车载语音的控制方法及装置、存储介质、电子装置与流程
- 国知局
- 2024-10-21 14:34:44
本发明涉及人工智能,具体而言,涉及一种车载语音的控制方法及装置、存储介质、电子装置。
背景技术:
1、相关技术中,随着人工智能技术的飞速发展,语音交互技术越来越多地被应用于车载场景,为驾驶员提供更加便捷、智能的交互体验。
2、相关技术中,已经出现了多种语音车控系统,它们通过语音识别技术识别驾驶员的语音指令,并根据预设的控制逻辑完成相应的车辆控制。但是,车载语音交互模型在处理复杂语义、执行多轮交互等方面还存在局限性,语音车控系统大多采用"一刀切"的交互策略,没有考虑不同用户的个性化需求,导致用户体验不佳。
3、针对相关技术中存在的上述问题,暂未发现高效且准确的解决方案。
技术实现思路
1、本发明提供了一种车载语音的控制方法及装置、存储介质、电子装置,以解决相关技术中的技术问题。
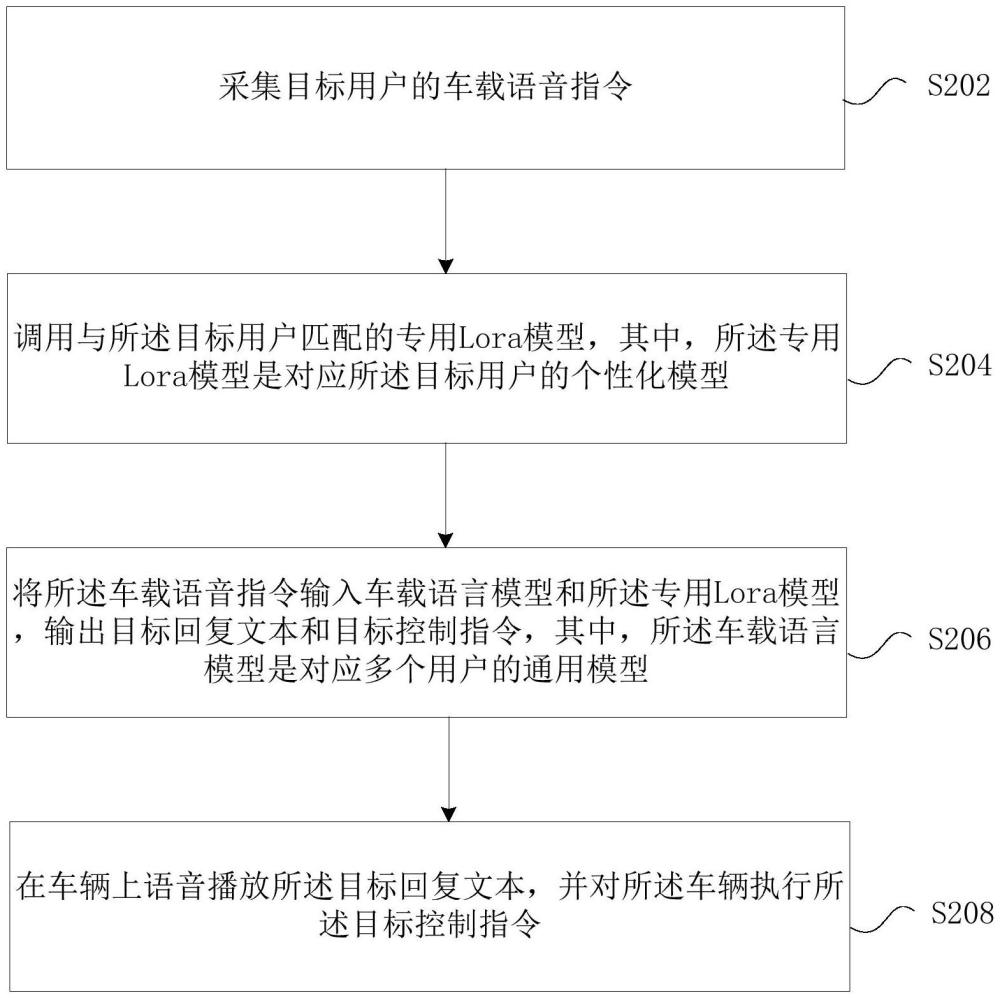
2、根据本发明的一个实施例,提供了一种车载语音的控制方法,包括:采集目标用户的车载语音指令;调用与所述目标用户匹配的专用lora模型,其中,所述专用lora模型是对应所述目标用户的个性化模型;将所述车载语音指令输入车载语言模型和所述专用lora模型,输出目标回复文本和目标控制指令,其中,所述车载语言模型是对应多个用户的通用模型;在车辆上语音播放所述目标回复文本,并对所述车辆执行所述目标控制指令。
3、可选的,将所述车载语音指令输入车载语言模型和lora模型,输出回复文本和控制指令包括:将所述车载语音指令输入车载语言模型,输出中间回复文本和中间控制指令;采用所述lora模型对所述中间回复文本和中间控制指令进行个性化处理,输出目标回复文本和目标控制指令。
4、可选的,将所述车载语音指令输入车载语言模型,输出中间回复文本和中间控制指令,包括:采用所述车载语言模型对所述车载语音指令进行语义解析,得到语义内容;判断所述语义内容是否存在逻辑错误;若所述语义内容不存在逻辑错误,输出与所述车载语音指令匹配的中间回复文本和中间控制指令。
5、可选的,在判断所述语义内容是否存在逻辑错误之后,所述方法还包括:判断所述语义内容存在逻辑错误,输出与所述车载语音指令匹配的纠错回复文本。
6、可选的,在将所述车载语音指令输入车载语言模型和专用lora模型之前,所述方法还包括:获取车载场景数据,其中,所述载场景数据包括以下至少之一:车载语音指令语料、车载知识库、车辆操作手册;采用所述车载场景数据对预置大语言模型进行增量训练,得到所述车载语言模型。
7、可选的,在调用与所述目标用户匹配的专用lora模型之前,所述方法还包括:获取所述目标用户的语言习惯数据和行为习惯数据;采用所述语言习惯数据和所述行为习惯数据训练通用lora模板,得到所述专用lora模型。
8、可选的,获取所述目标用户的语言习惯数据和行为习惯数据包括:读取所述目标用户的个性化语料库、以及读取所述目标用户的历史控车记录,其中,所述个性化语料库包括以下至少之一:常用语、口头禅、专有名词,所述历史控车记录包括以下至少之一:操作偏好信息、控制习惯信息;从所述个性化语料库和所述历史控车记录中提取所述目标用户的语言习惯数据和行为习惯数据。
9、可选的,在车辆上播放所述目标回复文本,并对所述车辆执行所述目标控制指令之后,所述方法还包括:采用所述车载语音指令、所述目标回复文本和目标控制指令生成增量样本数据;将所述增量样本数据添加至样本数据库;按照优先级从所述样本数据库中选择当前更新周期的样本数据集;采用所述样本数据集对所述专用lora模型进行增量训练,并基于训练结果更新所述专用lora模型。
10、可选的,按照优先级从所述样本数据库中选择当前更新周期的样本数据集包括:针对当前更新周期新增的每条目标样本数据,读取所述目标样本数据的置信度,其中,所述置信度用于表征模型输出结果的不确定度;采用所述置信度配置当前更新周期新增的每条样本数据的优先级;按照所述优先级从当前更新周期新增的多条样本数据中选择若干条样本数据,得到样本数据集。
11、可选的,在读取所述目标样本数据的置信度之前,所述方法还包括:将所述车载语音指令输入自然语言理解nlu模型,其中,所述nlu模型包括依次串联的第一层和第二层,所述第一层部署有多个并联的基学习器,所述第二层部署有全域分类模型,每个基学习器对应一个知识领域;采用所述多个并联的基学习器判断所述车载语音指令是否属于对应的知识领域;若所述车载语音指令不属于对应的知识领域,将所述车载语音指令传输至全域分类模型,采用所述全域分类模型判断所述车载语音指令是否属于车控指令;若所述全域分类模型判断所述车载语音指令不属于车控指令,生成所述车载语音指令的置信度。
12、可选的,读取所述目标样本数据的置信度包括:采用词向量模型从向量数据库中获取与样本语音指令匹配的多个召回向量;基于所述多个召回向量的平均值生成词嵌入向量;将所述样本语音指令输入词向量编码层,得到向量矩阵;将所述向量矩阵输入多层卷积层,得到卷积特征,其中,所述多层卷积层包括第一卷积层、第二卷积层、以及第三卷积层,对应的卷积核尺寸分别为3、4、5;将所述卷积特征输入至最大池化层,得到池化特征;将所述池化特征输入至全连接层,输出导航域特征分数;将所述样本语音指令分别输入至多个并联的知识域文本卷积神经网络textcnn模型,对应输出多个知识域特征分数,其中,所述知识域textcnn模型对应一个知识域特征分数;将所述导航域特征分数和所述多个知识域特征分数与所述词嵌入向量进行拼接,得到拼接向量;将所述拼接向量输入至支持向量机svm模型,输出所述目标样本数据的置信度。
13、可选的,在读取所述目标样本数据的置信度之后,所述方法还包括:判断所述目标样本数据的置信度是否超过预设阈值;若所述目标样本数据的置信度超过预设阈值,生成所述目标样本数据的澄清请求;获取所述澄清请求的解释信息,并将所述解释信息补充至所述目标样本数据。
14、可选的,将所述增量样本数据添加至样本数据库包括:将所述增量样本数据添加至样本数据库的当前增量数据块;判断所述当前增量数据块的词元数量是否达到预设数量;若所述当前增量数据块的词元数量达到预设数量,将所述当前增量数据块输出为当前周期的样本数据,并将所述当前增量数据块中最近的若干个词元添加至下一个增量数据块。
15、根据本发明的另一个实施例,提供了一种车载语音的控制装置,包括:采集模块,用于采集目标用户的车载语音指令;调用模块,用于调用与所述目标用户匹配的专用lora模型,其中,所述专用lora模型是对应所述目标用户的个性化模型;处理模块,用于将所述车载语音指令输入车载语言模型和所述专用lora模型,输出目标回复文本和目标控制指令,其中,所述车载语言模型是对应多个用户的通用模型;执行模块,用于在车辆上语音播放所述目标回复文本,并对所述车辆执行所述目标控制指令。
16、可选的,所述处理模块包括:第一处理单元,用于将所述车载语音指令输入车载语言模型,输出中间回复文本和中间控制指令;第二处理单元,用于采用所述lora模型对所述中间回复文本和中间控制指令进行个性化处理,输出目标回复文本和目标控制指令。
17、可选的,所述第一处理单元包括:解析子单元,用于采用所述车载语言模型对所述车载语音指令进行语义解析,得到语义内容;判断子单元,用于判断所述语义内容是否存在逻辑错误;第一输出子单元,用于若所述语义内容不存在逻辑错误,输出与所述车载语音指令匹配的中间回复文本和中间控制指令。
18、可选的,所述第一处理单元还包括:第二输出子单元,用于在所述判断子单元判断所述语义内容是否存在逻辑错误之后,判断所述语义内容存在逻辑错误,输出与所述车载语音指令匹配的纠错回复文本。
19、可选的,所述装置还包括:第一获取模块,用于在所述处理模块将所述车载语音指令输入车载语言模型和专用lora模型之前,获取车载场景数据,其中,所述载场景数据包括以下至少之一:车载语音指令语料、车载知识库、车辆操作手册;第一训练模块,用于采用所述车载场景数据对预置大语言模型进行增量训练,得到所述车载语言模型。
20、可选的,所述装置还包括:第二获取模块,用于在所述调用模块调用与所述目标用户匹配的专用lora模型之前,获取所述目标用户的语言习惯数据和行为习惯数据;第二训练模块,用于采用所述语言习惯数据和所述行为习惯数据训练通用lora模板,得到所述专用lora模型。
21、可选的,所述第二获取模块包括:读取单元,用于读取所述目标用户的个性化语料库、以及读取所述目标用户的历史控车记录,其中,所述个性化语料库包括以下至少之一:常用语、口头禅、专有名词,所述历史控车记录包括以下至少之一:操作偏好信息、控制习惯信息;提取单元,用于从所述个性化语料库和所述历史控车记录中提取所述目标用户的语言习惯数据和行为习惯数据。
22、可选的,所述装置还包括:生成模块,用于在所述执行模块在车辆上播放所述目标回复文本,并对所述车辆执行所述目标控制指令之后,采用所述车载语音指令、所述目标回复文本和目标控制指令生成增量样本数据;添加模块,用于将所述增量样本数据添加至样本数据库;选择模块,用于按照优先级从所述样本数据库中选择当前更新周期的样本数据集;第三训练模块,用于采用所述样本数据集对所述专用lora模型进行增量训练,并基于训练结果更新所述专用lora模型。
23、可选的,所述选择模块包括:读取单元,用于针对当前更新周期新增的每条目标样本数据,读取所述目标样本数据的置信度,其中,所述置信度用于表征模型输出结果的不确定度;配置单元,用于采用所述置信度配置当前更新周期新增的每条样本数据的优先级;选择单元,用于按照所述优先级从当前更新周期新增的多条样本数据中选择若干条样本数据,得到样本数据集。
24、可选的,所述选择模块还包括:输入单元,用于在所述读取单元读取所述目标样本数据的置信度之前,将所述车载语音指令输入自然语言理解nlu模型,其中,所述nlu模型包括依次串联的第一层和第二层,所述第一层部署有多个并联的基学习器,所述第二层部署有全域分类模型,每个基学习器对应一个知识领域;判断单元,用于采用所述多个并联的基学习器判断所述车载语音指令是否属于对应的知识领域;传输单元,用于若所述车载语音指令不属于对应的知识领域,将所述车载语音指令传输至全域分类模型,采用所述全域分类模型判断所述车载语音指令是否属于车控指令;生成单元,用于若所述全域分类模型判断所述车载语音指令不属于车控指令,生成所述车载语音指令的置信度。
25、可选的,所述读取单元还用于:采用词向量模型从向量数据库中获取与样本语音指令匹配的多个召回向量;基于所述多个召回向量的平均值生成词嵌入向量;将所述样本语音指令输入词向量编码层,得到向量矩阵;将所述向量矩阵输入多层卷积层,得到卷积特征,其中,所述多层卷积层包括第一卷积层、第二卷积层、以及第三卷积层,对应的卷积核尺寸分别为3、4、5;将所述卷积特征输入至最大池化层,得到池化特征;将所述池化特征输入至全连接层,输出导航域特征分数;将所述样本语音指令分别输入至多个并联的知识域文本卷积神经网络textcnn模型,对应输出多个知识域特征分数,其中,所述知识域textcnn模型对应一个知识域特征分数;将所述导航域特征分数和所述多个知识域特征分数与所述词嵌入向量进行拼接,得到拼接向量;将所述拼接向量输入至支持向量机svm模型,输出所述目标样本数据的置信度。
26、可选的,所述选择模块还包括:判断单元,用于在所述读取单元读取所述目标样本数据的置信度之后,判断所述目标样本数据的置信度是否超过预设阈值;生成单元,用于若所述目标样本数据的置信度超过预设阈值,生成所述目标样本数据的澄清请求;补充单元,用于获取所述澄清请求的解释信息,并将所述解释信息补充至所述目标样本数据。
27、可选的,所述添加模块还用于:将所述增量样本数据添加至样本数据库的当前增量数据块;判断所述当前增量数据块的词元数量是否达到预设数量;若所述当前增量数据块的词元数量达到预设数量,将所述当前增量数据块输出为当前周期的样本数据,并将所述当前增量数据块中最近的若干个词元添加至下一个增量数据块。
28、根据本技术实施例的另一方面,还提供了一种存储介质,该存储介质包括存储的程序,程序运行时执行上述的步骤。
29、根据本技术实施例的另一方面,还提供了一种电子设备,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;其中:存储器,用于存放计算机程序;处理器,用于通过运行存储器上所存放的程序来执行上述方法中的步骤。
30、本技术实施例还提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述方法中的步骤。
31、本发明的有益效果:
32、1、通过车载语言模型进行车载场景的增量预训练,能够更好地理解车载场景下的自然语言指令,掌握车辆控制的专业知识,生成符合车载场景的对话回复;
33、2、针对每个用户构建个性化的专用lora模型,通过个性化语料和历史交互数据的预训练,能够学习和理解用户的语言习惯、操作偏好等个性化特征,提供量身定制的交互体验;
34、3、在语义理解和回复生成过程中,结合专用lora模型和车载语言模型,既保证了车载领域知识的专业性,又兼顾了用户个性化需求的满足,大大提升了人机交互的自然性和流畅性;
35、4、对用户个性化语料进行专用lora模型的增量训练,在提升个性化服务能力的同时,避免了对车载场景优化模型的干扰,保证了车辆控制功能的稳定性。增量训练和实时交互相互独立,既不影响交互响应速度,又能使个性化lora与用户的新知识、新偏好同步更新。
本文地址:https://www.jishuxx.com/zhuanli/20241021/318643.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表