一种利用LLM构建合规风控AI知识库领域的方法与流程
- 国知局
- 2024-11-06 14:42:37
本发明涉及大语言模型,尤其涉及一种利用llm构建合规风控ai知识库领域的方法。
背景技术:
1、在当今信息时代,数据的量级和复杂性日益增加,是在金融、医疗、法律等高风险行业,对于数据的处理和管理提出了更高的要求。在这些领域中,合规性和数据安全是核心关注点。传统上,从非结构化数据源中提取有价值的信息并构建成结构化的知识库通常需要大量的人工参与和监督。这一过程不仅耗时、成本高,而且由于人为因素的参与,容易出现错误和信息遗漏。
2、现有技术在处理非结构化数据,如文本文档、网页内容和社交媒体信息等方面存在一些明显的缺陷。例如,现有的数据抽取方法往往依赖于规则或模板匹配技术,这些技术在面对数据格式多样性和复杂性时,难以适应新的数据类型或快速变化的数据内容,从而导致数据抽取的不准确或不完整。
3、此外,在ai应用中,尤其是涉及敏感信息时(如个人数据、金融记录等),确保数据处理的合规性和安全性是一个重大挑战。传统方法依赖于复杂的合规审查和严格的数据处理规定,这些往往增加了系统的复杂性和操作难度。例如,合规审查过程往往需要跨部门协作,涉及大量的人工审核工作,不仅效率低下,而且容易受到主观判断的影响,难以实现高度的数据使用效率和安全性。因此,如何提供一种利用llm构建合规风控ai知识库领域的方法是本领域技术人员亟需解决的问题。
技术实现思路
1、本发明的一个目的在于提出一种利用llm构建合规风控ai知识库领域的方法,本发明不仅显著提高了从非结构化数据到结构化知识库的转换效率和精度,而且通过智能化的合规性和安全性管理,显著提升了企业的风险管理能力和决策效率。
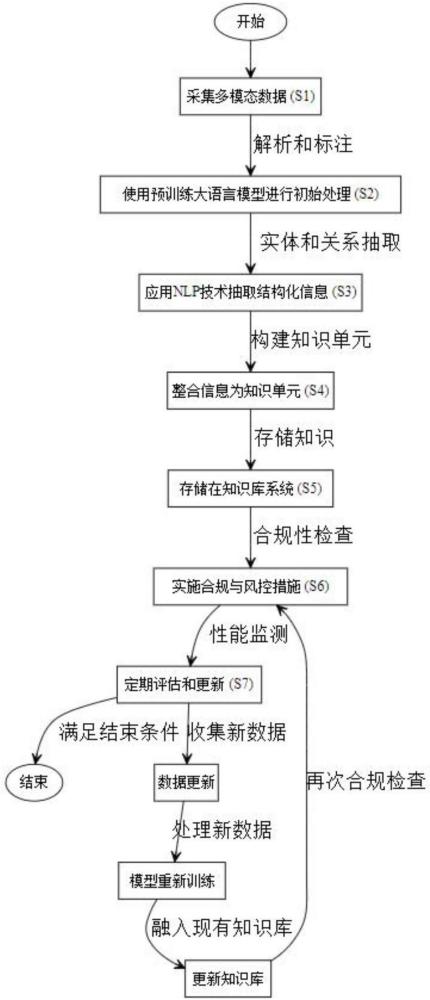
2、根据本发明实施例的一种利用llm构建合规风控ai知识库领域的方法,包括以下步骤:
3、s1、采集多模态数据源,包括音频记录中的语音内容、视频文件中的文本描述和图像中的元数据,以及实时数据流,包括物联网设备和地理信息系统提供的环境数据,构建非结构化数据集;
4、s2、使用预训练的大语言模型对预处理后的非结构化数据集进行初始处理,识别和标记数据中的关键概念、实体和关系;
5、s3、应用自然语言处理技术对步骤s2中的输出进行分析,抽取结构化的信息元素,包括人名、地点、时间和特定领域术语;
6、s4、根据预定规则和模型,将步骤s3中抽取的结构化信息元素整合成知识单元,并建立相应的逻辑和关系链接;
7、s5、将步骤s4中生成的知识单元存储在一个专门设计的知识库系统中,知识库系统支持信息的动态更新和查询处理,并实施数据脱敏处理和访问控制,确认知识库中信息的正确性和安全性;
8、s6、定期评估知识库中存储的信息单元的时效性,根据最新数据重新训练或调整大语言模型,以纳入新的信息和关系。
9、可选的,所述s1包括以下步骤:
10、s11、设定音频采集模块,音频采集模块配置有音频识别算法用于从实时音频流和存储的音频档案中捕获语音内容,通过语音识别技术转换语音数据为文本数据v,并标记出关键词和短语;
11、s12、设定视频分析模块,视频分析模块用于从实时视频流和视频档案中解析文本描述t和图像元数据m,采用图像识别技术识别视频中的图像内容并提取关键视觉元素,同时使用光学字符识别技术从视频中提取文本;
12、s13、配置实时数据采集系统,通过物联网设备和地理信息系统的接口收集环境数据e,并利用传感器从多个源实时收集数据,包括气象数据、地理位置数据和其他环境监测数据;
13、s14、数据整合处理,通过数据整合算法将步骤s11-s13中收集的音频数据v、文本描述t和图像元数据m以及实时数据r合并为一个非结构化数据集u:
14、i={v,t,m,r};
15、其中,u表示整合后的非结构化数据集,v包括由语音转化的文本数据及其关键词标记,t和m包含视频中的文本描述和图像元数据,r包含来自物联网设备和gis的实时数据;
16、s15、对非结构化数据集u进行预处理,包括数据清洗和格式标准化操作。
17、可选的,所述s2包括以下步骤:
18、s21、配置特定于风控领域的预训练大语言模型l经过定制开发以增强其在解析法规、合规条款和敏感数据识别方面的能力;
19、所述配置特定于风控领域的预训练大语言模型包括以下步骤:
20、利用专门收集的法规和合规条款数据集dreg,对大语言模型l进行预训练,形成对特定法律语言和术语的深度理解,公式为:
21、
22、其中,dreg表示法规和合规条款的特定数据集,包含输入文本x和预期输出y(法律概念的标签),hl(x)表示大语言模型l对输入x生成的隐藏层表示,w表示隐藏层到输出层的权重矩阵,表示交叉熵损失函数,用于评估模型输出与真实标签之间的差异,softmax表示激活函数,用于将模型输出转换为概率分布;
23、lpre表示经过专门针对法规和合规条款数据集dreg预训练后的模型,为微调过程提供基础;
24、引入自动化标注工具,通过人工智能技术标注合规条款数据集dreg中的敏感信息点和关键合规需求,以自动生成训练标签treg,进一步训练大语言模型l以识别和解析类似数据;
25、
26、其中,treg表示包含训练标签的法规数据,用于微调模型,λ表示正则化参数,用于平衡数据拟合与模型复杂度,ω(l)表示模型的正则化项,帮助防止过拟合;
27、采用上下文感知的学习机制,通过分析数据集中的关键词与上下文之间的关系,自动调整大语言模型l的参数以更准确地识别和理解数据集u中的合规和风控相关内容。通过连续反馈循环来不断优化模型的性能,公式为:
28、
29、其中,lft表示微调后的模型,基于此模型进行上下文感知的优化,c(u)表示从数据集u中提取的上下文元素集合,pred(c|u,lft)表示大语言模型lft基于上下文c和数据集u的预测输出,γ表示权衡上下文预测误差与模型行为调整的参数,ψ(lft,u)表示模型行为的上下文依赖性调整函数,用于根据数据集u中的实际内容调整模型行为;
30、s22、利用定制的自适应训练技术对大语言模型l进行微调,以根据非结构化数据集u中的实际内容动态调整识别参数,从而优化关键概念c、实体e和关系r的提取,相对于现有技术来说,我们创新性的使用损失函数对模型进行微调:
31、
32、其中:
33、
34、s23、通过进一步的引入一个多层级识别框架,首先识别高级别的法律和合规概念,随后识别具体的个人信息和财务事项,以确保数据集u中所有敏感和关键信息的准确标记:
35、
36、其中,βh是第h层的权重,强化层级的影响力,是第h层的损失函数,predh是第h层的预测函数,用于识别相应层级的信息;
37、s24、结合实体关系图扩展技术,通过分析数据集u中的上下文关系和数据依赖,自动推断和验证实体之间的隐式关系r,并将这些关系明确化:
38、
39、其中,δ是平衡推断准确性和模型的行为调整,infer是基于模型ladaptive和上下文u推断关系r的函数,ξ表示关系推断的上下文调整函数;
40、s25、将步骤s22至s24中识别和提炼的概念c、实体e和关系r转化为半结构化的知识单元,并构建初步的知识图谱k,公式为:
41、
42、其中,θ是将识别的概念、实体和关系转化为知识单元的函数,σc,σe,σr是转换概念、实体和关系的权重参数。
43、可选的,所述s3包括以下步骤:
44、s31、应用命名实体识别技术处理大语言模型ladaptive的输出,识别数据集u中的关键信息元素,并提取人名p,地点l,时间t和特定领域术语s作为结构化的信息元素,公式为:
45、estruct={p,l,t,s};
46、其中,estruct代表抽取的结构化信息元素集合,p表示人名,l表示地点,t表示时间,s表示特定领域术语;
47、s32、使用上下文分析技术进一步验证和精确这些信息元素的相关性和正确性,确保每个元素的准确性和一致性;
48、s33、对抽取的元素进行关联性分析,以确定它们之间的逻辑和空间关系,进一步丰富数据的语义层次;
49、s34、最终将步骤s31和s33中提取和分析后的结构化信息元素整合入知识库系统k,增强知识库的信息完整性和查询效率,本步骤中我们为了改进现有技术的缺陷考虑到必须维护信息的一致性和逻辑关系,我们创新性的引入一个综合评估和整合函数,不仅处理简单的数据合并,还考虑了数据的语义关联性、数据完整性校验和优化知识库的存储结构:
50、k′=φ(k,estruct,α,β,γ);
51、其中,k'表示更新后的知识库,φ表示一个复合函数,负责整合和优化知识库内容,k是现有的知识库,α,β,γ是权重参数,用于控制人名p,地点l,时间t和特定领域术语s在知识库中的优先级和影响力;
52、公式中的φ函数进一步定义为:
53、
54、其中,ψ是一个整合函数,负责将单个信息元素e整合进k,同时保持k的结构和语义完整性,参数控制e在k中的表示方式和连接强度。
55、我们不仅简单地合并数据,而是在合并时维护和强化知识库k的语义结构,增加其对查询的响应性和数据的准确性,适用于本发明所需的高度精确和可靠信息的合规风控ai知识库构建。
56、可选的,所述s4包括以下步骤:
57、s41、接收结构化信息元素集合estruct={p,l,t,s},应用预定的规则和模型,对每个结构化信息元素e进行处理,以形成知识单元ku,规则基于元素的类型和内容确定如何将其与现有知识单元链接或整合,其中:
58、
59、其中,κ是一个构建知识单元的函数,r表示预定的关系规则,θ是规则参数,用于调整信息元素在知识单元中的表达;
60、s42、对步骤s41中生成的知识单元ku实施逻辑和关系链接,确保新的知识单元能够适当反映出信息元素之间的内在联系和依存关系,包括使用逻辑推理和关联分析技术来建立和验证这些链接,以形成一个综合的知识网络kn:
61、kn=ρ(ku,λ);
62、其中,ρ是一个链接构建函数,用于在知识单元之间创建关系和逻辑链接,λ是链接参数,用于控制链接的强度和种类;
63、s43、将步骤s42中形成的综合知识网络kn存储于知识库系统k'中,更新和优化知识库的内容和结构,同时考虑各种不同类型的知识单元以及他们之间的关系,引入一个动态权重系统,权重是基于信息元素的紧急性和重要性自动调整的:
64、k″=ψ(k′,kn,ω,λ,μ);
65、其中,k'是前一步骤的知识库状态,ψ是一个复合函数,管理如何将新的知识网络kn整合进现有知识库k',同时保留历史数据的完整性和最新数据的即时性,函数定义为:
66、
67、其中,ω是权重集,其中包括每个元素的权重,ω是一个从k'和kn中识别出需要处理的语义冲突集合,φ(s)是一个解决知识库中冲突的函数,依据冲突的类型和影响的严重性加权处理,μs是冲突s的解决策略的权重,用于平衡解决方案的优先级和资源分配。
68、可选的,所述s6包括以下步骤:
69、s61、定期评估知识库k”中存储的信息单元的时效性和准确性,使得知识库内容与最新的法规、市场动态和行业标准保持一致;
70、s62、标定数据评估周期δt,在每个周期结束时执行自动数据评估,使用评估算法来检测过时或不准确的知识单元;
71、
72、其中,τ(k″,δt)表示对知识库k”进行评估的函数,k表示知识单元,t表示当前时间,tk是知识单元k上次更新时间,τk是知识单元k的预定生命周期,α(k,t)是一个基于内容的评估权重函数,反映信息单元随时间而降低的相关性和准确性;
73、s63、收集最新数据并对大语言模型lupdated进行重新训练或调整,纳入新信息和新发现的关系,确保模型的输出与当前环境保持一致;
74、s64、应用更新过的大语言模型lupdated重新分析现有的知识单元和新收集的数据,产生更新后的知识单元和关系:
75、
76、其中,lupdated为更新后的模型,β是学习率,ladaptive表示在新数据集dnew上进行梯度下降更新,l是一个损失函数,包括多项式的误差项和正则化项评估模型输出与预期输出之间的差异;
77、s65、将更新后的知识单元和关系整合回知识库k”,形成最终更新后的知识库:
78、
79、其中,θ是一个转化函数,它根据每个信息元素k和其动态权重ω(k)转化信息为知识单元,s是一个从k”和更新后的知识单元中识别出的特殊处理需要的语义冲突集合。
80、本发明的有益效果是:
81、多模态数据集成:通过采集音频、视频和实时数据流,结合物联网设备和地理信息系统,本发明能够从多种数据源整合丰富的信息。多模态集成增强了知识库的信息维度和深度,提供了更全面的数据支持。
82、高精度实体和关系识别:利用定制开发的大语言模型,针对风控领域进行优化,增强了模型在解析法规、合规条款和敏感数据识别方面的能力。确保了抽取的信息不仅精确,还符合特定行业的合规要求。
83、结构化信息抽取与验证:应用命名实体识别技术和上下文分析,有效提取并验证人名、地点、时间等关键信息,保证了信息元素的准确性和一致性。
84、知识单元的智能整合与逻辑构建:通过预定的规则和模型,智能地将结构化信息元素转化为知识单元,并建立复杂的逻辑和关系链接。这不仅提高了知识库的查询效率,还增强了数据间的逻辑关联,支持更复杂的数据分析和决策支持。
85、动态学习与知识库更新:通过定期评估知识库内容的时效性并重新训练大语言模型,本发明能够灵活应对快速变化的外部环境,确保知识库内容始终保持最新状态。动态更新机制适合于法规和市场条件频繁变。
本文地址:https://www.jishuxx.com/zhuanli/20241106/323665.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。