一种语句生成方法、装置、终端设备及存储介质与流程
- 国知局
- 2024-11-06 14:37:47
本申请属于计算机,尤其涉及语句生成方法、装置、终端设备及存储介质。
背景技术:
1、当前人工智能模型广泛应用于各行各业,在通信领域内,技术人员通常使用uie模型(universal lnformation extraction,通用信息抽取统一框架)或其他人工智能模型进行实体抽取,即通过uie模型或其他人工智能模型识别一段行业内文本资料中所包含的实体,其中的实体内容均为通信领域的行业术语。但在uie模型或其他模型投入使用之前,由于uie模型或其他模型无法自动识别出文本内容中的语料,因此需要通过大量的带有语料的语句对uie模型或其他模型进行训练,供uie模型或其他模型学习。领域内采用将文本内容中的语料进行标注的方法,使得uie模型或其他模型通过标注信息识别语料内容,进而通过识别得到的语料内容进行训练,使得训练后的模型能够自动对输入数据中语料进行分析计算。但由于通信行业对信息的保密性要求,无法使用在线模型对行业内的文本内容进行自动标注,只能使用离线模型对行业内的文本内容进行处理,以避免通信数据泄露导致服务提供方与用户方蒙受损失,所以用于训练uie模型或其他模型的大量带有语料的语句全都是依靠技术人员通过标注工具人工标注得到的。
2、通信行业的技术人员通常使用doccano或prodigy或dotat等标注工具对通信领域内的语料信息进行手动标注。其中,doccano是一款流行的基于django的开源文本标注工具,提供了直观的操作界面,便于用户对现有的文本数据添加标签,以实现对于与语句中的语料进行标注;prodigy是一个基于python的闭源收费nlp标注工具,提供了交互式标注功能,便于用户在标注的过程中实时查看标注准确性;dotat是华东理工大学开发的一款面向领域的通用文本标注工具,基于web平台运行,可以为用户提供各类标注选项。
3、但训练uie模型或其他模型需要大量带有语料的语句,无论是doccano还是prodigy抑或是dotat等标注工具均需要工作人员通过人工对现有文本内容中的语句进行语料标注,才能得到带有大量语料的语句,因此工作人员需要耗费大量的人力和时间收集、整理以及标注一条一条的语句,且人工标注无法保障标注的准确性。
技术实现思路
1、有鉴于此,本申请实施例提供了一种语句生成方法、装置、终端设备及存储介质,可以根据预先设定的词汇内容与词汇组合顺序要求,直接生成大量带有语料的语句,并通过语义分析计算生成语句的语义准确率,保障用于供uie模型或其他模型进行训练的语句的准确性,从而解决了通过人工对文本内容手动标注得到训练数据的效率低下以及准确性不高的问题。
2、本申请实施例的第一方面提供了一种语句生成方法,包括:
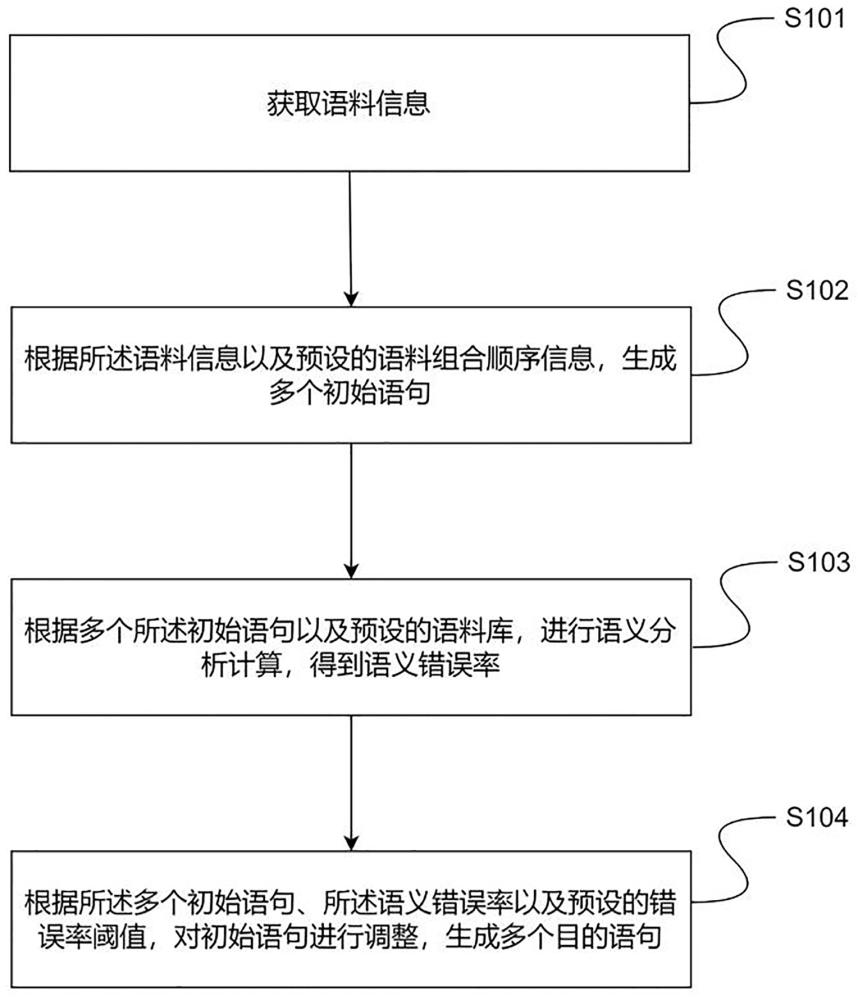
3、获取语料信息;
4、根据所述语料信息以及预设的语料组合顺序信息,生成多个初始语句;
5、根据多个所述初始语句以及预设的语料库,进行语义分析计算,得到语义错误率;
6、根据所述多个初始语句、所述语义错误率以及预设的错误率阈值,对初始语句进行调整,生成多个目的语句。
7、本申请实施例的第二方面提供了一种语句生成装置,包括:
8、语料信息获取模块,用于获取语料信息;
9、初始语句生成模块,用于根据所述语料信息以及预设的语料组合顺序信息,生成多个初始语句;
10、语义错误率计算模块,用于根据多个所述初始语句以及预设的语料库,进行语义分析计算,得到语义错误率;以及
11、目的语句生成模块,用于根据所述多个初始语句、所述语义错误率以及预设的错误率阈值,对初始语句进行调整,生成多个目的语句。
12、本申请实施例的第三方面提供了一种终端设备,所述终端设备包括存储器、处理器,所述存储器上存储有可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述第一方面中任一项所述语句生成方法的步骤。
13、本申请实施例的第四方面提供了一种计算机可读存储介质,包括:存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如上述第一方面中任一项所述语句生成方法的步骤。
14、本申请实施例与现有技术相比存在的有益效果是:本申请能够根据词汇内容与预先设定的词汇组合顺序要求,直接生成大量带有语料信息的语句,并将生成的语句进行语义分析计算,通过对生成的语句进行充分的特征提取与语义特征的分析运算,判定生成语句的语义准确性,进而对初始语句进行调整,从而确保用于供人工智能模型进行训练的语句的数量与准确性,既有效解决了通过人工对文本内容中的语料进行手动标注得到训练数据的效率低下以及准确性不高的问题,又避免了词汇内容中的通信领域文本信息泄露导致服务提供方与用户方蒙受损失。
技术特征:1.一种语句生成方法,其特征在于,包括:
2.如权利要求1所述的语句生成方法,其特征在于,所述语料信息包括时间内容信息、城市内容信息、指标内容信息以及数值内容信息;
3.如权利要求1所述的语句生成方法,其特征在于,所述根据多个所述初始语句以及预设的语料库,进行语义分析计算,得到语义错误率的步骤,具体包括:
4.如权利要求3所述的语句生成方法,其特征在于,所述根据所述初始语句以及所述语义组合句式,进行语义分析计算,得到距离函数值的步骤,具体包括:
5.如权利要求4所述的语句生成方法,其特征在于,所述根据所述初始文本向量、所述权重值矩阵、所述语义组合句式向量以及预设的语义处理模型,计算距离函数值的步骤,具体包括:
6.如权利要求3所述的语句生成方法,其特征在于,所述根据所述多个初始语句、所述语义错误率以及预设的错误率阈值,对初始语句进行调整,生成多个目的语句的步骤,具体包括:
7.如权利要求1所述的语句生成方法,其特征在于,所述根据所述多个初始语句、所述语义错误率以及预设的错误率阈值,对初始语句进行调整,生成多个目的语句的步骤之后,还包括:
8.一种语句生成装置,其特征在于,包括:
9.一种终端设备,其特征在于,所述终端设备包括存储器、处理器,所述存储器上存储有可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如权利要求1至7任一项所述方法的步骤。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述方法的步骤。
技术总结本申请提供了一种语句生成方法、装置、终端设备及存储介质,适用于计算机技术领域,该方法包括:获取语料信息;根据所述语料信息以及预设的语料组合顺序信息,生成多个初始语句;根据多个所述初始语句以及预设的语料库,进行语义分析计算,得到语义错误率;根据所述多个初始语句、所述语义错误率以及预设的错误率阈值,对初始语句进行调整,生成多个目的语句。本申请根据词汇内容与预设的词汇组合顺序,生成带有语料信息的语句,通过对生成的语句进行特征提取与语义特征的分析运算,判定生成语句的语义准确性,从而确保用于供人工智能模型训练的语句的数量与准确性,有效解决通过人工对文本内容中的语料进行标注的效率低下以及准确性不高的问题。技术研发人员:吴元浩受保护的技术使用者:北京资采信息技术有限公司技术研发日:技术公布日:2024/11/4本文地址:https://www.jishuxx.com/zhuanli/20241106/323199.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。