一种基于标志点与张量多维图学习的非全面多视角人脸图像聚类方法
- 国知局
- 2024-12-06 12:10:19
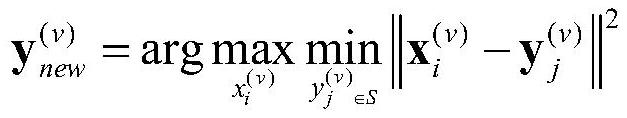
本发明属于多媒体信息处理中的人脸图像数据聚类处理领域,具体涉及一种基于标志点与张量多维图学习的非全面多视角人脸图像聚类方法。
背景技术:
1、在人脸识别和多媒体信息处理领域,人脸图像数据是一种广泛可获取且具有重要应用价值的数据。对人脸图像数据进行多视角聚类分析,可以挖掘出人脸在不同角度、表情和光照条件下的特征,以及不同人脸之间的相似性和差异性等潜在类别信息。在众多多视角数据的学习技术中,多视角聚类是其中最流行的技术之一,它可以利用多个视角的信息,对数据进行无监督的分类,并能适用于多种实际应用人脸,如身份验证、情感分析和人脸识别等。然而,在人脸图像数据的采集过程中,可能会出现人脸信息丢失等情况,导致每个样本在不同视角下的可观测性不一致,从而引发多视角人脸图像数据的非全面问题。然而,现有的多视角聚类方法仅能处理全面多视角数据的聚类问题,因此,需要一种有效的新颖技术方法来解决对非全面多视角人脸图像数据的聚类问题。
技术实现思路
1、为了解决上述问题,本发明提供了一种基于标志点与张量多维图学习的非全面多视角人脸图像聚类方法,其特征在于,所述方法包括步骤:
2、对非全面多视角人脸图像数据集提取每个视角中的存在样本;
3、从存在样本中学习视角限定标志点,以表示包括非全面样本在内的所有样本的分布,采用直接交替采样方法选择标志点,构建视角限定的标志点图;
4、对每个视角的标志点图进行正交非负矩阵分解,得到视角限定的软指示矩阵;
5、将各视角的软指示矩阵堆叠成张量,通过最小化张量schattenp-范数来捕捉视角间的高阶相关性和互补信息;
6、通过统一的二分图框架和张量低秩约束,有效处理视角间的不完全性,再将每个视角的软指示矩阵进行融合得到最终的共识指示矩阵;
7、对所得的共识指示矩阵进行奇异值分解,并选取左奇异向量的前c个分量进行k均值聚类(c是类簇个数),得到最终聚类结果。最后,对最终聚类结果计算其聚类准确率。
8、进一步地,将所述非全面人脸图像数据集中提取的每个视角的存在样本定义为:
9、
10、其中,x表示所有视角的存在样本特征矩阵,x(v)是视角v的存在特征矩阵,nv是视角v的非全面样本数,dv是视角v的特征维度,m是视角数。
11、进一步地,所述交替采样选取标志点方法表达公式为:
12、
13、其中,表示第v个视角新选取的标志点,表示视角v的第i个样本,表示视角v已选择的第j个标志点,s表示当前已选择的标志点集。首先随机选取一个样本作为标志点设为y1,然后对于每一个样本xi,通过计算与当前标志点集s所有标志点最小距离,然后选择与当前标志点集距离最大的样本作为当前视角最新的标志点。
14、进一步地,所述视正交非负矩阵分解的表达公式为:
15、
16、其中,表示第v个视角的标志点图矩阵,其中n是数据点的数量,m是标志点的数量,k是聚类数。表示第v个视角的软指示矩阵。表示第v个视角的标志点表示矩阵。表示单位矩阵表示g(v)的列正交约束。
17、进一步地,所述最小化张量schattenp-范数的表达公式为:
18、
19、其中,是张量的第i个前切片,是是矩阵的schatten p-范数。
20、进一步地,所述统一二分图框架结合张量低秩约束的表达公式为:
21、
22、其中,b(v)=x(v)a(v)表示对非全面数据的标志点的构建,f(v)'是经过统一二分图框架和张量低秩约束得到的特定视角的软指示矩阵,a(v)是第v个视角的标志点选择矩阵,αv是第v个视角的权重参数,β是正则化参数,f是最终得到的共识指示矩阵。
23、进一步地,根据所述最终聚类结果,计算其聚类准确率。
24、本发明提供了一种基于局部和全局锚图集成的非全面多视角人脸图像数据聚类方法,具有以下优势:
25、(1)所述方法采用了多视角聚类框架,充分利用非全面多视角人脸图像数据集的视角一致性和差异性,有效挖掘潜在类簇结构。通过结合各视图的信息,能够更准确地捕捉人脸图像在不同视角下的特征,提高聚类的精度。
26、(2)所述方法采用了直接交替采样(das)技术选择标志点,构建视图特定的标志点图。通过这种方式,不仅降低了计算复杂度和内存消耗,而且有效减轻了非全面多视角人脸图像数据的影响。das方法能够更稳定地选择代表性标志点,避免了传统k-means方法带来的不稳定性。
27、(3)所述方法采用了张量低秩约束,通过最小化张量schattenp-范数来捕捉视图间的高阶相关性和互补信息。张量低秩约束能够有效地处理视图间的不完全性,确保聚类结果的稳定性和准确性。
技术特征:1.一种基于标志点与张量多维图学习的非全面多视角人脸图像聚类方法,其特征在于,所述方法包括步骤:
2.根据权利要求1所述的一种基于标志点与张量多维图学习的非全面多视角人脸图像聚类方法,其特征在于,对非全面多视角人脸图像数据集提取每个视角的存在样本:
3.根据权利要求1所述的一种基于标志点与张量多维图学习的非全面多视角人脸图像聚类方法,其特征在于,使用直接交替采样方法为每个视角选择标志点,构建视角限定的标志点图,所述交替采样选取标志点方法定义如下:
4.根据权利要求1所述的一种基于标志点与张量多维图学习的非全面多视角人脸图像聚类方法,其特征在于,对每个视角的标志点图进行正交非负矩阵分解,得到视角限定的软指示矩阵,其中视正交非负矩阵分解的表达公式如下:
5.根据权利要求1所述的一种基于标志点与张量多维图学习的非全面多视角人脸图像聚类方法,其特征在于,将各视角的软指示矩阵堆叠成张量,通过最小化张量schattenp-范数来捕捉视角间的高阶相关性和互补信息,最小化张量schattenp-范数的定义如下:
6.根据权利要求1所述的一种基于标志点与张量多维图学习的非全面多视角人脸图像聚类方法,其特征在于,通过统一的二分图框架和张量低秩约束,有效处理视角间的不全面性,最后将每个视角的软指示矩阵进行融合得到最终的共识指示矩阵,统一二分图框架结合张量低秩约束和共识矩阵定义如下:
7.根据权利要求1所述的一种基于标志点与张量多维图学习的非全面多视角人脸图像聚类方法,其特征在于,根据所得聚类结果,计算所述非全面多视角人脸图像数据集上的聚类准确率。
技术总结一种基于标志点与张量多维图学习的非全面多视角人脸图像聚类方法,属于多媒体信息处理中的人脸图像聚类处理领域,本发明首先提取每个视角中的存在样本,并从这些存在样本中学习视角特定标志点,以表示包括非全面样本在内的所有样本的分布。再利用直接交替采样方法选择标志点,构建视角特定的标志点图,然后对每个视角的标志点图进行正交非负矩阵分解,得到视角特定的软指示矩阵。将各视角的软指示矩阵堆叠成张量,通过最小化张量Schattenp‑范数来捕捉视角间的高阶相关性和互补信息。通过统一的二分图框架和张量低秩约束,有效处理视角间的不完全性,再将每个视角的软指示矩阵进行融合,得到最终的共识指示矩阵。利用奇异值分解和K均值聚类对其进行聚类分析,得到最终聚类结果。以此促进模型的自适应性和鲁棒性。与其他方法相比,本发明的精确度更高,性能更加稳健。技术研发人员:许浩越,王雁冰,李骜,王莉莉,程媛受保护的技术使用者:哈尔滨理工大学技术研发日:技术公布日:2024/12/2本文地址:https://www.jishuxx.com/zhuanli/20241204/339749.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。