一种基于可控情感强度的语音编辑方法及装置
- 国知局
- 2024-11-19 09:55:14
本发明涉及语音信号处理,具体的是一种基于可控情感强度的语音编辑方法及装置。
背景技术:
1、情感语音编辑旨在通过调整和转换语音中的情感元素,提升语音的自然度和情感表达效果。这项技术在增强人机交互体验、提高虚拟角色的逼真度以及改善听觉娱乐产品的情感表现力方面具有重要意义。然而,实现真实和多样化的情感表达是一项极具挑战性的任务。
2、目前,情感语音编辑技术主要基于自编码器框架,特别是序列到序列(seq2seq)模型。这类模型通过学习输入语音和目标情感语音之间的映射关系,实现情感转换。然而,这些模型在实际应用中常面临情感表达不足和自然度欠缺等问题。尤其是在情感强度控制方面,现有技术存在明显的局限。大多数情感语音编辑系统只能实现固定情感类别的转换,缺乏对情感强度的精细控制。例如,在表达愤怒情感时,难以根据具体需求调整愤怒的强烈程度,从而限制了生成音频的表现力和多样性。
技术实现思路
1、为解决上述背景技术中提到的不足,本发明的目的在于提供一种基于可控情感强度的语音编辑方法及装置,根据情感类别与强度数值动态调整语句的语调和节奏变化,使得编辑后的语音更加真实、自然。
2、第一方面,本发明的目的可以通过以下技术方案实现:一种基于可控情感强度的语音编辑方法,方法包括以下步骤:
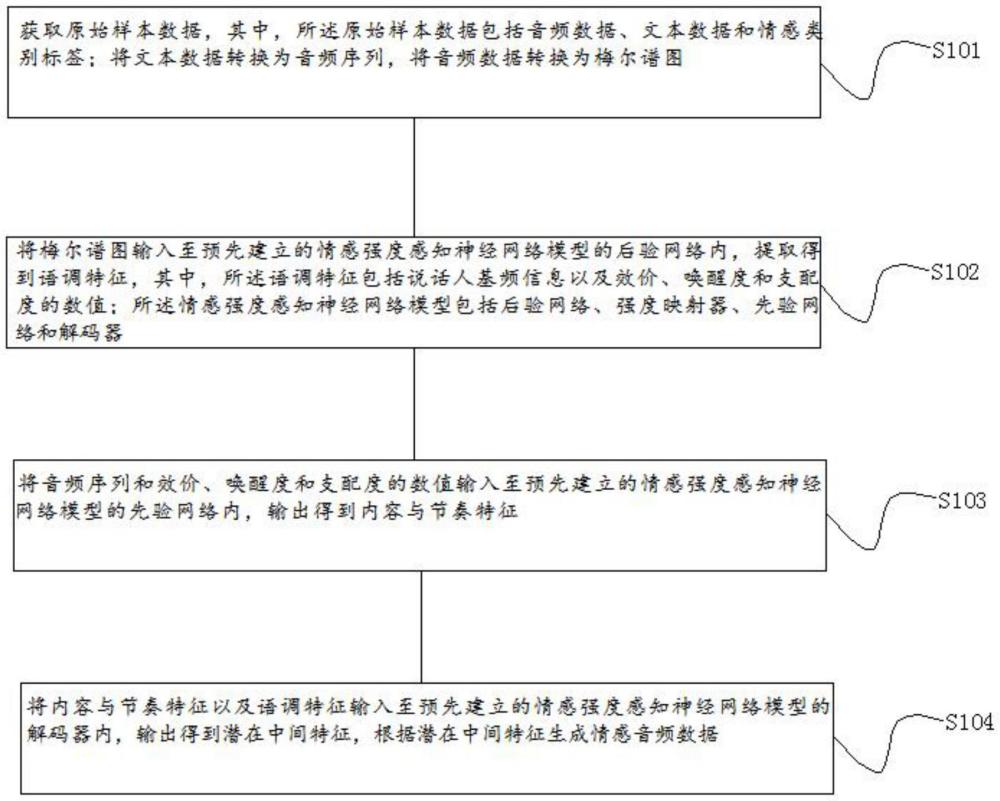
3、获取原始样本数据,其中,所述原始样本数据包括音频数据、文本数据和情感类别标签;将文本数据转换为音频序列,将音频数据转换为梅尔谱图;
4、将梅尔谱图输入至预先建立的情感强度感知神经网络模型的后验网络内,提取得到语调特征,其中,所述语调特征包括说话人基频信息以及效价、唤醒度和支配度的数值;所述情感强度感知神经网络模型包括后验网络、强度映射器、先验网络和解码器;
5、将音频序列和效价、唤醒度和支配度的数值输入至预先建立的情感强度感知神经网络模型的先验网络内,输出得到内容与节奏特征;
6、将内容与节奏特征以及语调特征输入至预先建立的情感强度感知神经网络模型的解码器内,输出得到潜在中间特征,根据潜在中间特征生成情感音频数据。
7、结合第一方面,在第一方面的某些实现方式中,该方法还包括:所述预先建立的情感强度感知神经网络模型的后验网络包括说话人个性保持器和情绪评估单元,所述说话人个性保持器用于从所述梅尔谱图中提取说话人基频信息,所述情绪评估单元用于根据所述梅尔谱图提取其蕴含的效价、唤醒度、支配度数值。
8、结合第一方面,在第一方面的某些实现方式中,该方法还包括:所述说话人个性保持器包括依次连接的多个一维卷积模块和一个全连接模块,其中每个卷积模块均包括依次的卷积、归一化、非线性激活函数三个操作,每个全连接模块包括1个全连接操作。
9、结合第一方面,在第一方面的某些实现方式中,该方法还包括:所述强度映射器在训练过程中,根据所述效价、唤醒度、支配度生成情感强度伪标签;在推理过程中,通过指定目标情感类别和强度值,生成相应的效价、唤醒度、支配度。
10、结合第一方面,在第一方面的某些实现方式中,该方法还包括:所述强度映射器的计算过程:
11、获取由所述情绪评估单元提取到的所述效价、唤醒度、支配度数值:
12、eki=(v,a,d)
13、其中,eki表示第k个情感类别的第i个坐标/语料数据,v表示效价数值、a表示唤醒度数值、d表示支配度数值;
14、使用基于密度的局部离群因子算法lof,计算并剔除各情感类别中所述效价、唤醒度、支配度数值中的离群点:
15、e′ki=(v′,a′,d′)=eki-m where m=lof(en)
16、其中,m表示中性语料簇中心点的效价、唤醒度、支配度数值,en表示中性语料,v′表示效价数值、a′表示唤醒度数值、d′表示支配度数值,e′ki表示修正后第k个情感类别的第i个坐标/语料数据;
17、按照以下公式计算得到未归一化处理的情感强度数值r:
18、
19、按照最小值-最大值缩放min-max scaling的原则对每一情感类别下的情感强度数值进行归一化处理,将数值映射到[0,1]区间,得到最终情感强度值rnorm:
20、
21、其中,rmin表示同一情感类别下情感强度数值中的最小值、rmax表示同一情感类别下情感强度数值中的最大值。
22、结合第一方面,在第一方面的某些实现方式中,该方法还包括:所述预先建立的情感强度感知神经网络模型的先验网络包括:
23、文本编码器,用于从所述音频序列中提取语言学特征,包含依次连接的多个transformer模块和一个线性映射模块;
24、情绪渲染单元,用于根据所述效价、唤醒度、支配度将所述语言学特征处理为所述内容与节奏特征,包括依次连接的多个二维卷积模块和一个线性映射模块。
25、结合第一方面,在第一方面的某些实现方式中,该方法还包括:所述内容与节奏特征包括高斯分布的发音均值和发音方差,所述语调特征包括高斯分布的韵律均值和韵律方差,所述潜在中间特征包括高斯分布的中间特征均值和中间特征方差。
26、结合第一方面,在第一方面的某些实现方式中,该方法还包括:所述解码器包括依次相连接的多个转置卷积操作和多感受野融合模块,其中多感受野融合模块包括依次连接的一维卷积、非线性激活函数及残差结构。
27、第二方面,为了达到上述目的,本发明公开了一种基于可控情感强度的语音编辑装置,包括:
28、数据转换模块,用于获取原始样本数据,其中,所述原始样本数据包括音频数据、文本数据和情感类别标签;将文本数据转换为音频序列,将音频数据转换为梅尔谱图;
29、后验提取模块,用于将梅尔谱图输入至预先建立的情感强度感知神经网络模型的后验网络内,提取得到语调特征,其中,所述语调特征包括说话人基频信息以及效价、唤醒度和支配度的数值;所述情感强度感知神经网络模型包括后验网络、强度映射器、先验网络和解码器;
30、先验提取模块,用于将音频序列和效价、唤醒度和支配度的数值输入至预先建立的情感强度感知神经网络模型的先验网络内,输出得到内容与节奏特征;
31、特征解码模块,用于将内容与节奏特征以及语调特征输入至预先建立的情感强度感知神经网络模型的解码器内,输出得到潜在中间特征,根据潜在中间特征生成情感音频数据。
32、在本发明的另一方面,为了达到上述目的,公开了一种终端设备,包括存储器、处理器及存储在存储器中并能够在处理器上运行的计算机程序,所述存储器中存储有能够在处理器上运行的计算机程序,所述处理器加载并执行计算机程序时,采用了如上所述的一种基于可控情感强度的语音编辑方法。
33、本发明的有益效果:
34、本发明可以更准确地动态调整语调和节奏,在保持语音流畅度和自然度的基础上使得情感表达更加丰富。此外,借助强度映射器,本发明能够根据具体需求灵活调整生成音频中蕴含情感的强烈程度,从而实现更具多样性的情感表达。
本文地址:https://www.jishuxx.com/zhuanli/20241118/330667.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。