一种多模型融合的VVC帧内编码快速CU划分方法及存储介质
- 国知局
- 2024-10-21 14:30:57
本发明属于视频编码领域,更具体地说,一种适用于通用视频编码(versatilevideo coding,vvc)的帧内编码的编码单元(coding unit,cu)快速划分方法,可应用于实时性要求较高的视频编码场景中。
背景技术:
1、随着互联网应用的普及,用户对于视频的期望也不断提升,他们希望获得更加逼真和清晰的视觉体验,并且期待视频播放的流畅性能达到更高水平。为了满足用户的需求,出现了各种新兴的视频应用,比如超高清(ultra high definition,uhd)、高帧率(highframe rate,hfr)、高动态范围(high dynamic range,hdr)、宽色域(wide color gamut,wcg)、虚拟现实(virtual reality,vr)和增强现实(augmented reality,ar)。然而视频数据的激增对有限的通信传输带宽和存储资源造成了巨大的压力,因此联合视频专家团队(joint video experts team,jvet)开发了下一代视频编码标准vvc(versatile videocoding)。相较于它的前任,即高效率视频编码hevc(high efficiency video coding),vvc采用了多种新的编码技术,比如,基于四叉树加多类型树(quad-tree plus multi-typetree,qtmt)的编码单元(coding unit,cu)划分结构、宽角度帧内预测(wide angle intraprediction,waip)、位置相关帧内预测组合(position dependent intra predictioncombination,pdpc)、多行参考线(multiple reference line,mrl)预测和帧内子块划分模式(intra sub-partitions mode,isp)等技术。这些新的编码技术使得vvc的编码效率提高了近50%,但同时编码复杂度也大幅增加。导致编码复杂度大幅增加的最主要的原因是基于qtmt的cu划分结构,该划分结构通过递归的率失真优化(rate distortionoptimization,rdo)过程对最优的cu划分结构进行暴力搜索,这使得编码所需的计算量大幅提升。在vvc的帧内编码中,该结构占据了97%的编码时间,因此,近年的许多研究都致力于简化基于qtmt的cu划分过程。
2、本发明所提方法通过融合多个模型对基于qtmt的cu划分进行预测,利用预测结果去除冗余的cu划分模式,以降低rdo过程的计算复杂度,并显著降低vvc帧内编码的编码时间。首先,使用原编码器对视频序列进行编码,在此过程中记录cu的图像数据、特征数据和划分模式,并建立相应的数据集用于训练卷积神经网络(convolutional neuralnetworks,cnn)和轻量级梯度提升机器(light gradient boosting machine,lightgbm)模型;其次,确定cnn模型的结构、用于训练cnn和lightgbm模型的超参数,并加载数据集训练模型;最后,使用编码器加载模型对cu划分模式进行预测,并利用预测结果去除冗余的rdo过程。本发明可用于vvc帧内编码配置下的编码,在确保编码效率损失极少的前提下,显著减少vvc的编码时间。
技术实现思路
1、本发明旨在解决以上现有技术的问题。提出了一种多模型融合的vvc帧内编码快速cu划分方法及存储介质。本发明的技术方案如下:
2、一种多模型融合的vvc帧内编码快速cu划分方法,其包括以下步骤:
3、s1、针对vvc的cu(编码单元)划分结构的特点,设计轻量级的cnn(卷积神经网络)模型用于cu划分模式的预测;
4、s2、选择用于训练lightgbm模型的cu特征;
5、s3、使用vtm(vvc测试参考模型)编码器对视频序列进行编码,采集cu的编码数据,建立训练数据集,对cnn模型和lightgbm模型进行训练;
6、s4、利用步骤s3已训练好的cnn模型和lightgbm模型,对cu划分模式进行预测,选择最优cu划分模式或跳过冗余的cu划分模式,实现cu的快速划分。
7、进一步的,所述步骤s1中,设计轻量级的cnn模型由卷积层conv、最大池化层maxpool、残差块residualblock和平均池化层avgpool组成,其结构依次为:conv、maxpool、residualblock、conv和avgpool。其中,conv的卷积核大小为3×3、步长为1×1以及填充为1,输出连接一个relu和一个batchnorm;maxpool的卷积核大小为2×2,步长为2;avgpool的卷积核大小为1×1。
8、进一步的,所述步骤s2中,选择用于lightgbm模型训练的cu特征包括四个类别的特征,分别为纹理信息、编码信息、上下文信息和子块纹理信息。
9、进一步的,纹理信息包括cu的水平和垂直梯度、方差、熵、偏度和峰度。
10、水平和垂直梯度使用sobel算子进行计算,其计算公式如下:
11、
12、公式(1)中的gh(x,y)和gv(x,y)分别表示坐标(x,y)处像素的水平梯度和垂直梯度;a(x,y)表示以坐标(x,y)为中心的像素矩阵。然后,利用公式(2)计算出当前cu像素水平方向和垂直方向的平均梯度。
13、
14、公式(2)中的|gh(x,y)|和|gv(x,y)|分别为(x,y)坐标处像素的水平梯度和垂直梯度的绝对值;gradientx和gradienty分别为当前cu的水平平均梯度和垂直平均梯度。
15、方差计算公式如下:
16、
17、其中,p(x,y)为cu的亮度分量在(x,y)坐标处的像素值;w和h分别表示cu的宽度和高度;mean为cu像素平均值;variance为cu的像素方差。
18、熵的计算公式如下:
19、
20、其中,l是cu的亮度分量中灰度级的总数;p(i)是灰度级i的归一化概率;entropy为cu图像的熵。
21、偏度和峰度的计算公式如下:
22、
23、其中,n是cu中的总像素数;l是灰度级的总数;xi是灰度级i的像素数;μ是cu的灰度均值;σ是cu的灰度标准差;skewness是cu的偏度值;kurtosis是cu的峰度值。
24、进一步的,编码信息包括:编码的深度、帧内预测模式、帧内预测的率失真代价和isp(帧内子块预测)模式,这些编码信息的获取步骤均是在编码器完成帧内预测之后进行的。
25、进一步的,上下文信息包括:邻域cu的平均四叉树深度、邻域cu的平均多类型树深度、邻域cu的平均水平划分次数和邻域cu的平均垂直划分次数,计算公式如下:
26、
27、其中,qtdepth(x+i,y+i)、mttdepth(x+i,y+i)、hornum(x+i,y+i)和vernum(x+i,y+i)是相对于左上角坐标为(x,y)的cu偏移(i,j)处cu的qt深度、mtt深度、水平划分次数和垂直划分次数;neighavgqtdepth是邻域cu的平均qt深度;neighavgmttdepth是邻域cu的平均mtt深度;neighavghornum是邻域cu的平均水平划分次数;neighavgvernum是邻域cu的垂直划分次数。
28、进一步的,子块纹理信息包括:子块方差和子块方差的差值。子块方差是通过将当前待编码cu进行水平和垂直二叉树划分,并利用公式(3)分别计算每一个子块的方差。子块方差的差值的计算公式如下:
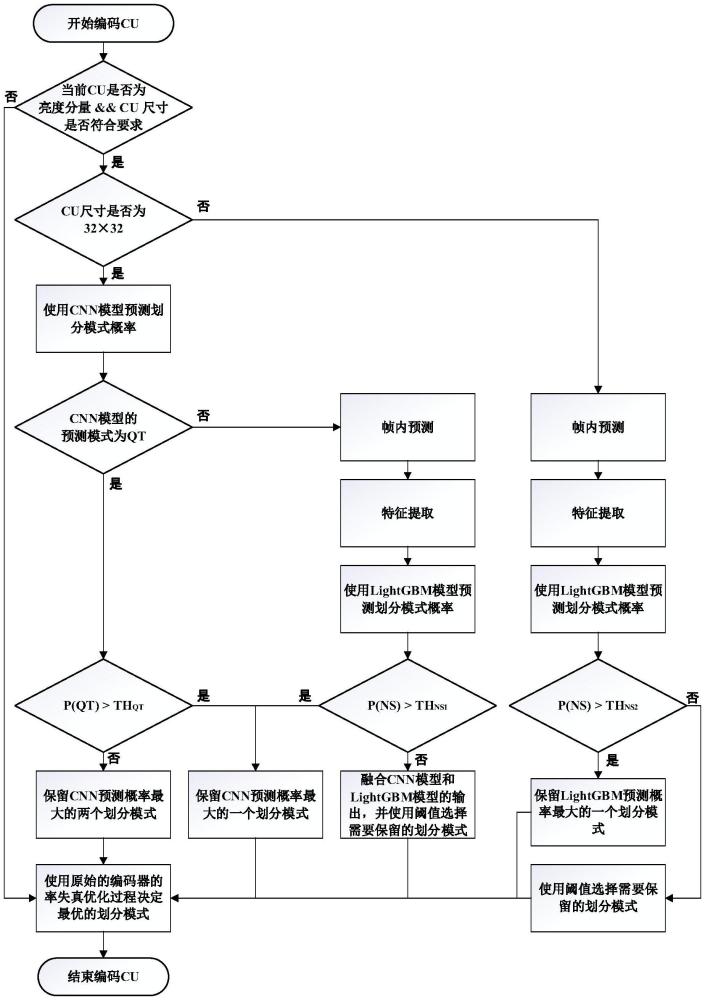
29、
30、其中,varianceabove和variancebelow分别表示将cu进行水平二叉树划分之后两个子块的方差;diffvarhor表示水平二叉树划分的子块方差差值;varianceleft和varianceright表示将cu进行垂直二叉树划分之后两个子块的方差;diffvarver表示垂直二叉树划分的子块方差差值。
31、进一步的,所述步骤s3中,采集cu的编码数据是通过使用vtm编码器对图片或视频序列进行编码来获取的,并在此过程中记录cu的图像数据、特征数据和划分模式。其中,用于采集样本的图片序列包含6种分辨率,分别为:416×240、832×480、1280×720、1920×1080、2560×1600和3840×2160。
32、进一步的,所述步骤s3中,对cnn模型训练所使用的损失函数为:
33、
34、其中,loss为损失;n为类别的总数;pi为第i类的概率;αi是用于平衡第i类的权重系数;γ表示规范难易样本关注度的超参数。
35、进一步的,所述步骤s4中,利用已训练好的cnn模型和lightgbm模型,对cu划分模式进行预测,选择最优cu划分模式或跳过冗余的cu划分模式,实现cu的快速划分的具体过程如下:
36、s41、检查当前待编码cu是否为亮度分量,并且cu尺寸是否符合要求。如果满足,进入步骤s42;否则,进入步骤s48。
37、s42、检查当前待编码cu尺寸是否为32×32。如果满足,进入步骤s43;否则,进入步骤s46。
38、s43、提取cu经滤波后的图像数据作为cnn模型的输入,预测cu的最优化分模式。如果最优划分模式为四叉树划分,进入步骤s44;否则,进入步骤s45。
39、s44、将cnn模型输出的四叉树划分模式的概率与阈值进行比较。如果大于阈值,则直接选择四叉树划分为最优划分模式,进入步骤s48;否则,保留概率最高的两个模式,进入步骤s48。
40、s45、对当前待编码cu使用原编码器进行帧内预测,并且提取纹理信息、编码信息、上下文信息和子块纹理信息作为特征,使用lightgbm模型预测cu的最优划分模式,将不划分模式的概率与阈值进行比较。如果大于阈值,则直接选择不划分为最优划分模式,进入步骤s48;否则,融合cnn模型和lightgbm模型的输出,去除冗余的cu划分模式,进入步骤s48。
41、s46、对于其它尺寸的cu,首先使用原编码器进行帧内预测,并且提取特征,使用lightgbm模型预测cu的最优划分模式,将不划分模式的概率与阈值进行比较。如果大于阈值,则直接选择不划分为最优划分模式,进入步骤s48;否则,进入步骤s47。
42、s47、获取六种划分模式的概率中的最大值,并将六种划分模式的概率依次与该最大值相除,将结果与阈值进行比较。如果结果大于阈值,则保留相应的划分模式,进入步骤s48;否则,去除相应的划分模式。
43、s48、使用原编码器的率失真优化过程决定最优的划分模式,进入步骤s49。
44、s49、结束当前cu的编码。
45、进一步的,所述步骤s41中,满足条件的cu尺寸为32×32、32×16、16×32、16×16、32×8和8×32。
46、进一步的,所述步骤s47中,模型输出的六个概率值分别为:pns、pqt、pbth、pbtv、ptth和pttv,这六个概率值分别对应六种划分模式:不划分、四叉树划分、水平二叉树划分、垂直二叉树划分、水平三叉树划分和垂直三叉树划分。
47、进一步的,所述步骤s47中,首先通过以下公式计算ri:
48、
49、其中,pmax表示输出的概率中的最大值;pi表示其中一种划分模式的概率。然后,将ri与阈值进行比较,如果大于阈值,则保留对应的划分模式的测试;如果小于阈值,则跳过对应的划分模式的测试。
50、一种存储介质,该存储介质内部存储计算机程序,其所述计算机程序被处理器读取时,执行上述任一项所述基于多模型融合的vvc帧内编码快速cu划分方法。
51、本发明的优点及有益效果如下:
52、本发明针对vvc标准实现的视频编码器帧内编码复杂度过高,编码时间过长的问题,提出了一种多模型融合的vvc帧内编码快速cu划分方法。首先,使用原编码器对视频序列进行编码,在此过程中记录cu的图像数据、特征数据和划分模式,并建立相应的数据集用于训练cnn和lightgbm模型;其次,确定cnn模型的结构、用于训练cnn和lightgbm模型的超参数,并加载数据集训练模型;最后,使用编码器加载模型对cu划分模式进行预测,并利用预测结果去除冗余的rdo过程。通过以上步骤可以实现cu快速划分。
53、为了评估本发明所提方法的编码加速性能,本发明在官方编码器vtm-13.0上进行了性能测试,测试标准遵循官方为标准动态范围(standard dynamic range,sdr)视频序列规定的常用测试条件(common test condition,ctc),该ctc中包含22个测试序列,并采用全帧内(all intra,ai)编码配置,在4个量化参数(quantization parameter,qp)值{37,32,27,22}下进行编码性能测试。以bd-br( delta bit-rate)和δt作为加速算法的性能评估指标。bd-br衡量编码效率的损失,其值越大,说明编码效率损失越多;δt表征算法节省时间,其计算公式为:
54、
55、其中,tanchor表示原始编码器的编码时间;ttest表示集成了所提方法的编码器的编码时间。
56、表1展示了22个视频测试序列的编码性能。表1中的proposed表示本发明的方法,ref是对比文献(li t,xu m,tang r,et al.deepqtmt:adeep learning approach forfast qtmt-based cu partition of intra-mode vvc[j].ieee transactions on imageprocessing,2021,30:5377-5390.)中的算法。可以看出,采用本发明的方法能平均减少61.03%的编码时间,而bd-br仅增加了2.09%。从对比结果可知,本文算法综合性能明显优于对比文献算法。
57、表1本发明与参考方法性能对比
58、
59、
60、本发明的创新主要在于权利要求3、权利要求8。采用权利要求3的方法,在编码过程中获取4个类别的特征用于模型训练。采用权利要求8的方法融合lightgbm模型和cnn模型对cu划分进行预测,并且利用预测结果选择最优的划分模式,可以有效简化cu划分过程,去除冗余的cu划分模式测试,降低编码复杂度。本发明充分利用cu的图像信息和编码信息作为特征训练lightgbm模型,并且有效的融合了cnn模型和lightgbm模型,能够更准确的预测cu划分模式,在保证视频编码质量的同时,显著降低了编码时间,因此,本发明中的方法具有较强的创新性和应用价值。
本文地址:https://www.jishuxx.com/zhuanli/20241021/318415.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表