一种基于沙普利值聚合的联邦学习方法与流程
- 国知局
- 2024-11-21 12:02:58
本发明涉及机器学习,尤其涉及一种基于沙普利值聚合的联邦学习方法。
背景技术:
1、联邦学习在带来巨大机遇的同时,也会面临技术带来的新问题,例如联邦学习使用来自不同客户端的数据集,并且不同客户端之间的数据有很大机率存在数据质量的方面的不平衡性,联邦学习的聚合算法并没有考虑到客户端的贡献维度,将导致用户之间在联邦学习的过程中的地位存在不公平的现象,严重者甚至直接拒绝参加联邦学习。面对人工智能引发的信任焦虑,发展可信人工智能成为全球共识。从学术研究角度,可信人工智能研究包含了安全性、可解释、公平性、隐私保护等多方面内容。其中公平性的概念最早在上世纪60年代被提出和探讨。它可以确保每个人都有平等的机会获得一些利益,这种行为被称为公平的行为,或者具有公平性。不能够确保每个参与方公平地获得一些利益,称为不公平的行为,歧视和偏见与不公平密切相关,被视为不公平行为的特质。如果机器学习在进行预测或决策时,能保证每个参与方平等地获得最终效益,那么就可以认为机器学习具有公平性的特征,并被称为公平机器学习。
2、目前对联邦学习的研究大部分会把重心放在如何提升整个联邦学习框架的性能、隐私保护、通信效率等等,却忽视了各用户在加入联邦学习时的激励机制。因此,要使得联邦学习过程中各用户可以持续经营并且各用户之间的公平地位有更好的保证和评判标准。为了鼓励用户积极参与,确保根据他们在学习过程中的贡献来公平地评估来自不同用户的数据是至关重要的。
3、当前联邦学习环境中的数据质量参差不齐,低质量数据持有者或恶意攻击者对模型性能的潜在损害,直接计算参与者夏普利值在联邦学习场景中所需的高昂计算成本。
4、因此,提出一种基于沙普利值聚合的联邦学习方法,来解决现有技术存在的困难,是本领域技术人员亟须解决的问题。
技术实现思路
1、有鉴于此,本发明提供了一种基于沙普利值聚合的联邦学习方法,能够大幅降低了计算资源的消耗,可以通过精细评估每位参与者的实际贡献,确保模型训练过程仅依赖于对模型改进有着积极贡献的高质量数据,从而显著提高了模型的准确性和鲁棒性。
2、为了实现上述目的,本发明采用如下技术方案:
3、一种基于沙普利值聚合的联邦学习方法,包括以下步骤:
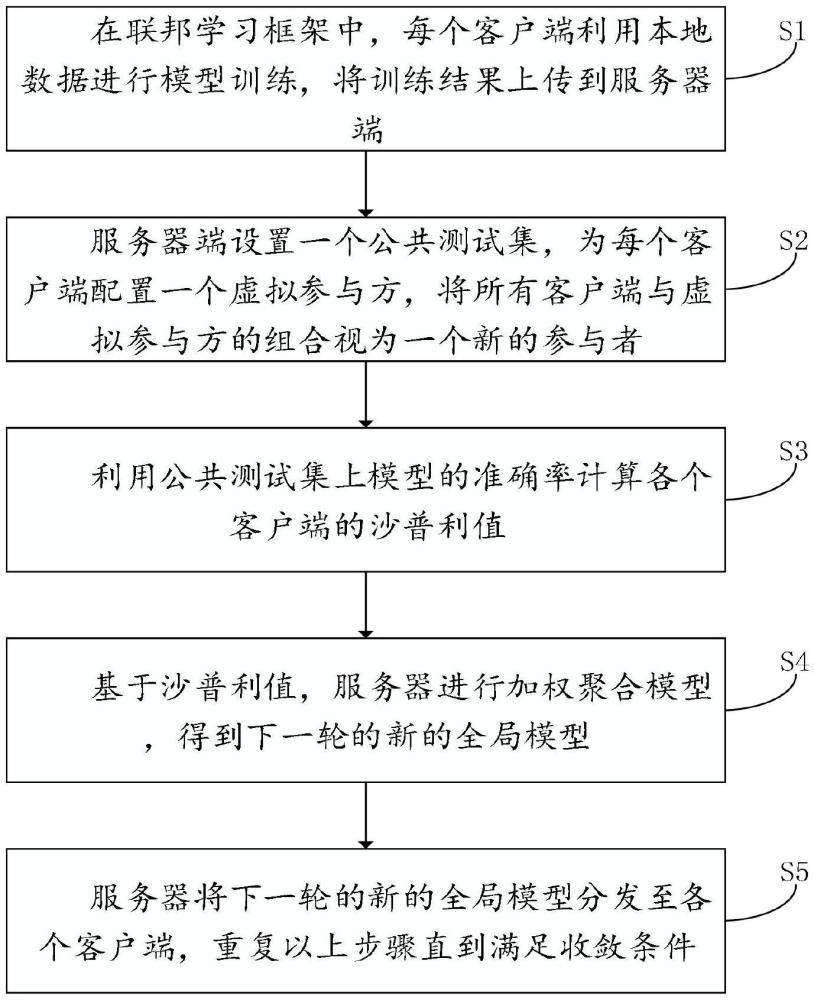
4、s1、在联邦学习框架中,每个客户端利用本地数据进行模型训练,将训练结果上传到服务器端;
5、s2、服务器端设置一个公共测试集,为每个客户端配置一个虚拟参与方,将所有客户端与虚拟参与方的组合视为一个新的参与者;
6、s3、利用公共测试集上模型的准确率计算各个客户端的沙普利值;
7、s4、基于沙普利值,服务器进行加权聚合模型,得到下一轮的新的全局模型;
8、s5、服务器将下一轮的新的全局模型分发至各个客户端,重复步骤s1-s4直到满足收敛条件。
9、上述的方法,可选的,在分布式计算环境下,每个客户端在本地设备上利用本地数据进行模型训练,然后将训练结果上传到服务器端进行聚合,服务器公共测试集为ct是第t个联邦学习回合的参与者子集,在t轮中,服务器首先生成所有可能的参与者组合集合
10、上述的方法,可选的,s3中,采用一种单回合的联邦学习夏普利值计算方法计算各个客户端的沙普利值,对于参与者组合s,其在第t个回合上的模型参数为:
11、
12、其中,为参与者i∈s在第t个回合的上传的模型参数,ns为参与者组合s内样本数量;
13、定义参与者组合在当前回合的模型效用为:
14、
15、第t轮中客户端i∈ct的联邦夏普利值为:
16、
17、通过综合各轮次中每个客户端的单回合联邦夏普利值,估算出各客户端至今为全局模型所作的整体边际贡献。
18、上述的方法,可选的,采用归一化处理,将所有客户端的贡献值调整到同一标准化尺度上,使其在整个联邦学习过程中被公平且一致地比较和分析:
19、
20、其中,指的是第t个回合中,客户端子集ct上计算的夏普利值集合,即
21、参与者在训练结束后,对于全局模型的整体边际贡献为:
22、
23、上述的方法,可选的,使用蒙特卡洛采样计算夏普利值,设目标为x,迭代取样次数设为m,对于每次取样过程如下:
24、从样本特征矩阵x中随机选取sample z;
25、生成随机排列p1,p2,...,pn,并构造:
26、
27、构造:
28、
29、计算贡献值:
30、
31、取平均值作为夏普利值:
32、
33、上述的方法,可选的,s4中,基于沙普利值,服务器进行加权聚合模型,首先对参与者的夏普利值进行归一化处理,对于第t轮中的参与者i,其归一化后的权重表达式为:
34、
35、其中是参与者i在第t轮的夏普利值。
36、在得到每个客户端参与者的权重后,服务器进行加权聚合模型,得到下一轮的新的全局模型:
37、
38、其中,为参与者i在第t轮上传的模型参数。
39、上述的方法,可选的,s5中,联邦学习用户为k个,每个用户都有数据集di,i∈i=1,2,...,k,迭代轮次为r∈1,2,...,r-1,服务器s向所有客户端发送全局模型被选中的客户端节点从中央服务器下载最新的全局模型参数,作为本地训练的起点。
40、上述的方法,可选的,每个用户,根据自己的数据di训练w(r),每个选定的客户端节点在全局模型的基础上,利用本地数据进行模型的本地更新的子模型返回给服务器,各客户端节点将更新后的本地模型参数加密后发送给中央服务器,服务器整合子模型中央服务器将本地模型参数按照指定的规则(如加权平均或其它聚合方法)聚合成得到一个新的全局模型w(r+1)用于下一次迭代,中央服务器将这个新的全局模型分发给选定的客户端节点,进行下一轮的训练,直到模型达到收敛状态或者满足了其他的停止准则。
41、经由上述的技术方案可知,与现有技术相比,本发明提供了一种基于沙普利值聚合的联邦学习方法,具有以下有益效果:1)在联邦学习框架中对各客户端的模型计算其贡献值,并由此调节训练公共模型时的权重进行聚合,使得最终全局模型准确率优于fedavg算法,并将联邦学习过程中不同客户端的贡献程度分析出来;2)面对联邦学习环境中的数据质量参差不齐的问题,使用夏普利值精确评估各参与者对模型所作的贡献,确保了对高质量数据贡献者的准确识别和适当奖励;3)能够在整个训练过程中实时估算各参与者的贡献度,大幅降低了计算资源的消耗;4)通过精细评估每位参与者的实际贡献,确保了模型训练过程仅依赖于那些对模型改进有着积极贡献的高质量数据,从而显著提高了模型的准确性和鲁棒性。
技术特征:1.一种基于沙普利值聚合的联邦学习方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于沙普利值聚合的联邦学习方法,其特征在于,在分布式计算环境下,每个客户端在本地设备上利用本地数据进行模型训练,然后将训练结果上传到服务器端进行聚合,服务器公共测试集为ct是第t个联邦学习回合的参与者子集,在t轮中,服务器首先生成所有可能的参与者组合集合
3.根据权利要求1所述的一种基于沙普利值聚合的联邦学习方法,其特征在于,s3中,采用一种单回合的联邦学习夏普利值计算方法计算各个客户端的沙普利值,对于参与者组合s,其在第t个回合上的模型参数为:
4.根据权利要求3所述的一种基于沙普利值聚合的联邦学习方法,其特征在于,采用归一化处理,将所有客户端的贡献值调整到同一标准化尺度上,使其在整个联邦学习过程中被公平且一致地比较和分析:
5.根据权利要求3所述的一种基于沙普利值聚合的联邦学习方法,其特征在于,
6.根据权利要求1所述的一种基于沙普利值聚合的联邦学习方法,其特征在于,s4中,基于沙普利值,服务器进行加权聚合模型,首先对参与者的夏普利值进行归一化处理,对于第t轮中的参与者i,其归一化后的权重表达式为:
7.根据权利要求1所述的一种基于沙普利值聚合的联邦学习方法,其特征在于,s5中,联邦学习用户为k个,每个用户都有数据集di,i∈i=1,2,…,k,迭代轮次为r∈1,2,…,r-1,服务器s向所有客户端发送全局模型被选中的客户端节点从中央服务器下载最新的全局模型参数,作为本地训练的起点。
8.根据权利要求7所述的一种基于沙普利值聚合的联邦学习方法,其特征在于,每个用户,根据自己的数据di训练w(r),每个选定的客户端节点在全局模型的基础上,利用本地数据进行模型的本地更新的子模型返回给服务器,各客户端节点将更新后的本地模型参数加密后发送给中央服务器,服务器整合子模型中央服务器将本地模型参数按照指定的规则聚合成得到一个新的全局模型w(r+1)用于下一次迭代,中央服务器将这个新的全局模型分发给选定的客户端节点,进行下一轮的训练,直到模型达到收敛状态或者满足了其他的停止准则。
技术总结本发明公开了一种基于沙普利值聚合的联邦学习方法,涉及分布式计算技术领域。包括:在联邦学习框架中,每个客户端利用本地数据进行模型训练,将训练结果上传到服务器端;服务器端设置一个公共测试集,为每个客户端配置一个虚拟参与方,将所有客户端与虚拟参与方的组合视为一个新的参与者;利用公共测试集上模型的准确率计算各个客户端的沙普利值;基于沙普利值,服务器进行加权聚合模型,得到下一轮的新的全局模型;服务器将下一轮的新的全局模型分发至各个客户端,重复步骤S1‑S4直到满足收敛条件。本发明使得最终全局模型准确率优于Fedavg算法,并将联邦学习过程中不同客户端的贡献程度分析出来。技术研发人员:张大山受保护的技术使用者:张大山技术研发日:技术公布日:2024/11/18本文地址:https://www.jishuxx.com/zhuanli/20241120/334014.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表