资源受限场景下基于梯度的子模型抽取的联邦学习方法
- 国知局
- 2024-11-21 12:03:11
本发明涉及计算机,具体是涉及资源受限场景下基于梯度的子模型抽取的联邦学习方法。
背景技术:
1、随着大数据时代步伐的加快,基于巨大数据量训练深度模型取得了显著的效果,使得人们的工作效率更加高效。在传统的深度学习中,数据被收集到单一的计算机或者可以互相访问的集群用于训练模型,此法简便且高效。然而,鉴于某些特定的数据集合高度敏感(例如医疗机构的病患信息、金融机构的财务记录),跨主体数据共享成为一大难题。在此背景下,单独基于有限数据集的模型训练极易遭遇性能天花板,并陷入过拟合困境,模型将无法应用于现实复杂问题。为在确保数据隐私的同时挖掘数据价值,谷歌于2016年首次提出联邦学习概念。这一创新技术,依托于多方协作下的分布式优化算法,旨在跨越数据孤岛,使各参与方无须直接交换数据即可协同提升模型效能。
2、尽管联邦学习为缓解数据隐私与分布式处理需求提供了可行路径,它亦面临着若干待解难题。一方面,计算成本偏高,特别是在边缘设备执行模型训练任务时,当前技术框架对计算资源的大量需求,加重了边缘端的运算负担,这对于计算资源稀缺的小型组织而言,无疑构成了训练大规模模型的重大障碍。另一方面采用蒸馏学习方法在客户端训练更小的不同于全局模型架构的模型不利于模型的聚合,增加了额外的步骤。
技术实现思路
1、本发明所要解决的技术问题是在数据不共享,客户端资源受限的前提下,提供一种与服务器端模型架构相近的子模型用于客户端训练,基于梯度的选择使得子模型更贴合客户端的私有数据分布,从而增强全局模型的泛化能力。
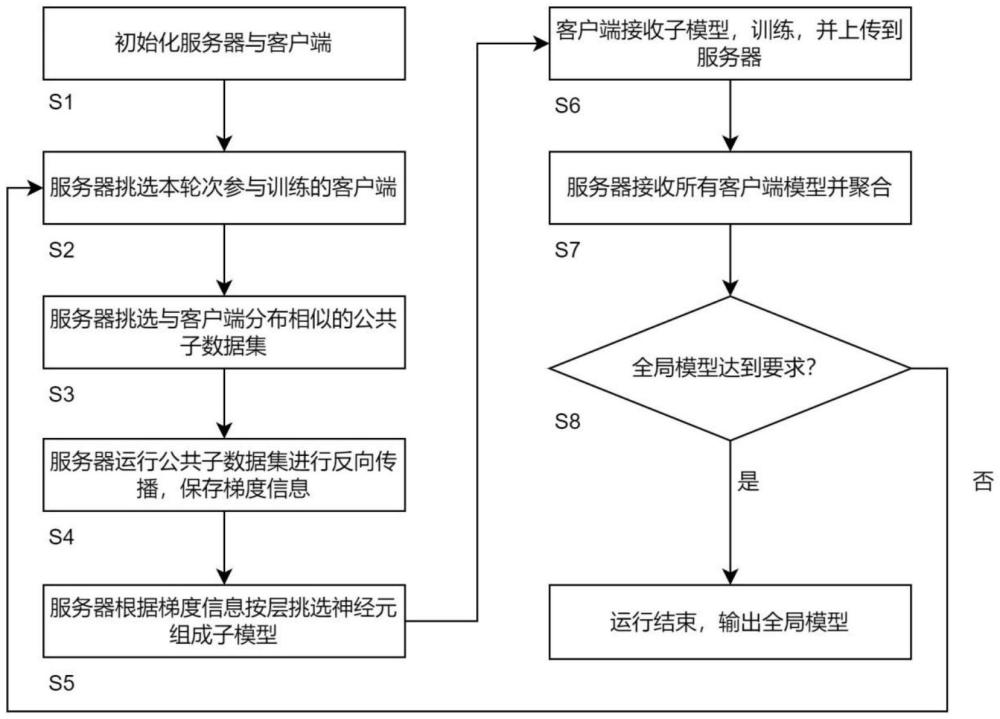
2、为了实现上述目的,本发明提供资源受限场景下基于梯度的子模型抽取的联邦学习方法,包括以下步骤:
3、s1、初始化中心服务器和客户端,初始化服务器上的全局模型的参数;
4、s2、服务器挑选本轮次需要参与训练的客户端;
5、s3、根据不同客户端从上个轮次保存的历史模型在公共数据集上挑选出适用不同客户端的公共子数据集,这些公共子数据集与相应客户端私有数据有相似的数据分布;
6、s4、根据挑选出的公共子数据集在服务器上对全局模型进行反向传播,并且保存整个模型每一个神经元的梯度;
7、s5、根据梯度信息从全局模型中按层挑选神经元组成用于客户端训练的子模型,并且将子模型发送给相应的客户端;
8、s6、客户端从服务器接受子模型,子模型基于本地私有数据进行训练,并将训练完成的子模型上传到服务器;
9、s7、服务器接受本轮次所有客户端的上传的模型,并保存这些模型,然后匹配对应神经元的位置进行聚合,最终得到本轮次的全局模型;
10、s8、步骤s2~s5为一个轮次训练,每次均重复这个轮次,直到模型能力符合要求为止。
11、优选的,所述根据不同客户端从上个轮次保存的历史模型在公共数据集上挑选出适用不同客户端的公共子数据集,具体为:
12、若这是第一个轮次训练,服务器上没有历史模型,这时随机抽选一定数量的子数据集;若不是第一个轮次,就使用客户端上次上传的模型在公共数据集上预测,用预测的数据组成子数据集;
13、若公共数据集本身具有标签,那么使用历史模型在整个公共数据集上进行预测,用预测正确的数据组成子数据集;若公共数据集本身只有数据,那么对整个数据集进行预测,使用预测标签作为子数据集的标签。
14、优选的,所述公共数据集使用三种方法构造,分别为:直接从客户端上传本地数据、客户端根据本地数据利用生成模型来构造相似数据、选择包含相似数据类型的替代数据集或将本地数据标签作为替代品。
15、优选的,所述根据梯度信息从全局模型中按层挑选神经元组成用于客户端训练的子模型,并且将子模型发送给相应的客户端,具体为:
16、根据相应客户端的计算能力分配子模型每层神经元的数量,从浅到深,一层一层的挑选;
17、在每层中,计算本层中神经元梯度的绝对值,按照大小排序,从大到小开始选择,直到挑选数量达到客户端可以承受最大训练数量结束。
18、优选的,所述服务器接受本轮次所有客户端的上传的模型,并保存这些模型,然后匹配对应神经元的位置进行聚合,最终得到本轮次的全局模型,具体为:
19、遍历所选中客户端的上传的子模型,并且每个子模型中记录每个神经元在全局模型中的具体位置,获得全局模型中每个位置神经元出现的次数和具体的参数值;
20、根据每个神经元出现的次数和具体参数值,算出每个神经元的平均参数值作为最终的值,整个聚合过程完成。
21、优选的,所述每一个神经元的梯度定义为g:
22、
23、在分类任务中,使用卷积神经网络,hl,i表示l层第i个神经元激活值矩阵,k,v表示特征图的长和宽,神经元梯度的定义是对整个特征图的激活值的梯度取绝对值之和。
24、优选的,所述子模型基于本地私有数据进行训练过程中采用了掩码交叉熵损失、放缩模块和静态批归一化。
25、优选的,所述缩放模块插入在参数层之后激活层之前,在训练阶段以的因子对输入值进行缩放,其中q为全局模型参数的偏移率。
26、与现有技术相比,本发明的有益效果是:
27、1.本发明提出了三种构造公共数据集的方式,从简单的直接由客户提供到选择其他数据来代替到使用生成模型来构造虚拟数据集,解决了联邦学习公共数据集难以收集的难度,三种方式提供了不同程度的解决人们关心的隐私问题。
28、2.本发明提出了从公共子数据集中构建或者选择出与相关的客户端私有数据集分布相似的公共子数据集的方法,这两种方法分别要求公共数据集有标签与无标签,大大提升了解决实际问题的能力。
29、3.本发明提出了一种与以前方法相比以更加新颖更加合理的方式解决资源受限情况下模型抽取问题,通过计算全局模型的梯度来选择子模型,这样保证了子模型的梯度更新最接近与全局模型的梯度更新,从而使得资源受限联邦学习效果达到最接近普通联邦学习的效果。
技术特征:1.资源受限场景下基于梯度的子模型抽取的联邦学习方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的资源受限场景下基于梯度的子模型抽取的联邦学习方法,其特征在于,所述根据不同客户端从上个轮次保存的历史模型在公共数据集上挑选出适用不同客户端的公共子数据集,具体为:
3.根据权利要求2所述的资源受限场景下基于梯度的子模型抽取的联邦学习方法,其特征在于,所述公共数据集使用三种方法构造,分别为:直接从客户端上传本地数据、客户端根据本地数据利用生成模型来构造相似数据、选择包含相似数据类型的替代数据集或将本地数据标签作为替代品。
4.根据权利要求1所述的资源受限场景下基于梯度的子模型抽取的联邦学习方法,其特征在于,所述根据梯度信息从全局模型中按层挑选神经元组成用于客户端训练的子模型,并且将子模型发送给相应的客户端,具体为:
5.根据权利要求1所述的资源受限场景下基于梯度的子模型抽取的联邦学习方法,其特征在于,所述服务器接受本轮次所有客户端的上传的模型,并保存这些模型,然后匹配对应神经元的位置进行聚合,最终得到本轮次的全局模型,具体为:
6.根据权利要求1所述的资源受限场景下基于梯度的子模型抽取的联邦学习方法,其特征在于,所述每一个神经元的梯度定义为g:
7.根据权利要求1所述的资源受限场景下基于梯度的子模型抽取的联邦学习方法,其特征在于,所述子模型基于本地私有数据进行训练过程中采用了掩码交叉熵损失、放缩模块和静态批归一化。
8.根据权利要求7所述的资源受限场景下基于梯度的子模型抽取的联邦学习方法,其特征在于,所述缩放模块插入在参数层之后激活层之前,在训练阶段以的因子对输入值进行缩放,其中q为全局模型参数的偏移率。
技术总结本发明公开了资源受限场景下基于梯度的子模型抽取的联邦学习方法,首先在公共数据集中选出与客户端私有数据集相似的公共子数据集,用来对服务器端的全局模型进行反向传播操作,得到全局模型中每个神经元的梯度;然后根据梯度对全局模型进行抽取形成子模型;在深度模型中,按照每层从浅到深选取神经元,根据相应客户端能训练模型的最大能力,在每层中按照神经元梯度绝对值的大小,从高到低依次选择,直到满足本层最大训练个数为止。本发明提供了一种在客户端资源受限情况下的联邦学习的训练方式,对服务器端的模型按照梯度在神经元级别上剪裁,充分利用各方计算资源与私有数据,从而使得资源受限联邦学习效果达到最接近普通联邦学习的效果。技术研发人员:贾亚博,陈根浪,庞超逸受保护的技术使用者:浙江大学技术研发日:技术公布日:2024/11/18本文地址:https://www.jishuxx.com/zhuanli/20241120/334038.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表