基于SAC和预处理网络的自动驾驶决策规划协同方法及系统与流程
- 国知局
- 2024-10-21 15:01:12
本发明涉及车辆,尤其涉及一种基于sac(soft actor-critic,柔性动作-评价)和预处理网络的自动驾驶决策规划协同方法、一种基于sac和预处理网络的自动驾驶决策规划协同系统、一种计算机可读存储介质和一种车辆。
背景技术:
1、对于实现自动驾驶来讲,一个高效、智能的决策模块至关重要,它不仅要综合考虑所有感知数据,对道路场景进行理解和分析,还要考虑到后续行驶轨迹的规划以及运动控制模块的执行,最终指定最智能、最合适的驾驶策略。目前的自动驾驶决策模块主要是采用基于规则的方法,通常需要手动设计驾驶策略,需要依靠人类过往的驾驶策略经验来制定车辆当前需要执行的驾驶策略,这样的方法存在如下缺点:一、准确性不够高,这种预先定义好的驾驶策略在充满不确定性的交通环境中难以保证;二、普适性不够强,车辆行驶过程中可能会出现五花八门的驾驶场景,针对这种情况需要重新手动设计驾驶策略。
2、现如今随着机器学习的发展,使得基于数据驱动的方法逐渐成为可能,此类方法主要包括模仿学习和深度强化学习;模仿学习存在的缺点是:首先需要收集大量的专家驾驶数据,耗时长、耗费高;其次它只能学习数据集中演示的驾驶技能,遇到数据集未覆盖的情况时,很可能无法处理,容易出现安全问题。但是基于深度强化学习的自动驾驶决策方法在实际应用中仍然存在不足,首先在状态空间、动作空间和奖励函数的设计上存在困难;其次,智能体早期的驾驶策略较为拙劣,学习速度慢,需要耗费大量时间训练;另外,这种方法在自动驾驶系统中常常仅单一替代决策模块,未将规划模块输出的规划路径信息反馈给决策模块,使得决策模块输出的驾驶策略难以充分考虑规划模块的轨迹信息以及车辆的行驶条件约束,因此可能会输出规划、控制模块难以执行的驾驶策略。
技术实现思路
1、本发明旨在至少在一定程度上解决相关技术中的技术问题之一。为此,本发明的第一个目的在于提出一种基于sac和预处理网络的自动驾驶决策规划协同方法,通过预处理网络对车辆的状态空间进行预处理,能够增强智能体对交通场景的理解能力,提高智能体学习速度;在常规奖励的基础上增加反馈奖励,给智能体添加车辆行驶条件约束,并将轨迹信息传递给决策模块,实现决策规划控制的信息协同,使得智能体在做决策时可以充分考虑后续规划过程中的轨迹信息以及规划控制过程中的车辆行驶条件约束,避免决策模块做出规划、控制模块难以执行的决策结果,提高决策的安全性与合理性,从而解决了基于深度强化学习的决策方法学习速度慢、训练时间长以及决策不合理的问题。
2、本发明的第二个目的在于提出一种基于sac和预处理网络的自动驾驶决策规划协同系统。
3、本发明的第三个目的在于提出一种计算机可读存储介质。
4、本发明的第四个目的在于提出一种车辆。
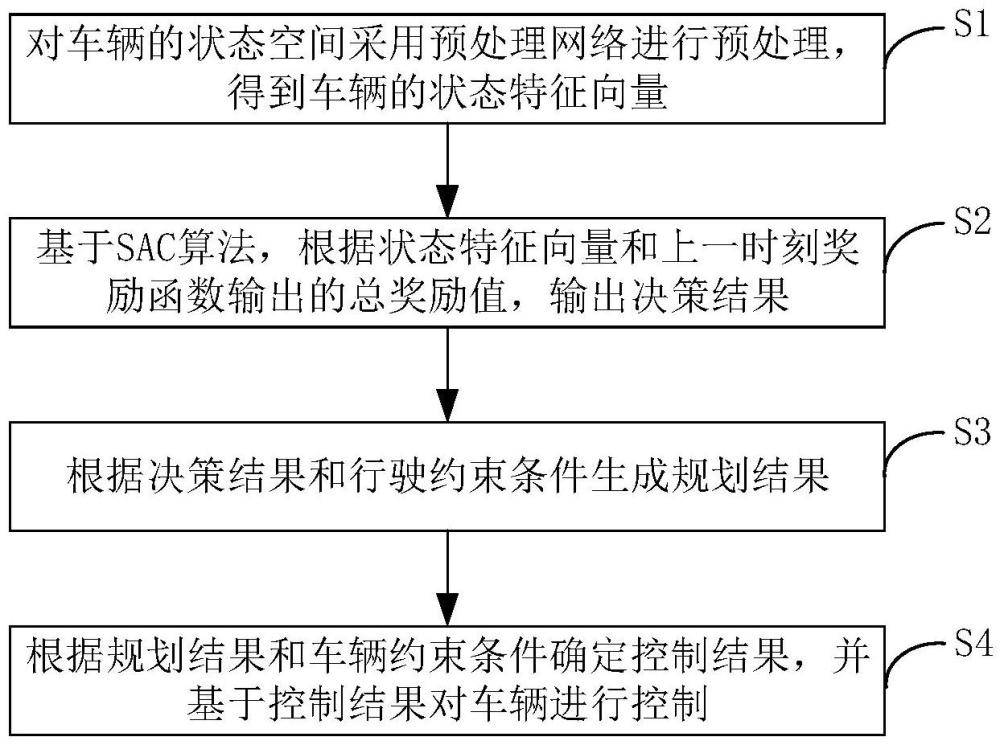
5、为达到上述目的,本发明第一方面实施例提出了一种基于sac和预处理网络的自动驾驶决策规划协同方法,所述方法包括:对车辆的状态空间采用预处理网络进行预处理,得到所述车辆的状态特征向量;基于sac算法,根据所述状态特征向量和上一时刻奖励函数输出的总奖励值,输出决策结果;根据所述决策结果和行驶约束条件生成规划结果;根据所述规划结果和车辆约束条件确定控制结果,并基于所述控制结果对所述车辆进行控制。
6、根据本发明实施例的基于sac和预处理网络的自动驾驶决策规划协同方法,首先对车辆的状态空间采用预处理网络进行预处理,得到车辆的状态特征向量,然后基于sac算法,根据状态特征向量和上一时刻奖励函数输出的总奖励值,输出决策结果,并根据决策结果和行驶约束条件生成规划结果,最后根据规划结果和车辆约束条件确定控制结果,并基于控制结果对车辆进行控制。由此,该方法通过预处理网络对车辆的状态空间进行预处理,能够增强智能体对交通场景的理解能力,提高智能体学习速度;给智能体添加车辆行驶条件约束,并将轨迹信息传递给决策模块,实现决策规划控制的信息协同,使得智能体在做决策时可以充分考虑后续规划过程中的轨迹信息以及规划控制过程中的车辆行驶条件约束,避免决策模块做出规划、控制模块难以执行的决策结果,提高决策的安全性与合理性,从而解决了基于深度强化学习的决策方法学习速度慢、训练时间长以及决策不合理的问题。
7、另外,根据本发明上述实施例的基于sac和预处理网络的自动驾驶决策规划协同方法,还可以具有如下的附加技术特征:
8、根据本发明的一个实施例,获取上一时刻奖励函数输出的总奖励值,包括:基于上一时刻所述规划结果确定规划反馈奖励,其中,所述规划反馈奖励包括s-l曲线评价值、s-t曲线评价值和风险评价值;基于上一时刻所述控制结果确定控制反馈奖励和基础奖励,其中,所述控制反馈奖励包括控制效果评价值;根据所述基础奖励及其对应的权重系数、所述规划反馈奖励对应的权重系数和所述控制反馈奖励及其对应的权重系数,确定所述上一时刻奖励函数输出的总奖励值。
9、根据本发明的一个实施例,所述sac算法的状态空间用下述表达式表达:
10、s=[r,g,p,v]
11、其中,r表示道路结构信息,包括道路宽度、车道边界、道路中心线、速度限制以及路口信息,g表示全局路径信息,p表示预测轨迹信息,包括自车和周围车辆的预测轨迹信息,v表示车辆状态,包括自车和周围车辆的速度、加速度、航向角以及位置信息;根据所述状态空间中的信息,从动作空间中输出所述决策结果。
12、根据本发明的一个实施例,所述行驶约束条件包括:
13、bd1≤l≤bd2
14、vmin≤vp≤vmax
15、
16、at≤μg
17、其中,bd1表示道路的上边界,l表示所述规划结果中的横向位置,bd2表示道路的下边界,vmin表示车辆的最低车速,vp表示所述规划结果中的车速,vmax表示车辆的最高车速,ρ表示路径曲率,rmin表示车辆的最小转弯半径,at表示所述规划结果中的总加速度,μ表示路面附着系数,g表示重力加速度。
18、根据本发明的一个实施例,所述车辆约束条件包括:
19、δmin≤δ≤δmax
20、
21、其中,δmin表示最小转向轮转角,δ表示所述车辆的转向轮转角δmax表示最大转向轮转角,表示最小转向轮转角角速度,所述车辆的转向轮转角角速度,表示最大转向轮转角角速度。
22、根据本发明的一个实施例,所述方法还包括:将所述状态特征向量、所述总奖励值、所述决策结果和下一时刻所述状态特征向量作为决策样本存入所述sac算法的经验池,以便对所述sac算法中的网络参数进行更新。
23、根据本发明的一个实施例,对车辆的状态空间采用预处理网络进行预处理,包括:分别通过批标准化层和线性层对所述状态空间的各状态量进行批归一化处理;分别通过自注意力机制模块获取每个状态量自身元素之间的权重关系;分别通过循环门控单元获取各输入时间依赖关系;将处理后的各状态量叠加后通过所述自注意力机制模块输出所述车辆的状态特征向量。
24、为达到上述目的,本发明第二方面实施例提出了一种基于sac和预处理网络的自动驾驶决策规划协同系统,包括:预处理模块,用于对车辆的状态空间采用预处理网络进行预处理,得到所述车辆的状态特征向量;决策模块,用于基于sac算法,根据所述状态特征向量和上一时刻奖励函数输出的总奖励值,输出决策结果;规划模块,用于根据所述决策结果和行驶约束条件生成规划结果;控制模块,用于根据所述规划结果和车辆约束条件确定控制结果,并基于所述控制结果对所述车辆进行控制。
25、根据本发明实施例的基于sac和预处理网络的自动驾驶决策规划协同系统,预处理模块对车辆的状态空间采用预处理网络进行预处理,得到车辆的状态特征向量;决策模块基于sac算法,根据状态特征向量和上一时刻奖励函数输出的总奖励值,输出决策结果;规划模块根据决策结果和行驶约束条件生成规划结果;控制模块根据规划结果和车辆约束条件确定控制结果,并基于控制结果对车辆进行控制。由此,该装置通过预处理网络对车辆的状态空间进行预处理,能够增强智能体对交通场景的理解能力,提高智能体学习速度;给智能体添加车辆行驶条件约束,并将轨迹信息传递给决策模块,实现决策规划控制的信息协同,使得智能体在做决策时可以充分考虑后续规划过程中的轨迹信息以及规划控制过程中的车辆行驶条件约束,避免决策模块做出规划、控制模块难以执行的决策结果,提高决策的安全性与合理性,从而解决了基于深度强化学习的决策方法学习速度慢、训练时间长以及决策不合理的问题。
26、为达到上述目的,本发明第三方面实施例提出了一种计算机可读存储介质,其上存储有基于sac和预处理网络的自动驾驶决策规划协同程序,该基于sac和预处理网络的自动驾驶决策规划协同程序被处理器执行时实现上述的基于sac和预处理网络的自动驾驶决策规划协同方法。
27、根据本发明实施例的计算机可读存储介质,通过执行上述的基于sac和预处理网络的自动驾驶决策规划协同方法,能够增强智能体对交通场景的理解能力,提高智能体学习速度并能够避免决策模块做出规划、控制模块难以执行的决策结果,提高决策的安全性与合理性,从而解决了基于深度强化学习的决策方法学习速度慢、训练时间长以及决策不合理的问题。
28、为达到上述目的,本发明第四方面实施例提出了一种车辆,包括存储器、处理器及存储在存储器上并可在处理器上运行的基于sac和预处理网络的自动驾驶决策规划协同程序,所述处理器执行所述基于sac和预处理网络的自动驾驶决策规划协同程序时,实现上述的基于sac和预处理网络的自动驾驶决策规划协同方法。
29、根据本发明实施例的车辆,通过执行上述的基于sac和预处理网络的自动驾驶决策规划协同方法,能够增强智能体对交通场景的理解能力,提高智能体学习速度并能够避免决策模块做出规划、控制模块难以执行的决策结果,提高决策的安全性与合理性,从而解决了基于深度强化学习的决策方法学习速度慢、训练时间长以及决策不合理的问题。
30、本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
本文地址:https://www.jishuxx.com/zhuanli/20241021/320192.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表