一种基于连续区间组合的标志物筛选方法、系统、电子设备及标志物的组合和应用与流程
- 国知局
- 2024-10-15 09:36:09
本技术属于疾病分类,具体地,涉及一种基于连续区间组合的标志物筛选方法、系统、电子设备及标志物的组合和应用。
背景技术:
1、目前,随着疾病普筛与部分类型疾病早诊早治的推广与覆盖,导致更多疾病的早期症状被发现确诊,表现为发病率的增加。通过早期有效干预,能够提高很多普筛患者的生存率,表现为如血液系统疾病、癌症的死亡率降低,以及延缓糖尿病等代谢性疾病的发展速度等。
2、血浆游离dna甲基化信号因其在高甲基化相关疾病的早筛、早诊体外检测产品中的杰出表现,成为备受科学家们关注的标志物焦点。例如,通过检测s9的甲基化信息可以预警早期肠癌的发生,临床表现为特异性高达95%。随着研究技术的迭代更新,特别是靶向测序技术(panel)/全基因组甲基化测序(wgbs)技术的引入,许多基于dna甲基化的疾病早筛、早诊标志物被广泛开发与应用,如利用高通量检测技术可以在基因组范围内寻找候选的cpg位点,特别是提取连续的候选cpg位点,并开发标志物产品。
3、然而,由于血浆游离dna(cfdna)中来自于病变细胞的信号占比很低,因此如何在cfdna的甲基化信号中提取稳定的病变细胞来源信号是标志物筛选中需要解决的关键问题。针对当前利用靶向测序技术(panel)/全基因组甲基化测序(wgbs)数据筛选的标志物在单cpg位点水平上的低鲁棒性,以及在预设定区间水平上的高假阳性问题,本专利提出一种筛选包含高连续性cpg位点区间的甲基化标志物方法。
技术实现思路
1、为了解决现有技术中存在的问题,本技术的目的在于提供基于连续区间组合的标志物筛选方法。通过对候选区间的多步骤分析筛选,确定高连续性的最优标志物和最优标志物的组合,以在血浆游离dna中获得稳定的细胞信号标志物。
2、具体来说,本技术涉及如下方面:
3、1.一种基于连续区间组合的标志物筛选方法,包括:
4、采集步骤,用于分别获取第一人群样本和第二人群样本中的对应甲基化区间和甲基化区间中cpg位点的甲基化值;
5、差异定量步骤,基于所述甲基化区间,针对所述甲基化区间中的每个cpg位点计算其在第一人群样本和第二人群样本中的差异水平;获取差异水平满足临界条件的差异cpg位点;
6、连续位点提取步骤,用于利用所述差异cpg位点的对应基因组位置的位置关系获取多个连续位点区间;
7、特征区间筛选步骤,用于从所述多个连续位点区间中筛选候选特征区间,基于所述候选特征区间获取第一人群样本和第二人群样本中存在差异的候选特征区间组合作为特征区间,最终确定为标志物;
8、其中,第一人群和第二人群是具有不同特征且所述特征不重合的两类人群。
9、2.根据项1的方法,其中,针对所述甲基化区间中的每个cpg位点计算差异水平包括:
10、分别计算第一人群样本和第二人群样本的所述甲基化区间中的cpg位点平均甲基化水平;
11、计算第一人群样本的所述甲基化区间中的cpg位点α百分位甲基化水平和第二人群样本的所述甲基化区间中的cpg位点β百分位甲基化水平;以及
12、计算第一人群样本和第二人群样本的所述甲基化区间中的cpg位点甲基化水平的显著性水平p。
13、3.根据项2的方法,其中,获取差异水平满足临界条件的差异cpg位点,所述临界条件包括:
14、第一人群样本和第二人群样本的所述甲基化区间中的cpg位点平均甲基化水平的差值≥a;
15、第一人群样本的所述甲基化区间中的cpg位点α百分位甲基化水平和第二人群样本的所述甲基化区间中的cpg位点β百分位甲基化水平的差值≥b;以及
16、第一人群样本和第二人群样本的所述甲基化区间中的cpg位点平均甲基化水平的差值>c且第一人群样本和第二人群样本的所述甲基化区间中的cpg位点甲基化水平的显著性水平p<k。
17、4.根据项1的方法,其中,利用所述差异cpg位点的对应基因组位置的位置关系获取多个所述连续位点区间包括:
18、候选区间定义步骤,将第一人群样本和第二人群样本的任一染色体上第一个差异cpg位点设置为一个候选区间的起始位点和初始终止位点;
19、候选区间合并步骤,由所述第一个差异cpg位点开始向后读取cpg位点,将符合约束条件g的差异cpg位点合并至所述候选区间中,以更新所述候选区间的长度并最终确定所述候选区间的终止位点;以及
20、继续读取所述候选区间后的下一个差异cpg位点,重复候选区间合并步骤以确定新的所述候选区间,以此方式重复得到所述染色体上的所有所述候选区间;
21、对其它染色体重复候选区间定义步骤和候选区间合并步骤,以得到其他染色体上的所有所述候选区间,将全部染色体上的所有所述候选区间设置为所述多个连续位点区间。
22、5.根据项4的方法,其中,所述候选区间的区间长度在区间长度约束条件内;
23、所述约束条件g包括:当前读取到的差异cpg位点与上一个差异cpg位点的间隔≤i个读取步长;
24、所述读取步长为j个cpg位点。
25、6.根据项5的方法,其中,所述候选区间的区间长度在区间长度约束条件内包括:
26、所述候选区间的区间长度达到约束条件d时,停止更新所述候选区间的长度,以当前读取的差异cpg位点作为所述候选区间的终止位点。
27、7.根据项1的方法,其中,从所述多个连续位点区间中筛选候选特征区间,基于所述候选特征区间获取第一人群样本和第二人群样本中存在差异的候选特征区间组合作为特征区间包括:
28、基于第一人群样本和第二人群样本的所述多个连续位点区间的筛选指标,筛选得到n个候选特征区间;
29、对n个候选特征区间进行组合,得到个候选特征区间组合;以及
30、评估所述候选特征区间组合的分类性能,选择前m个所述候选特征区间组合作为所述特征区间。
31、8.根据项7的方法,其中,基于第一人群样本和第二人群样本的所述多个连续位点区间的筛选指标,筛选出n个候选特征区间包括:
32、计算第一人群样本和第二人群样本的所述多个连续位点区间的特异性和灵敏度;以及
33、对第一人群样本和第二人群样本的所述多个连续位点区间进行区间水平的背景信号校正。
34、9.一种基于连续区间组合的标志物筛选系统,包括:
35、采集模块,用于分别获取第一人群样本和第二人群样本中的对应甲基化区间和甲基化区间中cpg位点的甲基化值;
36、差异定量模块,基于所述甲基化区间,针对所述甲基化区间中的每个cpg位点计算其在第一人群样本和第二人群样本中的差异水平;获取差异水平满足临界条件的差异cpg位点;
37、连续位点提取模块,用于利用所述差异cpg位点的对应基因组位置的位置关系获取多个连续位点区间;
38、特征区间筛选模块,用于从所述多个连续位点区间中筛选候选特征区间,基于所述候选特征区间获取第一人群样本和第二人群样本中存在差异的候选特征区间组合作为特征区间,最终确定为标志物。
39、10.根据项9的系统,其为执行项1-8中任一项所述的方法。
40、11.一种电子设备,包括:
41、处理器;以及
42、存储器,在所述存储器中存储有计算机程序指令,所述计算机程序指令在被所述处理器运行时使得所述处理器执行如项1-8中任一项所述的方法。
43、12.一种癌症检测的标志物,其中,所述标志物包含下述中的一种或两种及以上:
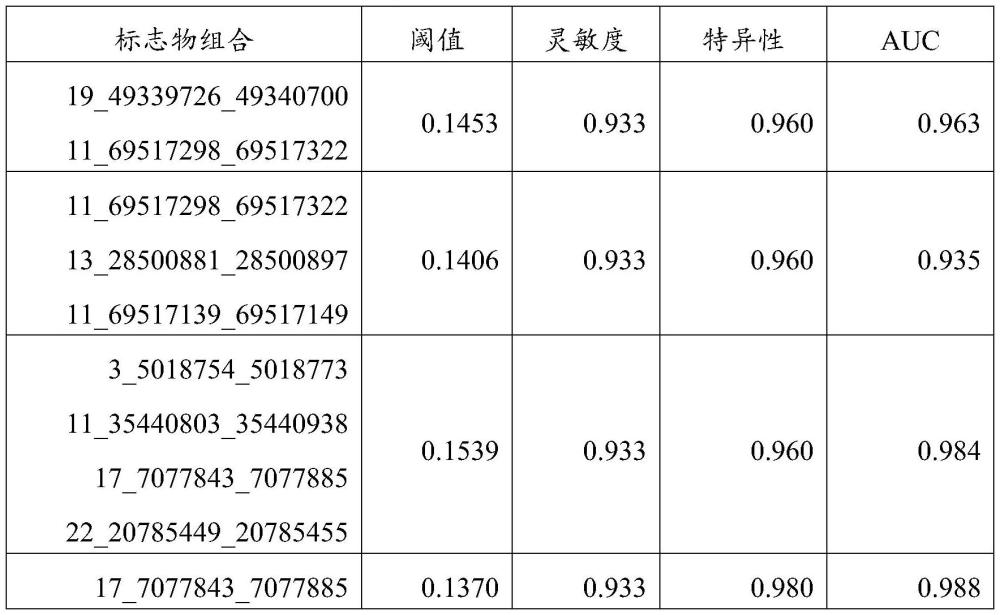
44、11号染色体的69517298至69517322位的基因组区域和19号染色体的49339726至49340700位的基因组区域的组合;
45、11号染色体的69517139至69517149位的基因组区域、11号染色体的69517298至69517322位的基因组区域和13号染色体的28500881至28500897位的基因组区域的组合;
46、3号染色体的5018754至5018773位的基因组区域、11号染色体的35440803至35440938位的基因组区域、17号染色体的7077843至7077885位的基因组区域和22号染色体的20785449至20785455位的基因组区域的组合;
47、11号染色体的69517139至69517149位的基因组区域、13号染色体的28500881至28500897位的基因组区域、17号染色体的7077843至7077885位的基因组区域、20号染色体的3653427至3653432位的基因组区域和22号染色体的20785449至20785455位的基因组区域的组合;以及
48、3号染色体的5018754至5018773位的基因组区域、4号染色体的13544122至13544127位的基因组区域、11号染色体的35440803至35440938位的基因组区域、11号染色体的69517298至69517322位的基因组区域、13号染色体的28500881至28500897位的基因组区域和22号染色体的20785449至20785455位的基因组区域的组合。
49、13.标志物在制备用于癌症检测的试剂盒中的用途,其中,所述标志物包含下述中的一种或两种及以上:
50、11号染色体的69517298至69517322位的基因组区域和19号染色体的49339726至49340700位的基因组区域的组合;
51、11号染色体的69517139至69517149位的基因组区域、11号染色体的69517298至69517322位的基因组区域和13号染色体的28500881至28500897位的基因组区域的组合;
52、3号染色体的5018754至5018773位的基因组区域、11号染色体的35440803至35440938位的基因组区域、17号染色体的7077843至7077885位的基因组区域和22号染色体的20785449至20785455位的基因组区域的组合;
53、11号染色体的69517139至69517149位的基因组区域、13号染色体的28500881至28500897位的基因组区域、17号染色体的7077843至7077885位的基因组区域、20号染色体的3653427至3653432位的基因组区域和22号染色体的20785449至20785455位的基因组区域的组合;以及
54、3号染色体的5018754至5018773位的基因组区域、4号染色体的13544122至13544127位的基因组区域、11号染色体的35440803至35440938位的基因组区域、11号染色体的69517298至69517322位的基因组区域、13号染色体的28500881至28500897位的基因组区域和22号染色体的20785449至20785455位的基因组区域的组合。
55、14.一种癌症检测的组合物,其中,所述组合物包括:
56、用于检测项12所述标志物的甲基化状态的核酸,
57、其中,所述标志物的甲基化状态由所述标志物的靶序列的甲基化来表征。
58、15.一种试剂盒,其中,包含用于检测项12所述标志物的试剂。
59、有益效果
60、本技术所述基于连续区间组合的标志物具有以下技术效果:
61、1、利用cfdna早期发现和诊断疾病:本技术采用cfdna中具有连续差异cpg位点的甲基化区间组合作为标志物检测病变细胞信号,可以用于多种疾病的早期发现和诊断。因为cfdna的甲基化标志物可以在许多疾病早期就发生改变,如大多数人体肿瘤等肿瘤疾病、系统性红斑狼疮等自身免疫性疾病以及部分心血管疾病中,因此本技术的标志物可以提高多种疾病早筛的准确性和敏感性,进而有效地提高治疗效果和生存率。
62、2、解决传统cfdna疾病早筛的缺陷:由于cfdna中来自于病变细胞的信号占比很低,因此如何在cfdna甲基化信号中提取稳定的病变细胞来源信号是标志物筛选中需要解决的关键问题。针对当前利用靶向测序技术(panel)/全基因组甲基化测序(wgbs)数据筛选的标志物在单cpg位点水平上的低鲁棒性表现,以及在预设定区间时区间内存在的单离群cpg位点水平导致的高假阳性问题,本技术筛选并利用包含多个甲基化差异位点的连续位点区间的组合构建标志物,连续位点区间通过差异化位点的连续性读取操作实现同步设置与更新,避免离群cpg位点对连续位点区间的混杂作用,同时对包含丰富差异化甲基化信息的连续位点区间进一步组合筛选,有效降低现有标志物检测时出现假阳性检测结果的概率,同时保持较高的阳性检出正确率,从而进一步提高基于cfdna标志物的疾病早筛的可信度与检测效率。
63、3、提高了早筛疾病的治疗效果和预后:本技术使用包含连续差异化cpg位点的甲基化区间标志物组合进行检测,能够用于早期发现和诊断多种人体病变。由于早期的非传病,如肿瘤、自身免疫病等易于早期预防和治愈,因此通过cfdna标志物进行疾病的早期发现可以有效避免病情恶化,从而提高后续治疗效果和生存率。
64、本技术所述基于连续位点区间组合的标志物具有高灵敏度和高特异性特点(auc为0.996时,对应的灵敏性和特异性分别为0.933和0.98),能够实现精准的阳性样本检测。
本文地址:https://www.jishuxx.com/zhuanli/20241015/314670.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
一种产检床物品收纳盒
下一篇
返回列表