一种标签偏移校正方法、装置、设备及存储介质
- 国知局
- 2024-10-21 14:39:48
本发明属于计算机,具体涉及一种标签偏移校正方法、装置、设备及存储介质。
背景技术:
1、传统机器学习方法的成功与核心假设有关,即训练和测试数据来自同一分布的独立和相同的。然而,在一些开放环境应用程序中,数据是以动态的方式收集的。除了数据流的及时性和累积量外,测试(目标)分布总是不同于训练(源)分布。例如,在医学图像分析中,即使症状没有太大的差异,疾病患病率在不同的季节也可能有显著差异。此外,在植物分类中,不同地区流行植物的类型发生了变化,而植物特征差异不大。具体如图1所示,杨树多分布在平原地区,而仙人掌多分布在沙漠地区,因此相应的最优分类器会相应发生变化。这一现象是分布转移的一个重要案例,即标签转移,基于假设源域和目标域的类分布具有不同的比例(p(y)≠q(y)),而每个类别的特征分布是相同的(p(x|y)=q(x|y))。研究表明,标签边际分布的变化可以显著降低传统模型的泛化性能。因此,这种转变给在野外部署的机器学习系统带来了重大挑战。
技术实现思路
1、本发明要解决的技术问题是提供一种能够快速准确地对预测标签进行偏移校正的标签偏移校正方法、装置、设备及存储介质。
2、本发明的内容包括提供一种标签偏移校正方法,包括:
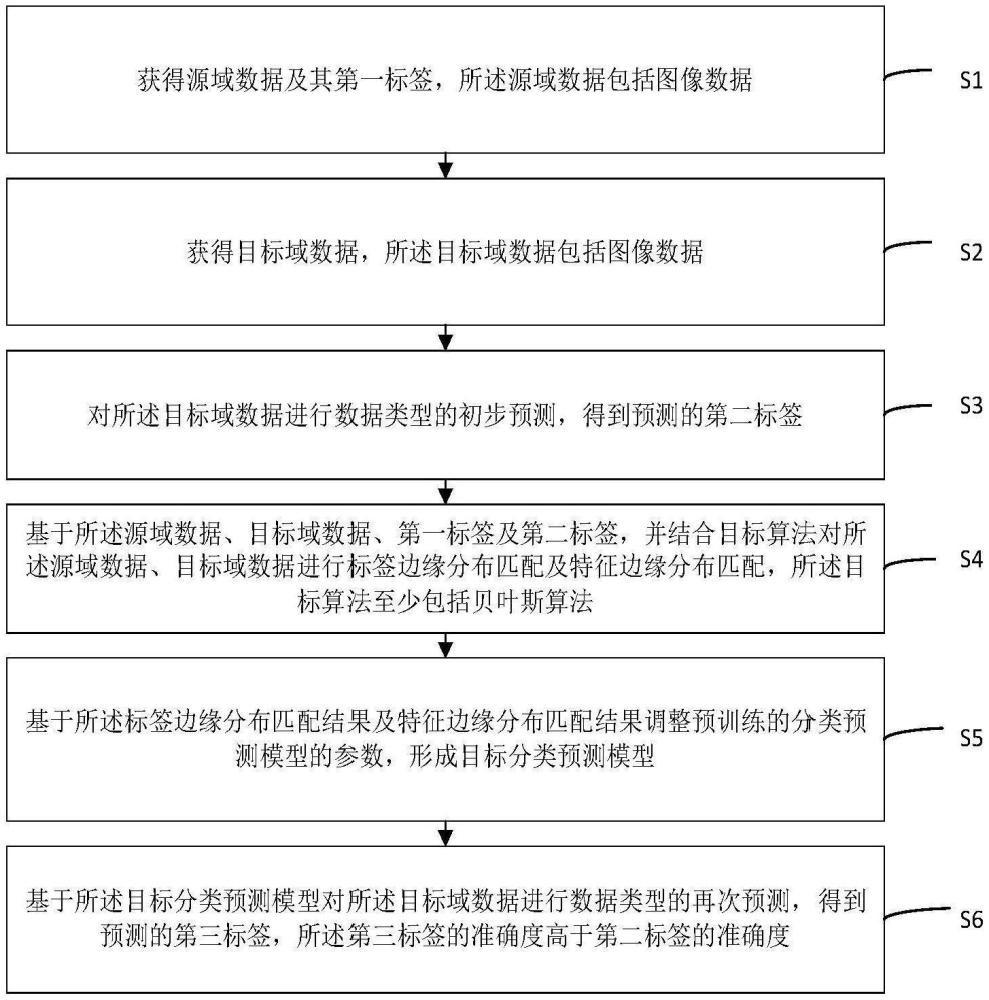
3、获得源域数据及其第一标签,所述源域数据包括图像数据;
4、获得目标域数据,所述目标域数据包括图像数据;
5、对所述目标域数据进行数据类型的初步预测,得到预测的第二标签;
6、基于所述源域数据、目标域数据、第一标签及第二标签,并结合目标算法对所述源域数据、目标域数据进行标签边缘分布匹配及特征边缘分布匹配,所述目标算法至少包括贝叶斯算法;
7、基于所述标签边缘分布匹配结果及特征边缘分布匹配结果调整预训练的分类预测模型的参数,形成目标分类预测模型;
8、基于所述目标分类预测模型对所述目标域数据进行数据类型的再次预测,得到预测的第三标签,所述第三标签的准确度高于第二标签的准确度。
9、作为一可选实施例,所述基于所述源域数据、目标域数据、第一标签及第二标签,并结合目标算法对所述源域数据、目标域数据进行标签边缘分布匹配及特征边缘分布匹配,包括:
10、基于所述第一标签计算得到源域标签分布其中nk为第k个源域样本的数量;
11、构建优化函数:
12、
13、基于所述第二标签、源域标签分布并结合所述优化函数计算得到目标域标签分布;
14、基于所述源域标签分布及目标域标签分布计算得到标签边缘分布匹配。
15、作为一可选实施例,所述基于所述源域数据、目标域数据、第一标签及第二标签,并结合目标算法对所述源域数据、目标域数据进行标签边缘分布匹配及特征边缘分布匹配,包括:
16、基于贝叶斯算法定义加权特征边缘分布簇,所述加权特征边缘分布簇与分类预测模型的参数相关;
17、在源域特征边缘分布与目标域特征边缘分布匹配的前提下,基于所述加权特征边缘分布簇计算得到对应每组匹配的特征的权重向量;
18、基于所述权重向量确定所述源域数据、目标域数据的特征边缘分布匹配。
19、作为一可选实施例,所述加权特征边缘分布簇为:
20、
21、所述θ为所述权重向量,所述权重向量与所述参数正相关。
22、作为一可选实施例,所述权重向量满足下述关系:
23、
24、{ps(x|y=k),k∈[k]};
25、θ*=pt(y);
26、其中,θ与θ*相同。
27、作为一可选实施例,在计算所述权重向量θ时,所述方法还包括:
28、基于投影梯度下降法及拉格朗日乘子法参与求解所述权重向量θ。
29、作为一可选实施例,所述基于所述标签边缘分布匹配结果及特征边缘分布匹配结果调整预训练的分类预测模型的参数,形成目标分类预测模型,包括:
30、基于所述标签边缘分布匹配结果及特征边缘分布匹配结果预估得到真实的目标域数据的标签分布;
31、基于预估得到的标签分布及第一标签调整预训练的分类预测模型的参数,形成目标分类预测模型。
32、本发明另一实施例同时提供一种标签偏移校正装置,包括:
33、第一获得模块,用于获得源域数据及其第一标签,所述源域数据包括图像数据;
34、第二获得模块,用于获得目标域数据,所述目标域数据包括图像数据;
35、第一预测模块,用于对所述目标域数据进行数据类型的初步预测,得到预测的第二标签;
36、计算模块,用于根据所述源域数据、目标域数据、第一标签及第二标签,并结合目标算法对所述源域数据、目标域数据进行标签边缘分布匹配及特征边缘分布匹配,所述目标算法至少包括贝叶斯算法;
37、调整模块,用于根据所述标签边缘分布匹配结果及特征边缘分布匹配结果调整预训练的分类预测模型的参数,形成目标分类预测模型;
38、第二预测模块,用于根据所述目标分类预测模型对所述目标域数据进行数据类型的再次预测,得到预测的第三标签,所述第三标签的准确度高于第二标签的准确度。
39、本发明另一实施例还提供一种电子设备,其特征在于,包括:
40、至少一个处理器;以及,
41、与所述至少一个处理器通信连接的存储器;其中,
42、所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行以实现如上文中任一项实施例所述的标签偏移校正方法。
43、本发明另一实施例还提供一种存储介质,所述存储介质包括存储的程序,其中,在所述程序运行时控制包括所述存储介质的设备执行如上文中任一项实施例所述的标签偏移校正方法。
44、本发明的有益效果在于对正常范畴下的标签偏移校正,效果理想,能够有效改善标签偏移情况,且过程简短,计算量适中,对校正效率提供保证。而从理论上看,本申请的方法能够保证目标函数均有唯一的最优解,即保证偏移校正后的预测标签具有校准后的最优目标标签分布,其为标签移位方法的设计提供了指导,保证预测模型的参数被调整后预测效果优异。
45、本申请的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本申请而了解。本申请的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
46、下面通过附图和实施例,对本申请的技术方案做进一步的详细描述。
技术特征:1.一种标签偏移校正方法,其特征在于,包括:
2.根据权利要求1所述的标签偏移校正方法,其特征在于,所述基于所述源域数据、目标域数据、第一标签及第二标签,并结合目标算法对所述源域数据、目标域数据进行标签边缘分布匹配及特征边缘分布匹配,包括:
3.根据权利要求1所述的标签偏移校正方法,其特征在于,所述基于所述源域数据、目标域数据、第一标签及第二标签,并结合目标算法对所述源域数据、目标域数据进行标签边缘分布匹配及特征边缘分布匹配,包括:
4.根据权利要求3所述的标签偏移校正方法,其特征在于,所述加权特征边缘分布簇为:
5.根据权利要求4所述的标签偏移校正方法,其特征在于,所述权重向量满足下述关系:
6.根据权利要求4所述的标签偏移校正方法,其特征在于,在计算所述权重向量θ时,所述方法还包括:
7.根据权利要求1所述的标签偏移校正方法,其特征在于,所述基于所述标签边缘分布匹配结果及特征边缘分布匹配结果调整预训练的分类预测模型的参数,形成目标分类预测模型,包括:
8.一种标签偏移校正装置,其特征在于,包括:
9.一种电子设备,其特征在于,包括:
10.一种存储介质,所述存储介质包括存储的程序,其中,在所述程序运行时控制包括所述存储介质的设备执行如权利要求1-8中任一项所述的标签偏移校正方法。
技术总结本发明提供一种标签偏移校正方法、装置、设备及存储介质,方法包括:获得源域数据及其第一标签,源域数据包括图像数据;获得目标域数据,目标域数据包括图像数据;对目标域数据进行数据类型的初步预测,得到预测的第二标签;基于源域数据、目标域数据、第一标签及第二标签,并结合目标算法对源域数据、目标域数据进行标签边缘分布匹配及特征边缘分布匹配,目标算法至少包括贝叶斯算法;基于标签边缘分布匹配结果及特征边缘分布匹配结果调整预训练的分类预测模型的参数,形成目标分类预测模型;基于目标分类预测模型对目标域数据进行数据类型的再次预测,得到预测的第三标签。本发明的标签偏移校正方法能够快速准确地对预测标签进行偏移校正。技术研发人员:范瑞东,欧阳宵,侯臣平受保护的技术使用者:中国人民解放军国防科技大学技术研发日:技术公布日:2024/10/17本文地址:https://www.jishuxx.com/zhuanli/20241021/318881.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表