozyrakis. 2013. zsim:fast and accurate microarchitectural simulation of thousand-core systems.sigarch comput. archit. news 41, 3 (june 2013), 475–486.),该仿真器通过绑定-编织并行化,提高了其在多核主机上并行模拟的可扩展性,但由于其采用了分阶段时钟同步,即尽管各核的模拟是并行的,但所有核的模拟都会在达到预定的周期数时通过一个同步屏障进行同步。这种同步方式会导致提前完成的核需要等待其他所有核完成该阶段的任务才会进入到下一阶段中,提高了仿真的时间开销。j. e. miller等人提出了graphite仿真器(j. e. miller et al., "graphite: a distributed parallel simulator formulticores," hpca - 16 2010 the sixteenth international symposium on high-performance computer architecture, bangalore, india, 2010, pp.),该仿真器采用的是宽松同步的时钟同步策略。该策略的特点在于各个芯粒上的时钟彼此独立运行,只在特定的时候进行同步。该仿真器同步策略的不足在于在处理事件时,graphite 不严格执行所有事件的顺序。在某些情况下,它会忽略时间戳,根据事件在本地执行的顺序来决定操作的延迟,而不是它们在模拟系统中应有的精确顺序。rafael ubal等人提出了multi2sim仿真器(rafael ubal, byunghyun jang, perhaad mistry, dana schaa, and davidkaeli. 2012. multi2sim: a simulation framework for cpu-gpu computing. inproceedings of the 21st international conference on parallel architecturesand compilation techniques (pact '12). association for computing machinery,new york, ny, usa, 335–344.),该仿真器通过一种详尽的同步策略来模拟cpu和gpu的交互。由于该策略使用了指令级同步,虽然提高了仿真精度,但大大增加了仿真开销。
3、准确且快速地对多进程或多线程进行同步时并行仿真面临的主要问题。quantum-based barrier synchronization(mohammad, a. darbaz, u. dozsa, g. diestelhorst,s, kim, d. and kim, n. s. dist-gem5: distributed simulation of computerclusters. in 2017 ieee international symposium on performance analysis ofsystems and software (ispass) (pp. 153-162). 2017, april)是一种全局同步算法。相比逐周期同步,该同步方式减少了同步开销。相比完全不同步,该同步方式在准确率上更有优势。但是其依然要设置屏障对所有芯粒进行同步。
4、并行仿真的时钟同步算法有lbts和fnm这两个典型的算法。lbts算法(r. m.fujimoto, "parallel and distributed simulation systems," proceeding of the2001 winter simulation conference (cat. no.01ch37304), arlington, va, usa,2001, pp. 147-157 vol.1, doi: 10.1109/wsc.2001.977259.)在并行和分布式仿真中用于管理和控制仿真时间的推进。它确保事件按照因果关系一致的顺序处理,即按照时间戳非递减的顺序处理事件,这对于保持仿真的完整性和正确性至关重要。forecast null-message (fnm) 算法(jun wang, zhenjiang dong, sudhakar yalamanchili, andgeorge riley. 2013. optimizing parallel simulation of multicore systems usingdomain-specific knowledge. in proceedings of the 1st acm sigsim conference onprinciples of advanced discrete simulation (sigsim pads '13). association forcomputing machinery, new york, ny, usa, 127–136.)是一种用于并行离散事件仿真中的事件调度和时间管理算法。它通过发送空消息来避免不同处理器之间的时间戳反转和不一致问题,从而保证仿真的正确性。该方法的不足在于需要对片间网络传输延迟进行预测,时序模型有一定的误差。
5、本方法的优势在于既确保了功能与时序模型的准确性,也减少了仿真同步开销。由于本方法只有在有信息交互的芯粒之间进行时钟同步,大幅缩短了仿真时间。通过功能仿真,保证事件因果关系的正确,通过网络仿真,计算网络传输延迟;通过时序仿真,实现对时钟的准确同步,确保了并行仿真的在功能模型以及时序模型的准确。
技术实现思路
1、本发明的目的在于针对现有技术的不足,提供一种多芯粒并行仿真同步的方法。
2、为实现上述目的,本发明提供了一种多芯粒并行仿真同步的方法,包括如下步骤:
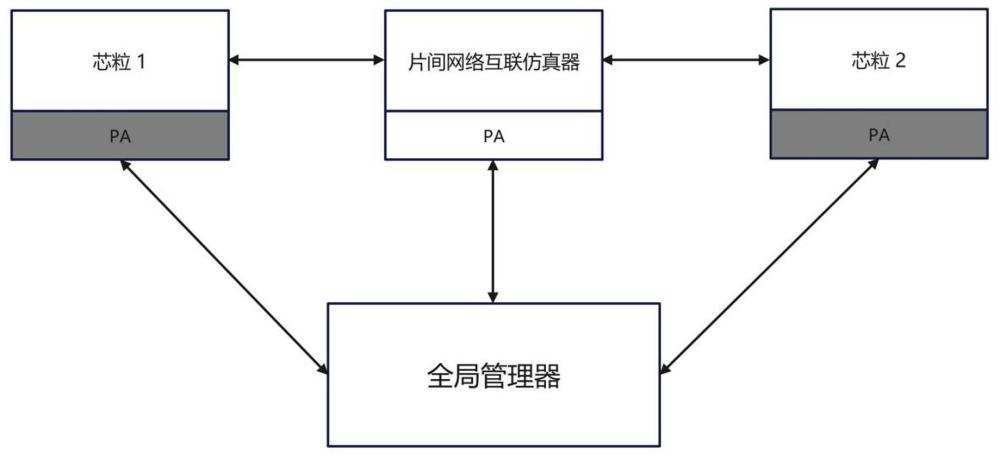
3、(1)功能仿真:通过芯粒与全局管理器的读写匹配,确保读写事件的因果关系正确,实现准确的功能模型仿真;同时记录对共享内存访问的时间,以及仿真过程中产生的通信流量;所述全局管理器用于记录每个从芯粒发出事件的时序;
4、(2)网络仿真:根据步骤(1)仿真过程中产生的通信流量,片间网络仿真器对读写事件进行仿真,计算出每个读写事件在片间网络中的传输延迟,得到传输延迟数据;
5、(3)时序仿真:将步骤(2)得到的传输延迟数据与步骤(1)仿真后的功能模型相结合,得到片间网络延迟;再重新进行完整的仿真,实现对时序模型的准确构建;
6、(4)重复执行步骤(2)和步骤(3),直至时序仿真结果收敛,实现各个芯粒间时钟的同步。
7、进一步地,所述步骤(1)的功能仿真中,包括远程读操作和远程写操作;
8、远程读操作:当应用程序调用对应的芯粒读操作时,通过芯粒仿真器执行其功能模型和时序模型来执行所请求的指令;芯粒仿真器向功能模型的全局控制器发送读请求;全局控制器匹配两个芯粒的读写请求后,向发送读请求的芯粒仿真器发送批准信息,允许该芯粒仿真器从共享内存中读取数据;当芯粒仿真器接收到读许可后,功能模型从共享内存中读取数据到对应芯粒的网络接口模块;芯粒仿真器再将数据从网络接口模块传输到本地存储模块;同时,通过全局管理器将时钟周期调整到发送方发送数据时的时钟周期;
9、远程写操作: 当应用程序调用对应芯粒写操作时,通过芯粒仿真器执行其功能模型和时序模型来执行所请求的指令;芯粒仿真器向功能模型的全局控制器发送写请求;全局控制器匹配两个芯粒的读写请求后,向发送写请求的芯粒仿真器发送批准信息,允许该芯粒仿真器向共享存储器中写数据;当芯粒仿真器接收到写许可后,功能模型将数据传输到对应芯粒的网络接口模块,芯粒仿真器再将数据从网络接口模块传输到共享存储器中。
10、进一步地,所述步骤(2)具体为:根据步骤(1)仿真过程中片间信息传输的流量,以及设定的片间网络拓扑,通过片间网络仿真器对片间网络信息传递进行仿真,计算出每个读写事件在片间网络中的传输延迟,获取传输延迟数据。
11、进一步地,所述步骤(3)中,时序仿真在功能仿真的读写操作上增加了时序模型的同步,具体为:芯粒仿真器向时序模型的全局控制器发送时间请求,以获取数据到达时的时钟周期;全局管理器的时序模型根据时序仿真得到的片间网络延迟,计算出数据到达时的时钟周期;在时序同步过程中,将时钟周期传递给芯粒仿真器,并据此修改芯粒仿真器的时钟周期。
12、为实现上述目的,本发明还提供了一种多芯粒并行仿真同步的装置,包括一个或多个处理器,用于实现上述的多芯粒并行仿真同步的方法。
13、为实现上述目的,本发明还提供了一种电子设备,包括存储器和处理器,所述存储器与所述处理器耦接;其中,所述存储器用于存储程序数据,所述处理器用于执行所述程序数据以实现上述的多芯粒并行仿真同步的方法。
14、为实现上述目的,本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现上述的多芯粒并行仿真同步的方法。
15、本发明的有益效果是,本发明通过多轮并行仿真,既保证了功能模型对于事件因果关系的准确构建,同时保证了各个芯粒间时钟的同步;并且保证了并行仿真的准确性。由于只用在有信息交互的时候,参与交互的芯粒进行同步,不需要进行全局同步;大大提高了仿真的速度。
本文地址:https://www.jishuxx.com/zhuanli/20241014/317551.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表