一种基于定位置信度的改进视觉多目标跟踪方法
- 国知局
- 2024-10-21 14:29:45
本发明属于环境感知,涉及一种基于定位置信度的改进视觉多目标跟踪方法。
背景技术:
1、多目标跟踪(multi-object-tracking,mot)作为计算机视觉领域的一项重要技术,在自动驾驶、安防监控、机器人领域得到了广泛应用。目前,检测跟踪范式(tracking-by-detection,tbd)是多目标跟踪的主流范式,它主要通过关注数据关联环节来提高跟踪性能。
2、目前,多目标跟踪技术目前还存在以下挑战。首先,对于物体运动建模,大多数方法使用线性卡尔曼滤波算法,这些方法给所有目标设定一个统一的观测噪声,并没有考虑到检测框的质量对更新状态的影响。对于质量较差的检测框,在卡尔曼更新时,会增加跟踪框的位置误差。其次,在数据关联过程中,由于运动和外观信息都是有价值的,一些跟踪器将两种信息融合,并构造一个组合代价函数用于匹配检测框和轨迹。值得注意的是,这些方法没有自适应地确定每一个检测框的运动和外观信息的权重分配,只是简单通过实验选定一个固定的加权因子,来分配两种信息的融合权重,寻求数据集的整体关联效果的改进。最后,对于匹配成功的轨迹,需要更新其外观特征状态,而现有的外观更新策略,没有区分考虑检测框的定位精度和外观清晰度对外观特征影响程度,对关联精度的改善是有限的。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于定位置信度的改进视觉多目标跟踪方法,即一种新的自适应卡尔曼滤波器、一种自适应融合代价函数以及一种更准确合理的动态外观更新策略。
2、为达到上述目的,本发明提供如下技术方案:
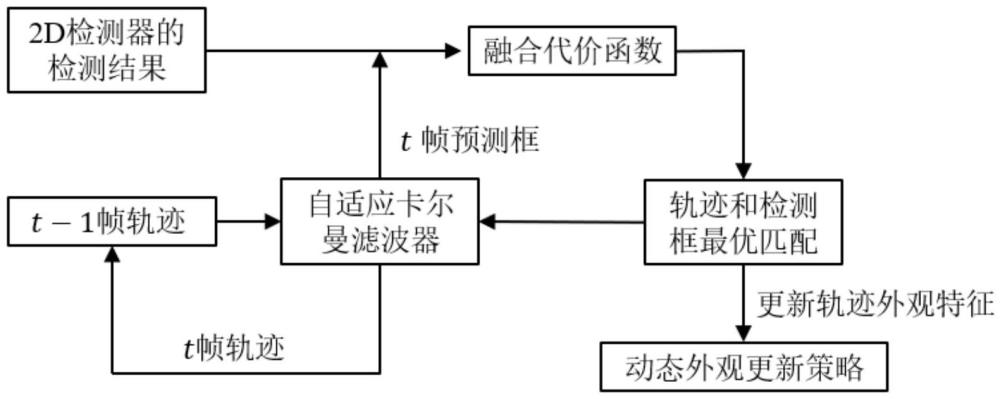
3、一种基于定位置信度的改进视觉多目标跟踪方法,包括以下步骤:
4、s1:检测每一时刻目标物体的信息;
5、s2:基于前一帧的轨迹跟踪结果,利用自适应卡尔曼滤波器,预测该轨迹在当前帧的位置坐标,即得到当前帧的轨迹预测框;
6、s3:计算当前帧的轨迹预测框和检测框的融合代价函数,并基于融合代价函数实现轨迹和检测框的最优匹配;
7、s4:利用自适应卡尔曼滤波器,基于轨迹成功匹配到的检测框,更新得到当前帧的跟踪结果(轨迹),并将跟踪结果输出;
8、s5:对于成功匹配到检测框的轨迹,利用动态外观更新策略自适应地更新轨迹的外观特征。
9、进一步,步骤s1中,使用2d检测器检测每一时刻目标物体的信息,包括位置坐标、检测置信度、定位置信度和分类置信度;所述目标物体信息表示为
10、2d bounding box=(x1,y1,x2,y2,sdet,sloc,scls)
11、其中(x1,y1,x2,y2)为检测框的左下角点坐标(x1,y1)和右上角点坐标(x2,y2),sdet为检测框的检测置信度,sloc为检测框的定位置信度,scls为检测框的分类置信度。
12、进一步,步骤s2中,基于上一帧的轨迹,利用自适应卡尔曼滤波器预测轨迹在当前帧的位置坐标(x1,y1,x2,y2),(x1,y1,x2,y2)为轨迹预测框的左下角点和右上角点坐标。
13、进一步,步骤s3具体包括以下步骤:
14、s31:计算当前帧的轨迹预测框和检测框的基于运动信息的代价函数,即交并比(intersection over union,iou),具体计算公式如下:
15、
16、其中,di表示当前帧的第i个检测框,tj表示当前帧的第j条轨迹;
17、s32:计算当前帧的轨迹和检测框的基于外观信息的代价函数,即轨迹和检测框的外观特征向量之间的余弦距离,具体计算公式如下:
18、
19、其中,表示当前帧的第i个检测框的外观特征向量,表示当前帧的第j条轨迹的外观特征向量;
20、s33:基于检测框的定位置信度和分类置信度,计算当前帧轨迹和检测框的融合代价函数,计算公式如下:
21、caf(i,j)=sloc×ciou(i,j)+sdet×ccos(i,j)
22、其中,sloc表示第i个检测框的定位置信度,sdet表示第i个检测框的检测置信度;
23、检测框的定位置信度在一定程度上可以反应检测框的定位精度,同时,检测置信度在一定程度上可以反应检测框的外观清晰度,故将定位置信度和检测置信度分别为与基于运动和外观信息的代价函数相乘,得到融合代价函数。
24、s34:基于代价函数caf,利用匈牙利算法将轨迹和检测框进行最优匹配;
25、s35:设置融合代价矩阵的匹配阈值为thresh,若第i个检测框和第j条轨迹之间的caf(i,j)的值小于阈值thresh,则该轨迹和检测框匹配成功;若caf(i,j)的值大于阈值thresh,则该轨迹和检测框匹配失败。
26、进一步,步骤s4具体包括以下步骤:
27、s41:对于成功匹配到检测框的轨迹,根据该轨迹的消失帧数和检测框的检测置信度,自适应地调整观测噪声协方差rk,具体计算公式如下:
28、
29、其中,rk是预设的观测噪声协方差,sdet为轨迹匹配到的检测框的检测置信度,σ为划分检测框的检测置信度高低的阈值分数;对于lost,具体计算公式如下:
30、
31、其中,lostframe是该轨迹当前连续消失的帧数,lostthresh是轨迹最大保留帧数阈值;
32、s42:利用rk计算卡尔曼增益,进行卡尔曼更新,得到轨迹的最终位置坐标,并作为跟踪结果输出。
33、进一步,步骤s5中,基于该轨迹在当前帧匹配到的检测框的定位置信度和分类置信度,分别考虑其定位精度和外观清晰度对外观特征的影响程度,确定自适应加权因子,将匹配到的检测框的外观特征添加到该轨迹的外观特征状态中,更新该轨迹的外观特征状态,计算公式如下:
34、et=αpdaet-1+(1-αpda)ft
35、其中,et-1是更新前轨迹的外观特征状态;ft是该轨迹在当前帧成功匹配到的检测框的外观特征;对于自适应权重因子αpda,计算公式如下:
36、
37、其中,αf是固定的阈值;scls为轨迹匹配到的检测框的分类置信度;sloc为轨迹匹配到的检测框的定位置信度;σdet为划分检测框的分类置信度高低的阈值分数;σloc为划分检测框的定位置信度高低的阈值分数。
38、本发明的有益效果在于:本发明提升了基于tbd范式的mot方法的数据关联精度,为无人驾驶技术提供更精确的环境感知,为路径规划和控制决策奠定了基础。
39、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
技术特征:1.一种基于定位置信度的改进视觉多目标跟踪方法,其特征在于:包括以下步骤:
2.根据权利要求1所述的基于定位置信度的改进视觉多目标跟踪方法,其特征在于:步骤s1中,使用2d检测器检测每一时刻目标物体的信息,包括位置坐标、检测置信度、定位置信度和分类置信度;所述目标物体信息表示为
3.根据权利要求1所述的基于定位置信度的改进视觉多目标跟踪方法,其特征在于:步骤s2中,基于上一帧的轨迹,利用自适应卡尔曼滤波器预测轨迹在当前帧的位置坐标(x1,y1,x2,y2),(x1,y1,x2,y2)为轨迹预测框的左下角点和右上角点坐标。
4.根据权利要求1所述的基于定位置信度的改进视觉多目标跟踪方法,其特征在于:步骤s3具体包括以下步骤:
5.根据权利要求1所述的基于定位置信度的改进视觉多目标跟踪方法,其特征在于:步骤s4具体包括以下步骤:
6.根据权利要求1所述的基于定位置信度的改进视觉多目标跟踪方法,其特征在于:步骤s5中,基于该轨迹在当前帧匹配到的检测框的定位置信度和分类置信度,分别考虑其定位精度和外观清晰度对外观特征的影响程度,确定自适应加权因子,将匹配到的检测框的外观特征添加到该轨迹的外观特征状态中,更新该轨迹的外观特征状态,计算公式如下:
技术总结本发明涉及一种基于定位置信度的改进视觉多目标跟踪方法,属于环境感知技术领域,包括以下步骤:S1:检测每一时刻目标物体的信息;S2:基于前一帧的轨迹跟踪结果,利用自适应卡尔曼滤波器,预测该轨迹在当前帧的位置坐标,即得到当前帧的轨迹预测框;S3:计算当前帧的轨迹预测框和检测框的融合代价函数,并基于融合代价函数实现轨迹和检测框的最优匹配;S4:利用自适应卡尔曼滤波器,基于轨迹成功匹配到的检测框,更新得到当前帧的轨迹跟踪结果,并将跟踪结果输出;S5:对于成功匹配到检测框的轨迹,利用动态外观更新策略自适应地更新轨迹的外观特征。技术研发人员:傅春耘,孟婷受保护的技术使用者:重庆大学技术研发日:技术公布日:2024/10/17本文地址:https://www.jishuxx.com/zhuanli/20241021/318368.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表