一种与文本无关的声纹识别方法、装置、电子设备及介质
- 国知局
- 2024-10-21 14:36:05
本发明涉及生物特征识别,尤其涉及一种与文本无关的声纹识别方法、装置、电子设备及介质。
背景技术:
1、声纹识别、人脸识别和虹膜识别等,都是生物特征识别主流技术,然而因为声纹识别的无接触性、便捷性以及低成本等优点,使得它在身份验证场景中的应用变得越来越多,目前广泛应用于安防、医疗、金融以及人机交互等领域中。其中与文本无关的声纹识别应用最为广泛,与传统的文本相关声纹识别相比,文本无关声纹识别不需要事先提供文本内容,而是直接基于说话人的声音特征进行识别。然而,文本无关的声纹识别没有文本内容来帮助识别过程,需要应对不同的发音,因而识别难度大大增加,且文本无关的声纹识别大多在不同场景下,用不同录音设备录制,声音信号的提取更加困难和复杂。
技术实现思路
1、有鉴于此,有必要提供一种与文本无关的声纹识别方法、装置、电子设备及介质,用以解决现有技术中文本无关的声纹识别没有文本内容来帮助识别过程,需要应对不同的发音,因而识别难度大的技术问题。
2、为了解决上述问题,本发明提供一种与文本无关的声纹识别方法,包括:
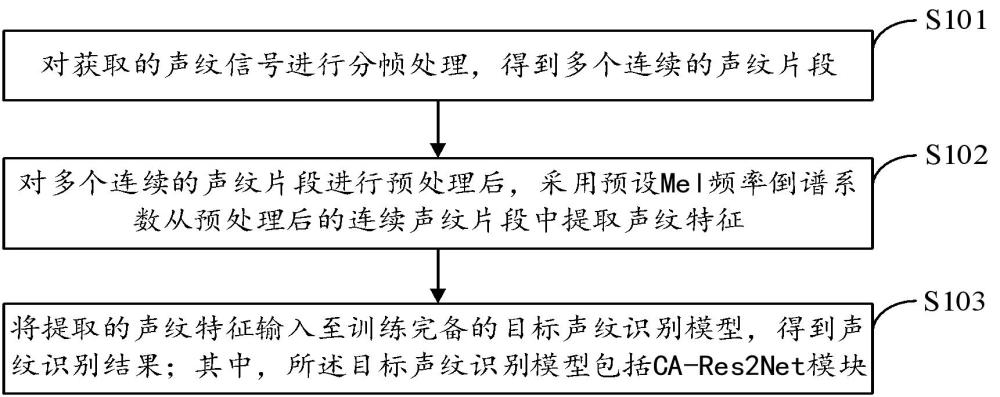
3、对获取的声纹信号进行分帧处理,得到多个连续的声纹片段;
4、对多个连续的声纹片段进行预处理后,采用预设mel频率倒谱系数从预处理后的连续声纹片段中提取声纹特征;
5、将提取的声纹特征输入至训练完备的目标声纹识别模型,得到声纹识别结果;其中,所述目标声纹识别模型包括ca-res2net模块。
6、在一种可能的实现方式中,所述ca-res2net模块包括第一卷积层、res2net扩张卷积层、第二卷积层和坐标注意力机制层;
7、所述第一卷积层用于对像素点进行特征通道变换,得到第一特征声纹信号;
8、所述res2net扩张卷积层用于对第一特征声纹信号进行特征通道均分和扩大,得到多尺度特征信号;
9、所述第二卷积层用于对多尺度特征信号进行通道复原,得到第二特征声纹信号;
10、所述坐标注意力机制层用于对第二特征声纹信号的通道进行加权处理,得到加权声纹信号。
11、在一种可能的实现方式中,所述res2net扩张卷积层包括通道均分层、n个3*3卷积层以及n-1个拼接层;
12、所述通道均分层用于对第一特征声纹信号进行通道数量均分,得到n+1份均分特征声纹信号;
13、所述第一个3*3卷积层用于对第二份均分特征声纹信号进行通道扩张处理,得到第一扩张特征;
14、所述第一个拼接层用于将第一扩张特征与第三份均分特征声纹信号进行拼接,得到第一拼接特征;
15、所述第二个3*3卷积层用于对第一拼接特征进行通道扩张处理,得到第二扩张特征;
16、以此类推,得到n+1个不同尺度的特征。
17、在一种可能的实现方式中,所述目标声纹识别模型还包括第一特征提取层、连接层、多头注意力层、全连接和归一化结构层和加性角度间隔损失函数层;
18、所述第一特征提取层用于对输入的声纹特征进行预处理,得到优化声纹特征;
19、所述连接层用于将经过第一特征提取层和res2net扩张卷积层的声纹信号进行连接,得到连接声纹特征信号;
20、所述多头注意力层用于对连接声纹特征信号进行通道加权处理,得到加权特征;
21、所述全连接和归一化结构层用于对加权特征进行线性处理,得到线性变换特征;
22、所述加性角度间隔损失函数层用于确定线性变换特征与预设阈值特征的损失值。
23、在一种可能的实现方式中,所述加性角度间隔损失函数层可通过如下公式表示:
24、
25、其中表示第 i个说话人特征和第 j类样本标签向量之间的夹角, yi表示 i对应的说话人类别标签向量,表示第 i类说话人特征和它自己标签向量之间的夹角, m为角度裕度参数, s为特征尺度参数, n表示说话人类别数。
26、在一种可能的实现方式中,所述对多个连续的声纹片段进行预处理,包括:
27、对多个连续的声纹片段进行加窗,得到加窗信号;
28、对加窗信号进行离散傅里叶变换,并进行去噪处理,得到去噪后的信号。
29、在一种可能的实现方式中,所述对多个连续的声纹片段进行加窗,得到加窗信号,可通过如下公式表示:
30、
31、其中, w(n)是加窗信号, n表示采样点的位置, n表示帧的采样点总数。
32、第二方面,本发明还提供一种与文本无关的声纹识别装置,包括:
33、获取模块,用于对获取的声纹信号进行分帧处理,得到多个连续的声纹片段;
34、处理模块,用于对多个连续的声纹片段进行预处理后,采用预设mel频率倒谱系数从预处理后的连续声纹片段中提取声纹特征;
35、识别模块,用于将提取的声纹特征输入至训练完备的目标声纹识别模型,得到声纹识别结果;其中,所述目标声纹识别模型包括ca-res2net模块。
36、第三方面,本发明还提供了一种电子设备,包括:处理器和存储器;
37、所述存储器上存储有可被所述处理器执行的计算机可读程序;
38、所述处理器执行所述计算机可读程序时实现如上所述的与文本无关的声纹识别方法中的步骤。
39、第四方面,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现如上所述的与文本无关的声纹识别方法中的步骤。
40、本发明的有益效果是:首先对获取的声纹信号进行分帧处理,得到多个连续的声纹片段;随后对多个连续的声纹片段进行预处理后,采用预设mel频率倒谱系数提取声纹特征;最后将提取的声纹特征输入至训练完备的目标声纹识别模型,得到声纹识别结果;其中,所述目标声纹识别模型包括ca-res2net模块。通过ca-res2net模块对声纹信号进行尺度变换,提高了模型的识别性能,大大提高了说话人身份识别的准确性。
技术特征:1.一种与文本无关的声纹识别方法,其特征在于,包括:
2.根据权利要求1所述的与文本无关的声纹识别方法,其特征在于,所述ca-res2net模块包括第一卷积层、res2net扩张卷积层、第二卷积层和坐标注意力机制层;
3.根据权利要求2所述的与文本无关的声纹识别方法,其特征在于,所述res2net扩张卷积层包括通道均分层、n个3*3卷积层以及n-1个拼接层;
4.根据权利要求2所述的与文本无关的声纹识别方法,其特征在于,所述目标声纹识别模型还包括第一特征提取层、连接层、多头注意力层、全连接和归一化结构层和加性角度间隔损失函数层;
5.根据权利要求4所述的与文本无关的声纹识别方法,其特征在于,所述加性角度间隔损失函数层可通过如下公式表示:
6.根据权利要求1所述的与文本无关的声纹识别方法,其特征在于,所述对多个连续的声纹片段进行预处理,包括:
7.根据权利要求6所述的与文本无关的声纹识别方法,其特征在于,所述对多个连续的声纹片段进行加窗,得到加窗信号,可通过如下公式表示:
8.一种与文本无关的声纹识别装置,其特征在于,包括:
9.一种电子设备,其特征在于,包括:处理器和存储器;
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现如权利要求1-7任一项所述的与文本无关的声纹识别方法中的步骤。
技术总结本发明涉及一种与文本无关的声纹识别方法、装置、电子设备及介质,属于生物特征识别技术领域,其中,该方法包括:对获取的声纹信号进行分帧处理,得到多个连续的声纹片段;对多个连续的声纹片段进行预处理后,采用预设Mel频率倒谱系数从预处理后的连续声纹片段中提取声纹特征;将提取的声纹特征输入至训练完备的目标声纹识别模型,得到声纹识别结果;其中,所述目标声纹识别模型包括CA‑Res2Net模块。本发明解决了现有技术中文本无关的声纹识别没有文本内容来帮助识别过程,需要应对不同的发音,因而识别难度大的技术问题。技术研发人员:张华军,王淑琪,张婉莹,罗崇欣受保护的技术使用者:武汉理工大学技术研发日:技术公布日:2024/10/17本文地址:https://www.jishuxx.com/zhuanli/20241021/318684.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。