信息提取方法、装置、电子设备、存储介质和程序产品与流程
- 国知局
- 2024-11-06 14:29:39
本发明涉及计算机 ,特别涉及数据处理,尤其涉及一种信息提取方法、装置、电子设备、存储介质和程序产品。
背景技术:
1、在信息化时代,数据无处不在,而文件作为数据存储和传输的基本单元,承载着大量的结构化和非结构化信息。结构化信息指的是那些具有明确数据结构和层次关系的信息,如json(javascript object notation,js对象简谱,是一种轻量级的数据交换格式)或xml(extensible markup language,可扩展标记语言)文件中的键值对和嵌套结构等。从文件中提取这些结构化信息对于数据分析、数据挖掘、信息检索、自然语言处理以及业务决策等场景至关重要。
2、然而,在从文件中提取结构化信息时,目前常采用的是单线程逐字符解析的方案。通过使用单线程对文件进行逐字符解析,每次只能处理一个字符,无法充分利用现代多核处理器的计算能力。随着文件规模的增大,解析所需的时间会显著增加,导致结构化信息提取的效率低下。
技术实现思路
1、本发明提供一种信息提取方法、装置、电子设备、存储介质和程序产品,用以解决相关技术中信息提取时间长、效率低的缺陷。
2、本发明提供一种信息提取方法,包括:
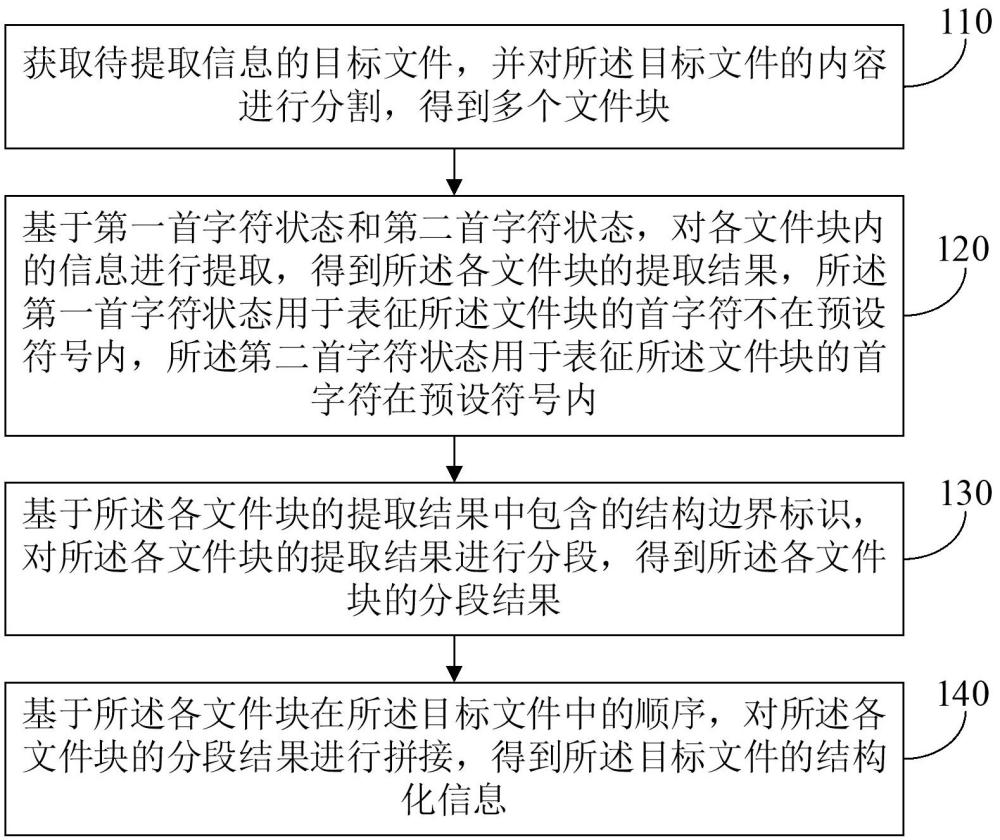
3、获取待提取信息的目标文件,并对所述目标文件的内容进行分割,得到多个文件块;
4、基于第一首字符状态和第二首字符状态,对各文件块内的信息进行提取,得到所述各文件块的提取结果,所述第一首字符状态用于表征所述文件块的首字符不在预设符号内,所述第二首字符状态用于表征所述文件块的首字符在预设符号内;
5、基于所述各文件块的提取结果中包含的结构边界标识,对所述各文件块的提取结果进行分段,得到所述各文件块的分段结果;
6、基于所述各文件块在所述目标文件中的顺序,对所述各文件块的分段结果进行拼接,得到所述目标文件的结构化信息。
7、根据本发明提供的一种信息提取方法,所述基于第一首字符状态和第二首字符状态,对各文件块内的信息进行提取,得到所述各文件块的提取结果,包括:
8、基于所述第一首字符状态和所述第二首字符状态,分别对任一文件块内的信息进行提取,得到各首字符状态对应的提取结果;
9、对所述各首字符状态对应的提取结果进行检查,并将检查通过的提取结果作为所述任一文件块的提取结果。
10、根据本发明提供的一种信息提取方法,所述基于所述第一首字符状态和所述第二首字符状态,分别对任一文件块内的信息进行提取,得到各首字符状态对应的提取结果,包括:
11、遍历任一文件块内的各字符,并基于所述第一首字符状态和所述第二首字符状态中的任一首字符状态,对遍历到的字符进行类型识别;
12、在识别到所述字符的类型为结构化字符的情况下,将所述字符确定为所述结构化字符并记录所述结构化字符的位置;
13、遍历结束后,基于各结构化字符的位置,确定所述各结构化字符之间的从属关系;
14、基于所述各结构化字符的位置和所述各结构化字符之间的从属关系,确定所述任一首字符状态对应的提取结果。
15、根据本发明提供的一种信息提取方法,所述各结构化字符包括所述结构边界标识,所述对所述各首字符状态对应的提取结果进行检查,并将检查通过的提取结果作为所述任一文件块的提取结果,包括:
16、基于所述任一首字符状态对应的提取结果中所述结构边界标识的位置,对所述任一首字符状态对应的提取结果进行检查;
17、在检查到所述任一首字符状态对应的提取结果中所述结构边界标识匹配正确的情况下,确定对所述任一首字符对应的提取结果检查通过。
18、根据本发明提供的一种信息提取方法,所述基于所述各文件块的提取结果中包含的结构边界标识,对所述各文件块的提取结果进行分段,得到所述各文件块的分段结果,包括:
19、基于任一文件块的提取结果中包含的结构边界标识的配对关系和嵌套关系,将所述任一文件块的提取结果分为段前部分、段中部分和段后部分;
20、所述结构边界标识包括开始边界标识和结束边界标识,所述段前部分包括所述结束边界标识,所述段中部分包括成对匹配的所述开始边界标识和所述结束边界标识,所述段后部分包括所述开始边界标识。
21、根据本发明提供的一种信息提取方法,所述基于所述各文件块在所述目标文件中的顺序,对所述各文件块的分段结果进行拼接,得到所述目标文件的结构化信息,包括:
22、基于所述各文件块在所述目标文件中的顺序,将前一文件块的分段结果中的段后部分与后一文件块的分段结果中的段前部分进行拼接,得到多个段中部分;
23、基于所述多个段中部分包括的结构边界标识,确定所述多个段中部分之间的从属关系;
24、基于所述多个段中部分之间的从属关系,将所述多个段中部分进行整合,得到所述目标文件的结构化信息。
25、根据本发明提供的一种信息提取方法,所述对所述目标文件的内容进行分割,得到多个文件块,包括:
26、基于预设尺寸块,读取所述目标文件的内容;
27、基于读取结果,将所述目标文件分割成多个文件块。
28、本发明还提供一种信息提取装置,包括:
29、分割单元,用于获取待提取信息的目标文件,并对所述目标文件的内容进行分割,得到多个文件块;
30、提取单元,用于基于第一首字符状态和第二首字符状态,对各文件块内的信息进行提取,得到所述各文件块的提取结果,所述第一首字符状态用于表征所述文件块的首字符不在预设符号内,所述第二首字符状态用于表征所述文件块的首字符在预设符号内;
31、分段单元,用于基于所述各文件块的提取结果中包含的结构边界标识,对所述各文件块的提取结果进行分段,得到所述各文件块的分段结果;
32、拼接单元,用于基于所述各文件块在所述目标文件中的顺序,对所述各文件块的分段结果进行拼接,得到所述目标文件的结构化信息。
33、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述任一种所述信息提取方法。
34、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述信息提取方法。
35、本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述信息提取方法。
36、本发明提供的信息提取方法、装置、电子设备、存储介质和程序产品,通过将目标文件的内容分割成多个文件块,并引入第一首字符状态和第二首字符状态,可以在处理每个文件块时只需要关注该文件块内部的信息和结构,而无需依赖其他文件块的信息和结构,即对于每个文件块,可以按照该文件块的首字符在预设符号内和不在预设符号内这两种状态,分别对该文件块进行信息提取,由此移除了文件分块处理的状态依赖,使得每个文件块可以独立和并行地进行处理,极大地提高了处理效率,在多核处理器上,这种并行处理方式能够充分利用硬件资源,减少处理时间,显著提升整体性能。此外,通过并行方式对每个文件块进行信息提取后,可以基于各文件块的提取结果中的结构边界标识,对各文件块的提取结果进行分段并拼接,从而整合得到完整的结构化信息,这种结构化信息不仅便于后续的数据处理和分析,还能提高数据的可读性和可用性。
本文地址:https://www.jishuxx.com/zhuanli/20241106/322411.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。