一种基于污水处理厂高频入流数据的雨污管网降雨入流和溢流负荷估算方法、存储介质及设备与流程
- 国知局
- 2024-11-21 11:31:32
本技术涉及一种基于污水处理厂高频入流数据的雨污管网降雨入流和溢流负荷估算方法、存储介质及设备,属于城市水环境管理的。
背景技术:
1、随着城镇化进程不断加快,作为城市关键基础设施的地下雨污管网在保障水安全、改善水环境等方面的作用也越来越凸显。通过雨水管网的快速排放,能够将地表径流快速输移至下游,降低上游内涝风险。污水管网负责将生活污水输移至污水处理厂,通过达标净化后,形成可安全排放和循环利用的水资源。在大多数老城区,从运营成本的考虑,雨水和污水管网通常采用合流制,在较大降雨事件时,会出现雨水混入污水管网的情况,造成合流制溢流(cso)。雨水混入污水后,将会占用污水管网的输移空间和能力,稀释生活污水,进而显著降低污水处理厂的进厂水质浓度,导致污水处理环节的微生物生存环境无法得到满足,从而大大降低污水处理厂的处理效率,增加运营成本。同时污水管网的合流制溢流往往直排到下游水体,造成下游的水质污染。即使在雨污分流改造较为完善的地区,由于地下管网的复杂连接关系,以及坡度地势等原因,也一样可能造成降雨期间的雨水混入污水管网,造成合流制溢流污染。与此同时,全球范围内的气候变化趋势,也导致降雨频次和降雨强度的显著增加,使降雨带来的地表径流流量远远超过管网设计值,进一步增加了雨水混入污水管网的风险,给雨污管网的可靠运行和城市水资源管理带来极大的压力。
2、为降低乃至消除合流制溢流风险,首先就是需要能够及时识别溢流的发生,并对溢流规模进行科学估算,从而为后续的现场排查和处置及时提供数据支持。但是由于雨污管网都埋在地下,且水量和水质监测设备价格昂贵、安装困难,无法开展大规模的实时监测,因此仅仅依靠监测网络对溢流进行识别和估算并不现实。此外溢流发生的突发性和随时间变化的特点,也为开展有效的响应和制定科学的管理策略带来了更为复杂的挑战。
3、为此,有必要研发一种不依赖于庞大水量水质监测网络的溢流识别和估算方法,帮助管理部门能够快速准确识别雨水混入污水管网的情况,并对因为降雨入流混入产生的溢流规模进行估算,从而为管理部门的应对决策提供可靠的数据支持。
技术实现思路
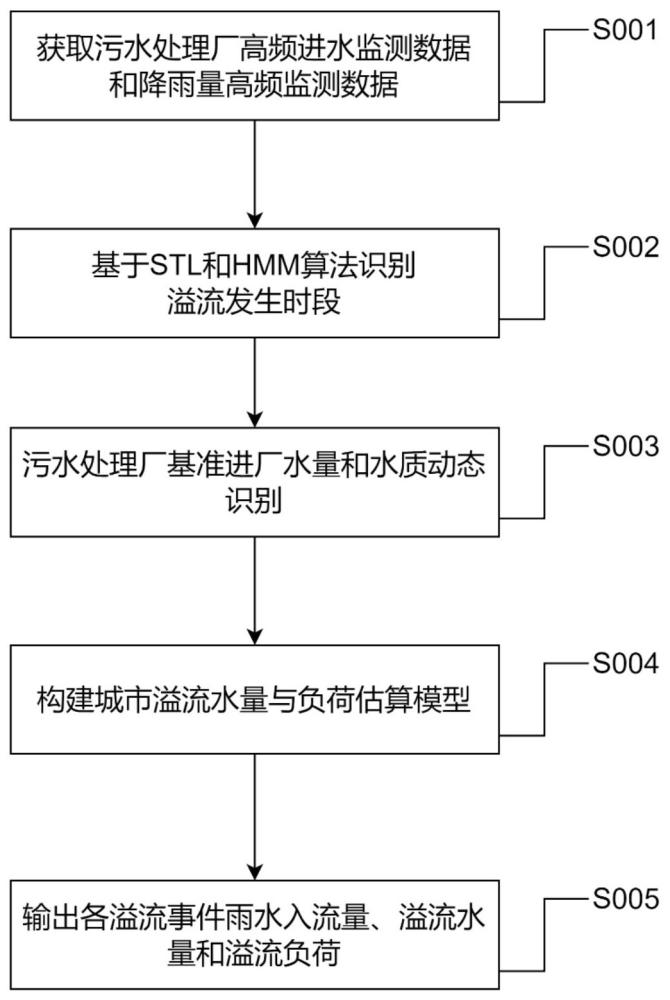
1、本发明的目的是提供一种基于污水处理厂高频入流数据的降雨入流和溢流负荷估算方法、存储介质及设备,本发明将能够为合流制溢流有关的管理决策提供更为精细、全面的数据依据,帮助管理部门精准识别降雨入流并估算因入流产生的溢流规模,从而提高城市水环境管理的科学性和智能化水平。所述技术方案如下:
2、步骤一:获取污水处理厂高频进水监测数据和降雨量高频监测数据;
3、步骤二:基于时间序列分解stl算法和隐马尔科夫模型hmm算法识别溢流发生时段;
4、步骤三:动态识别污水处理厂在非溢流时段的基准进厂水量和水质;
5、步骤四:构建城市溢流水量与负荷估算模型;
6、步骤五:计算得到各溢流事件的雨水入流量、溢流水量和溢流负荷;
7、通过上述技术方案,可以快速识别研究区域内污水管网内的降雨入流混入情况,并对各污水处理厂收水范围内对应的雨水混入量、溢流水量和不同指标的溢流负荷进行估算,从而为后续开展现场排查和采取应对措施提供数据支持。
8、优选地,所述获取污水处理厂高频进水监测数据和降雨量高频监测数据,具体包括收集单个污水处理厂进厂水量、氨氮浓度、总氮浓度、总磷浓度和codcr浓度小时尺度的监测数据,再基于管网拓扑关系中不同关系上下游关系以及出口节点,识别污水处理厂收水范围,从而获取收水范围内至少一个降雨监测站点降雨量小时尺度的监测数据。
9、优选地,基于时间序列分解stl算法和隐马尔科夫模型hmm算法识别溢流发生时段,具体包括对污水处理厂高频进厂监测数据进行数据清洗,基于时间序列分解stl算法识别进厂氨氮浓度、总氮浓度、总磷浓度和codcr浓度和进厂水量趋势,基于隐马尔科夫模型hmm算法识别氨氮浓度低值时段和进厂水量高值时段,并基于降雨监测数据识别场次降雨,从而对氨氮浓度低值时段、进厂水量高值时段和降雨时段取交集,得到溢流发生时段。其中:
10、1)污水处理厂高频进厂监测数据清洗:为了确保数据的准确性和可靠性,对原始监测数据进行清洗,数据清洗过程主要包括极端高值剔除和零负值剔除两个步骤。首先,极端高值剔除是为了排除可能由于设备故障或异常情况导致的极端异常值。在进行该步骤时,会设置一个阈值,超过该阈值的数据点将被视为异常值并进行剔除。其次,零负值剔除是为了排除进厂监测数据中的零值或负值。在实际运营中,污水处理厂的进厂监测数据有时会出现零值或负值,这可能是由于传感器故障、设备停运或其他原因导致的数据异常。为了保证数据的准确性,零负值需要被剔除,以避免对后续分析和计算的影响。
11、2)基于时间序列分解stl算法识别进厂氨氮浓度、进厂水量趋势:时间序列分解stl算法是一种强大的时间序列分解方法,通过对时间序列进行局部回归平滑,可将其分解为趋势、季节性和残差三个部分,能够帮助在不同时间尺度上理解和分析时间序列,在去噪和时序数据分析领域有着广泛的应用。通过stl算法,可以在进厂氨氮浓度和进厂水量的时间序列数据中提取出趋势成分,趋势部分可以揭示出数据中的长期变化趋势,例如氨氮浓度或水量的逐渐上升或下降趋势。这种分解方法可以帮助识别潜在的变化模式,及时识别可能的降雨入流混入污水管网的情况。计算公式为:
12、y(t)=t(t)+s(t)+r(t)
13、其中,y(t)表示原始的进厂氨氮浓度或进厂水量的监测数据时间序列;t(t)表示趋势部分,反映数据的长期变化趋势;s(t)表示季节性部分,展示数据周期性的变化;r(t)表示残差部分,表示未被趋势和季节性解释的随机噪声。
14、季节成分的估计:
15、s(t)=d(t)+i(t)
16、其中,d(t)表示季节性部分的低频成分,代表季节性的长期变化;i(t)表示季节性部分的高频成分,代表季节性的短期波动。
17、季节成分的平滑估计:
18、d(t)=smooth(x(t),span)
19、其中,smooth表示平滑函数,x(t)表示原始时间序列的季节性部分,span表示平滑窗口的大小。
20、趋势成分的估计:
21、t(t)=l(t)+h(t)
22、其中,l(t)表示趋势的低频成分,代表趋势的平滑变化;h(t)表示趋势的高频成分,代表趋势的快速变化。
23、趋势成分的平滑估计:
24、l(t)=smooth(y(t),span)
25、其中,y(t)表示原始进厂氨氮浓度或进厂水量的时间序列监测数据,smooth表示平滑函数,span表示平滑窗口的大小。
26、3)基于隐马尔科夫模型hmm算法识别氨氮浓度低值时段和进厂水量高值时段:hmm算法通过概率矩阵来建立隐藏状态和观测序列之间的关系,在识别氨氮浓度低值时段和进厂水量高值时段的应用中,隐藏状态可以表示水体的特定状态,如低氨氮浓度或高进厂水量,而观测序列则对应着实际观测到的氨氮浓度和进厂水量数据。通过训练hmm模型,可以利用已知的氨氮浓度和进厂水量数据来估计状态转移概率矩阵a、观测概率矩阵b和初始状态概率向量π,来描述系统的动态演变过程;再通过前向概率和后向概率的计算,可以获得在给定观测序列下,系统处于特定状态的概率。基于这些概率,可以进行状态的预测,从而识别出氨氮浓度低值时段和进厂水量高值时段。计算公式为:
27、状态转移概率(transition probability):
28、a={a_ij}
29、其中,a表示状态转移概率矩阵,a_ij表示从状态i转移到状态j的概率。
30、观测概率(emission probability):
31、b={b_j(k)}
32、其中,b表示观测概率矩阵,b_j(k)表示在状态j下观测到观测值k的概率。初始状态概率(initial state probability):
33、π={π_i}
34、其中,π表示初始状态概率向量,π_i表示初始时刻处于状态i的概率。
35、前向概率:
36、α(t,j)=p(o1,o2,...,ot,q(t)=j|λ)
37、其中,α(t,j)表示系统在时刻t处于状态j并观测到o1,o2,...,ot的概率,λ表示hmm模型的参数。
38、后向概率:
39、β(t,j)=p(o(t+1),o(t+2),...,ot|q(t)=j,λ)
40、其中,β(t,j)表示系统在时刻t处于状态j,并从t+1时刻到最后时刻t的观测值的概率,λ表示hmm模型的参数。
41、4)识别场次降雨:定义场次降雨识别准则为总降雨量大于0.2mm,前期无降雨时间超6小时,由此通过降雨监测数据,可以获取单次降雨事件的开始时间和结束时间,从而识别特定起止时间内的降雨时段和非降雨时段。
42、5)基于氨氮浓度低值时段、进厂水量高值时段和降雨时段识别溢流发生时段:首先,通过降雨监测数据,识别每次降雨事件的开始时间和结束时间;其次,通过hmm算法识别进厂氨氮浓度低值时段和进厂水量高值时段;最后,将降雨事件的时间段、氨氮浓度低值时段和进厂水量高值时段取交集,即可确定合流制溢流的发生时段。
43、优选地,动态识别污水处理厂在非溢流时段的基准进厂水量和水质,具体为首先基于步骤二的合流制溢流事件发生时段的识别结果,确定两场溢流事件之间的时间段,即溢流事件a结束到溢流事件b开始之间的时间段,这些是没有发生雨水混入和污水管网溢流的时间段;然后,针对每个非溢流时间段内的每个时间点,提取对应的进厂水量和氨氮浓度监测值;最后对每个非溢流时间段内的监测数据做统计分析,计算进厂水量和氨氮浓度的均值,作为在没有雨水混入和污水管网溢流时,该时间段的污水厂进厂水量和氨氮浓度,也即为该非溢流时间段之后下一个溢流事件的基准进厂水量和氨氮浓度。。
44、优选地,构建城市溢流水量与负荷估算模型,具体包括基于管网拓扑关系,识别污水处理厂的收水范围,获取污水处理厂收水范围内污水管网的特征管长和特征管径数据,基于水量平衡和质量平衡原理动态核算每个模拟时间步长的雨水混入量和污水管网溢流水量,动态核算每个模拟时间步长内不同水质指标的溢流负荷。其中:
45、1)基于管网拓扑关系,识别污水处理厂收水范围:首先通过研究区域的地理信息系统(gis)数据确定污水处理厂位置,从而确定污水处理厂进水节点,作为向上游追踪的起点;根据污水管线节点的高程和连接关系,确定污水处理厂进水节点的上游;沿污水管线节点按照节点高程和连接关系依次向上游分析,直至遍历所有上游节点,生活污水排入这些节点的所有上游区域即构成污水处理厂的收水范围。
46、2)获取污水处理厂收水范围内污水管网的特征管长和特征管径数据:首先,收集与污水处理厂收水范围内的污水管网数据,这包括污水管道的位置、长度、直径等信息;以收水范围为边界,确定每个污水处理厂的上游污水管线,并提取其数据;根据提取的管道数据,计算每条污水管道的特征管长,特征管长是指管道长度与水流路径的有效长度,即考虑流向、弯头、分支等因素后的管道有效长度;确定每条污水管道的特征管径数据,特征管径是指管道内有效的流通区域,通常采用管道的内径或等效直径来表示。可以通过管道设计文件和现场测量获取特征管径信息。
47、3)动态核算溢流时间段内每个时间步长污水管网的雨水混入量和溢流水量:基于水量平衡和质量平衡原理,分别计算每个时间步长的雨水混入量和溢流水量。计算公式为:
48、v=π*r2*l
49、
50、q3=q1+q2-q4
51、其中,v为管网容积,l为污水管网的特征管长,r为污水管网的特征管径,q1为非溢流时段的基准进厂水量,c1为非溢流时段的基准进厂氨氮浓度,q2为雨水混入量,c2为混入雨水后的进厂氨氮浓度,q3为溢流水量,δc3为污水处理厂进厂氨氮浓度变化量,q4为进厂水量。
52、4)动态核算溢流时间段内每个时间步长污水管网不同水质指标的溢流负荷:动态核算氨氮、总氮、总磷、codcr的溢流负荷。计算公式为:
53、
54、其中,为编号为n的水质指标在i时刻的溢流负荷,为编号为n的水质指标在i时刻的进厂浓度。
55、优选地,计算得到各溢流事件雨水入流量、溢流水量和溢流负荷,具体为:根据城市溢流水量与负荷估算模型计算得到的各溢流时段内的雨水混入量、溢流水量、氨氮溢流负荷、总氮溢流负荷、总磷溢流负荷和codcr溢流负荷,对目标时段内的全部溢流事件进行求和,得到目标时段内总的雨水混入量、溢流水量、氨氮溢流负荷、总氮溢流负荷、总磷溢流负荷和codcr溢流负荷。
56、综上所述,本技术包括以下有益的技术效果:
57、1、本技术提出的基于污水处理厂高频入流数据的雨污管网降雨入流和溢流负荷估算技术,能够有效降低常规降雨入流和溢流分析方法对监测数据的高度依赖,无需开展对污水管网水文水质的全面、高频监测,仅依靠常规的降雨监测和污水处理厂进水监测数据就可以较为准确地估算在发生合流制溢流时的降雨入流量和不同水质指标的溢流负荷,能够显著节约监测成本和工作量。
58、2、本技术提出的基于污水处理厂高频入流数据的雨污管网降雨入流和溢流负荷估算技术,能够在线部署并滚动运行,读取降雨监测数据和污水处理厂进水监测数据,通过计算实时识别污水管网系统中是否发生了降雨入流混入,以及在发生混入时,对应的溢流负荷量,从而为管理部门快速部署应对措施,开展现场排查争取宝贵的响应时间,保障污水处理厂的稳定运行,同时降低下游的水环境污染风险。
59、3、本技术提出的基于污水处理厂高频入流数据的雨污管网降雨入流和溢流负荷估算技术通过智能化数据分析和建模方法,建立起较为准确和可靠的合流制溢流识别及分析框架,本技术不受合流制溢流事件发生的随机性和时空变异性的影响,具有通用性,可以快速部署应用到任意城市雨污管网的运行状况分析,显著提升城市水环境管理的效能,具有广阔的应用前景。
本文地址:https://www.jishuxx.com/zhuanli/20241120/331627.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表