基于统计知识增强的目标关系抽取方法
- 国知局
- 2024-10-15 09:27:37
本发明涉及深度学习和图像处理领域,尤其涉及一种基于统计知识增强的目标关系抽取方法。
背景技术:
1、视觉关系抽取是计算机视觉领域中的一个任务,旨在识别和理解图像中不同物体之间的关系。它涉及到了对物体之间的空间关系、功能关系和语义关系等进行建模和推断。通常输入是一幅图像以及图中目标的位置,输出是描述物体之间关系的标签或类别。例如,在一张包含人和球的图像中,视觉关系抽取任务可以分类人物和球之间的关系,如"持有"、"踢"、"接触"等。
2、视觉关系抽取任务的价值在于提高计算机对于图像场景的理解和推理能力,为视觉搜索和其他计算机视觉任务提供支持,并在实际应用中发挥重要作用,如场景理解、视觉推理、视觉搜索和计算机辅助视觉任务等。在视觉关系抽取中,目标类别和关系类型天然存在很强的统计关联,如人和球的关系就可能是“持有”、“踢”等,不太可能是“穿着”。利用统计关系可以用于增强模型的学习能力和泛化能力。通过在训练过程中考虑目标类别和关系类别之间的统计关系,我们可以引导模型更好地学习和泛化不同目标和关系之间的特征表示。这有助于提高模型的鲁棒性和泛化能力,使其在未见过的场景中能够准确地推断和预测目标之间的关系。因此,如何把这种目标类别和关系类型的统计关系引入视觉关系抽取算法中,提升其性能,是一个值得探索的研究路径。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明公开了基于统计知识增强的目标关系抽取方法。所述方法能够识别图片中目标之间的关系,相比现有方法,本方法关注到目标类型和关系之间天然地存在统计知识,本方法创新性对这种统计关联进行建模,并提出统计知识注入模块,把统计知识注入到深度学习模型,实现高精度的视觉关系抽取。
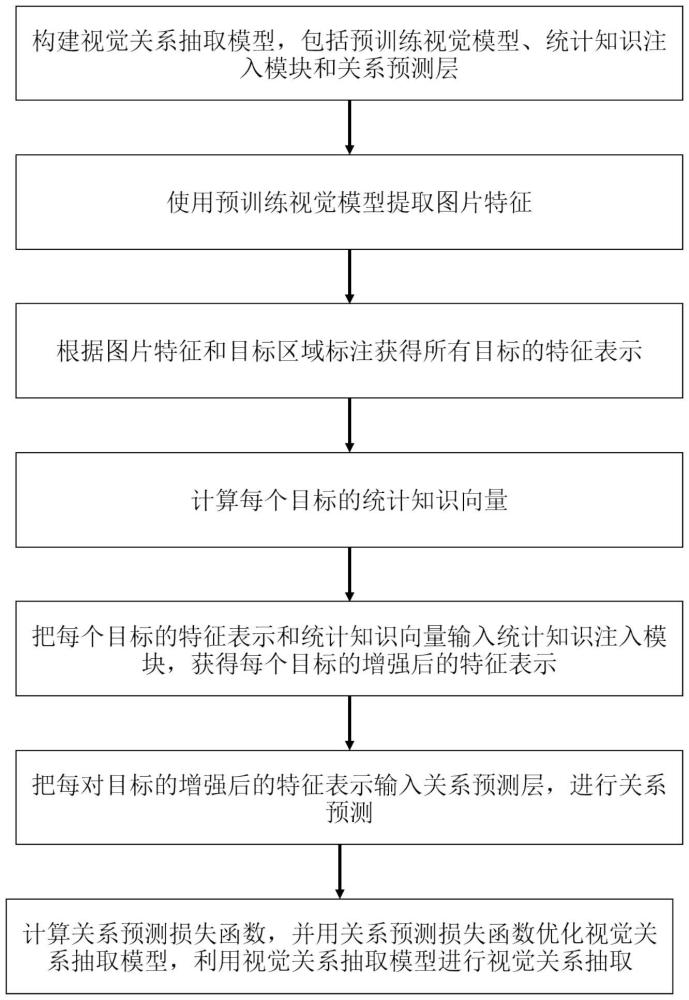
2、本发明的目的是通过如下技术方案实现的,基于统计知识增强的目标关系抽取方法,所述方法包括:
3、步骤1,构建视觉关系抽取模型,包括预训练视觉模型、统计知识注入模块和关系预测层;
4、步骤2,使用预训练视觉模型提取图片特征;
5、步骤3,根据图片特征和目标区域标注获得所有目标的特征表示;
6、步骤4,计算每个目标的统计知识向量;
7、步骤5,把每个目标的特征表示和统计知识向量输入统计知识注入模块,获得每个目标的增强后的特征表示;
8、步骤6,把每对目标的增强后的特征表示输入关系预测层,进行关系预测;
9、步骤7,计算关系预测损失函数,并用关系预测损失函数优化视觉关系抽取模型,利用视觉关系抽取模型进行视觉关系抽取。
10、所述的计算每个目标的统计知识向量,包括以下步骤:
11、步骤401,对第i个目标计算主体统计知识向量;表达式为:
12、
13、si=[si,1,si,2,...,si,c]
14、其中,表示第i个目标的主体统计知识向量,c表示数据集预定义的关系类别数,si,k表示si的第k个元素,ti表示第i个目标的目标类型,表示训练集中主体类型为ti的三元组个数,表示训练集中主体类型为ti关系为第k类关系的三元组个数;
15、步骤402,对第i个目标计算客体统计知识向量;表达式为:
16、
17、oi=[oi,1,oi,2,...,oi,c]
18、其中,表示第i个目标的客体统计知识向量,c表示数据集预定义的关系类别数,oi,k表示oi的第k个元素,ti表示第i个目标的目标类型,表示训练集中客体类型为ti的三元组个数,表示训练集中客体类型为ti关系为第k类关系的三元组个数;
19、步骤403,对第i个目标计算统计知识向量;把第i个目标的主体统计知识向量si和第i个目标的客体统计知识向量oi拼接到一起,得到第i个目标的统计知识向量,表达式为:
20、hi=[si,oi]
21、其中,hi表示第i个目标的统计知识向量,si表示第i个目标的主体统计知识向量,oi表示第i个目标的客体统计知识向量;
22、步骤404,对所有目标计算统计知识向量,表达式为:
23、h=[h1,h2,...,hn]
24、其中,h表示所有目标的统计知识向量,hi表示第i个目标的统计知识向量,n表示目标的数量。
25、所述的使用预训练视觉模型提取图片特征,包括以下步骤:
26、输入图片表示为使用预训练视觉模型提取输入图片的视觉特征,表达式为:
27、fimg=resnet(x)
28、其中,表示图片的视觉特征,w和h表示图片的宽和高,d表示resnet的隐藏层维度,s表示resnet的下采样倍数。
29、所述的根据图片特征和目标区域标注获得所有目标的特征表示,包括以下步骤:
30、根据目标区域标注,将目标的位置表示为矩形框的坐标(xi,yi,wi,hi),其中i表示目标的索引,xi和yi表示矩形框的左上角坐标,wi和hi表示矩形框的宽度和高度;
31、使用roialign算法,将目标区域标注映射到图片特征的空间中,得到目标的视觉特征图,表达式为:
32、
33、其中,表示第i个目标的视觉特征图,d表示resnet的隐藏层维度,so表示roialign的输出大小;
34、对第i个目标的视觉特征图进行自适应池化,获得第i个目标的特征表示,表达式为:
35、
36、其中,表示第i个目标的特征表示;
37、对每个目标都提取视觉特征,得到所有目标的特征表示:
38、
39、其中,表示所有目标的特征表示,n表示目标的数量。
40、所述的把每个目标的特征表示和统计知识向量输入统计知识注入模块,获得每个目标的增强后的特征表示,包括以下步骤:
41、把第i个目标的特征表示和统计知识向量输入统计知识注入模块,表达式为:
42、
43、其中,gi表示第i个目标的增强后的特征表示,表示第i个目标的特征表示,hi表示第i个目标的统计知识向量,wg、wf、wh、bf和bg是可学习参数,tanh是激活函数;
44、对每个目标计算增强后的特征表示,表达式为:
45、g=[g1,g2,...,gn]
46、其中,g表示所有目标的增强后的特征表示,gi表示第i个目标的增强后的特征表示,n表示目标的数量。
47、所述的把每对目标的增强后的特征表示输入关系预测层,进行关系预测,包括以下步骤:
48、把第i个目标和第j个目标的增强后的特征表示输入关系预测层,表达式为:
49、pij=softmax(wo[gi,gj]+bo)
50、其中,pij表示预测的第i个目标和第j个目标的关系概率向量,softmax是激活函数,[·,·]表示向量拼接操作,wo和bo是可学习参数,gi是第i个目标的增强后的特征表示,gj是第j个目标的增强后的特征表示;
51、把所有目标对输入关系预测层,获得所有目标对的关系概率向量。
52、所述的计算关系预测损失函数,并用关系预测损失函数优化视觉关系抽取模型,利用视觉关系抽取模型进行视觉关系抽取,包括以下步骤:
53、步骤701,计算关系预测损失函数,表达式为:
54、
55、其中,l表示关系预测损失函数,n表示目标的数量,c表示数据集的关系类别数,pijk表示所述的预测的第i个目标和第j个目标的关系概率向量pij的第k个元素,qijk是关系标注,当第i个目标和第j个目标有第k类关系时,qijk=1,否则qijk=0;
56、步骤702,用关系预测损失函数l优化视觉关系抽取模型,利用视觉关系抽取模型进行视觉关系抽取。
57、与现有方法相比,本发明方法的优点在于:本技术提供了基于统计知识增强的目标关系抽取方法,本方法创新性对目标类型和关系之间的统计关联进行建模,并提出统计知识注入模块,把统计知识注入到深度学习模型,实现高精度的视觉关系抽取。
本文地址:https://www.jishuxx.com/zhuanli/20241015/314202.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表