老人健康风险预测系统及方法与流程
- 国知局
- 2024-11-18 18:21:51
本发明涉及健康风险预测,具体为老人健康风险预测系统及方法。
背景技术:
1、老年人关怀措施,如医疗服务、社交活动和心理支持,能提高老年人的生活质量,使他们在晚年生活得更健康、更快乐,这不仅对个人有益,也能减少家庭和社会的负担,对他们的关怀反映了社会的包容性和公平性,预防性健康措施和及时的医疗干预可以减少老年人的疾病发生率和严重程度,从而降低社会整体的医疗支出。
2、通过预测老年人可能面临的残疾风险,医疗和护理机构可以提前采取预防措施,延缓或防止残疾的发生,还可以帮助制定个性化的健康管理方案,针对每位老年人的具体需求提供定制化的护理服务,从而提高护理效果和老年人生活质量,准确的风险预测可以帮助医疗和护理机构更有效地分配资源,将有限的资源集中用于最需要的老年人群体,从而提高服务效率和效益。
3、因此,老年人关怀包括定期健康检查、心理支持和生活指导等多方面内容,而残疾风险预测是其中的重要组成部分,两者结合可以全面提升老年人的健康水平,因此随着科技发展,逐渐完善了针对老人的健康风险预测系统及方案。
4、但是,一般的,传统方案缺乏完整的数据处理流程,导致模型输入的数据质量不高,忽视数据不平衡问题,没有采取针对性的方法进行数据平衡处理,导致模型在预测少数类样本时性能不佳,容易产生偏差,不平衡数据会显著影响模型性能,在老年人口中,相对较低的失能率导致正常样本和失能样本的比例失衡,如果老年人的失能率为20%,即使模型预测所有结果都是正常的,仍然会有0.8的准确率,这显然是不正确的,这种不平衡也导致模型倾向于更频繁地预测正常样本,从而在预测残疾样本时表现出更低的准确性,这种单一的预测模型还会进一步导致预测能力受限,同时,还缺乏对预测结果的解释功能,无法清晰地说明模型预测的依据和特征贡献,缺乏灵活的部署与应用方式,无法提供api接口或友好的用户界面,使得预测结果的获取和使用受到限制。
5、综上,需要提出老人健康风险预测系统及方法来解决上述问题。
技术实现思路
1、本发明的目的在于提供老人健康风险预测系统及方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:
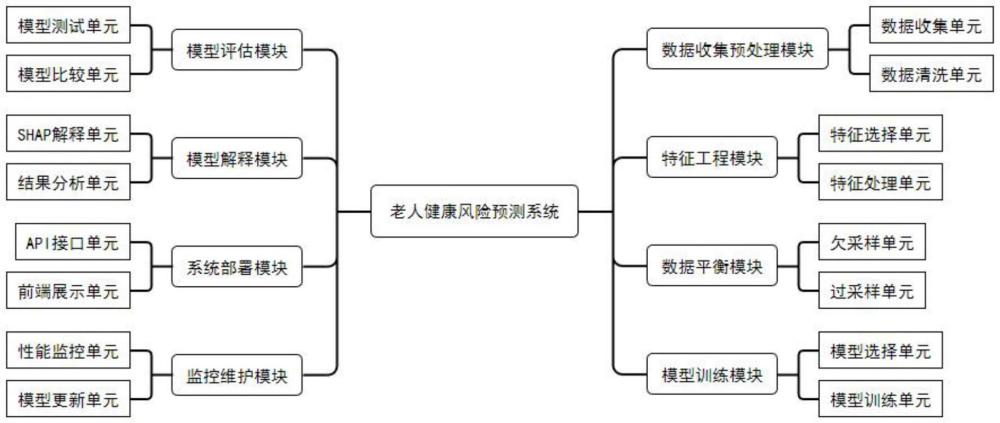
3、老人健康风险预测系统,包括数据收集预处理模块、特征工程模块、数据平衡模块、模型训练模块、模型评估模块、模型解释模块、系统部署模块以及监控维护模块;
4、所述数据收集预处理模块用于从charls项目数据库中提取charls项目组2023年11月16日公布的第五期代表中国45岁及以上中老年人家庭和个人的高质量微观数据的纵向研究数据和数据清洗,所述数据收集预处理模块还包括数据收集单元和数据清洗单元,所述数据收集单元用于从charls项目数据库中收集第五期数据,包括家庭和个人的微观数据以及自我报告变量,所述数据清洗单元使用pandas工具进行数据清洗,填补缺失值或删除异常数据,用于处理数据中的缺失值、异常值和重复值,确保数据的完整性和准确性;
5、所述特征工程模块用于特征选择和特征处理;
6、所述数据平衡模块用于通过欠采样和过采样减少数据不平衡;
7、所述模型训练模块用于选择逻辑回归、k-近邻、朴素贝叶斯、多层感知器、随机森林以及xgboost进行模型构建与训练;
8、所述模型评估模块用于模型测试和比较;
9、所述模型解释模块用于使用shap值解释模型的预测结果进行结果分析;
10、所述系统部署模块用于使用flask或django开发restful api并提供友好的用户交互界面;
11、所述监控维护模块用于性能监控和模型更新。
12、优选地,所述特征工程模块还包括特征选择单元和特征处理单元;
13、所述特征选择单元用于根据自我报告的变量选择相关特征;
14、所述特征处理单元使用standardscaler、minmaxscaler工具处理特征,用于对选择的特征进行标准化、归一化或类别编码,准备用于机器学习模型。
15、优选地,所述数据平衡模块还包括欠采样单元和过采样单元;
16、所述欠采样单元使用randomundersampler进行欠采样处理,用于对多数类样本进行欠采样,减少数据不平衡;
17、所述过采样单元使用smote技术生成新的少数类样本,用于对少数类样本进行过采样,增加数据平衡。
18、优选地,所述模型训练模块还包括模型选择单元和模型训练单元;
19、所述模型选择单元导入相应的机器学习库并初始化模型,用于选择机器学习算法,包括逻辑回归、k-近邻、朴素贝叶斯、多层感知器、随机森林以及xgboost;
20、所述模型训练单元使用训练数据集进行模型训练,并调整超参数以优化性能,用于在平衡后的数据集上训练各个模型。
21、优选地,所述模型评估模块还包括模型测试单元和模型比较单元;
22、所述模型测试单元用于在测试集上评估模型的预测性能,计算准确率、召回率、f1分数指标;
23、所述模型比较单元通过roc曲线、混淆矩阵进行模型比较,用于比较不同模型的性能,选择表现最佳的模型。
24、优选地,所述模型解释模块还包括shap解释单元和结果分析单元;
25、所述shap解释单元应用shap库生成解释报告,用于通过shap值解释模型的预测结果,了解各个特征对预测的贡献;
26、所述结果分析单元基于shap解释结果,进行风险分析,用于分析模型预测的残疾风险结果,识别高风险个体。
27、优选地,所述系统部署模块还包括api接口单元和前端展示单元;
28、所述api接口单元使用flask或django开发restful api,使系统可以被外部应用调用;
29、所述前端展示单元使用react、vue前端框架进行开发,用于开发用户界面,展示预测结果和风险分析报告。
30、优选地,所述监控维护模块还包括性能监控单元和模型更新单元;
31、所述性能监控单元使用prometheus或grafana进行性能监控,用于实时监控系统的运行性能,检测潜在问题;
32、所述模型更新单元根据新数据重新训练和评估模型,部署更新后的模型,用于定期更新模型,确保其准确性和可靠性。
33、基于上述系统,本发明还提出一种老人健康风险预测方法,包括以下步骤:
34、s1.准备数据,从charls项目数据库中收集第五期数据,包括家庭和个人的微观数据及自我报告变量,处理数据中的缺失值、异常值和重复值,确保数据的完整性和准确性,将数据集划分为训练集和测试集,比例为80%训练集,20%测试集;
35、s2.进行特征工程建设,从自我报告的变量中选择关键特征,包括握力、精神状况、婚姻状况、呼吸功能和年龄,对选择的特征进行标准化、归一化或类别编码,确保特征适合用于机器学习模型;
36、s3.在数据平衡阶段,对多数类样本进行欠采样,减少数据不平衡,使用smote技术对少数类样本进行过采样,生成新的少数类样本以平衡数据集;
37、s4.选择逻辑回归、k-近邻、朴素贝叶斯、多层感知器、随机森林以及xgboost进行模型构建与训练,在平衡后的数据集上训练各个模型,调整超参数以优化性能;
38、s5.模型评估,在测试集上评估模型的预测性能,计算准确率、召回率、f1分数指标,比较不同模型的性能,选择表现最佳的模型;
39、s6.进行模型解释,使用shap值解释模型的预测结果,了解各个特征对预测的贡献,分析模型预测的残疾风险结果,识别高风险个体;
40、s7.系统部署与应用,使用flask或django开发restful api,使系统可以被外部应用调用,开发用户界面,展示预测结果和风险分析报告;
41、s8.实时监控系统的运行性能,检测潜在问题,定期更新模型,确保其准确性和可靠性。
42、与现有技术相比,本发明的有益效果是:本发明通过从charls项目数据库中收集第五期数据,并使用pandas进行数据清洗,填补缺失值或删除异常数据,确保了数据的时效性、完整性和准确性,采用欠采样和过采样技术来处理数据不平衡问题,通过减少多数类样本和生成新的少数类样本,提高了模型在不平衡数据集上的泛化能力,还支持包括逻辑回归、k-近邻、朴素贝叶斯、多层感知器、随机森林以及xgboost的训练模型,通过在平衡后的数据集上训练并评估这些模型,选择性能最佳的模型进行预测,利用shap值对模型的预测结果进行解释,能够清晰地了解各个特征对预测结果的贡献,同时,本发明还具备api接口和前端展示功能,可以方便地被外部应用调用,并提供用户友好的界面展示预测结果和风险分析报告,提高了系统的可用性和适用性。
本文地址:https://www.jishuxx.com/zhuanli/20241118/328416.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。