一种基于人工智能的教育评价目标数据处理方法以及系统与流程
- 国知局
- 2025-01-10 13:29:34
本申请涉及数据处理领域,尤其涉及一种基于人工智能的教育评价目标数据处理方法以及系统。
背景技术:
1、在教育领域,随着教育信息化的不断深入,教育评价数据的处理与分析变得日益重要。传统的教育评价方法往往依赖于人工阅读和汇总大量的评价文本,这一过程不仅耗时费力,而且容易受到主观因素的影响,导致评价结果的准确性和一致性难以保证。为了提升评价效率和质量,近年来,越来越多的教育机构和研究机构开始探索利用信息技术和人工智能手段进行自动化教育评价。现有的基于人工智能的教育评价数据处理方法仍存在一些局限性。一方面,由于教育评价文本通常包含大量的信息,且这些信息在文本中的分布具有随机性,直接对整个文本进行识别往往难以准确捕捉到所有关键信息点,特别是那些分散在不同段落中的细节信息。另一方面,现有的方法往往采用统一的识别策略处理整个文本,忽略了不同段落间信息的差异性和重要性,导致信息提取的精度和效率不高。
技术实现思路
1、有鉴于此,本申请提供一种基于人工智能的教育评价目标数据处理方法以及系统。本申请的技术方案是这样实现的:
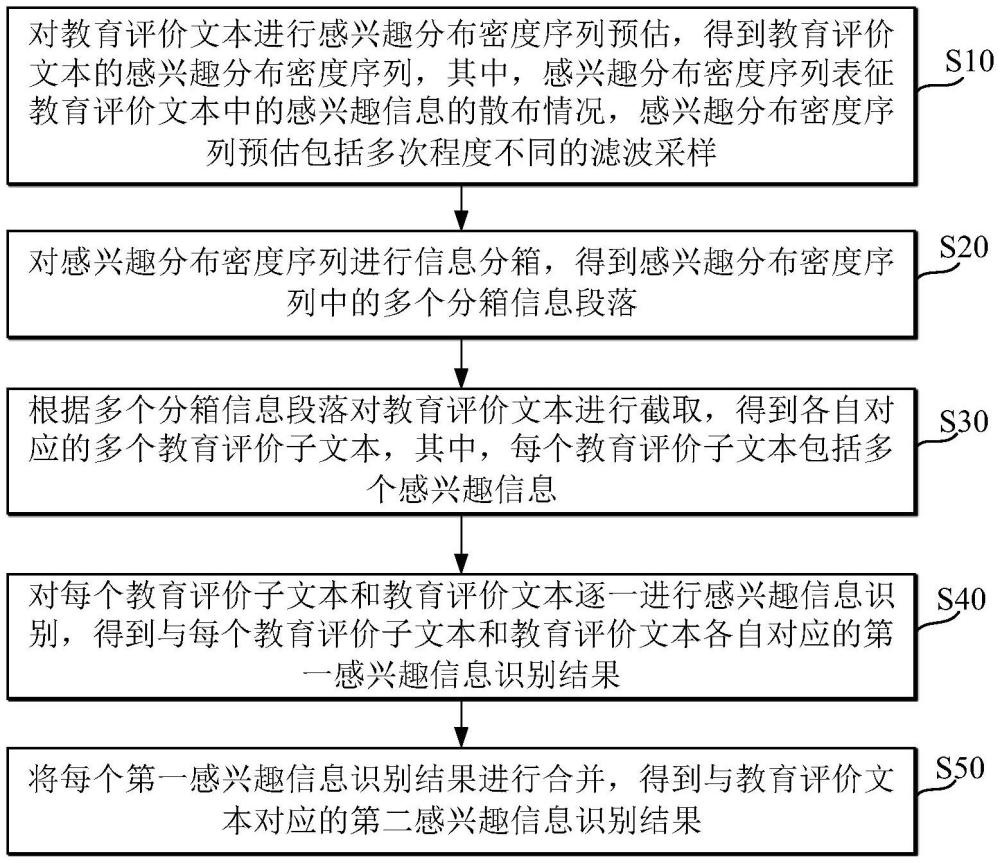
2、一方面,本申请提供一种基于人工智能的教育评价目标数据处理方法,所述方法包括:对教育评价文本进行感兴趣分布密度序列预估,得到所述教育评价文本的感兴趣分布密度序列,其中,所述感兴趣分布密度序列表征所述教育评价文本中的感兴趣信息的散布情况,所述感兴趣分布密度序列预估包括多次程度不同的滤波采样;对所述感兴趣分布密度序列进行信息分箱,得到所述感兴趣分布密度序列中的多个分箱信息段落;根据所述多个分箱信息段落对所述教育评价文本进行截取,得到各自对应的多个教育评价子文本,其中,每个所述教育评价子文本包括多个所述感兴趣信息;
3、对每个所述教育评价子文本和所述教育评价文本逐一进行感兴趣信息识别,得到与每个所述教育评价子文本和所述教育评价文本各自对应的第一感兴趣信息识别结果;将每个所述第一感兴趣信息识别结果进行合并,得到与所述教育评价文本对应的第二感兴趣信息识别结果。
4、另一方面,本申请提供一种计算机系统,包括存储器和处理器,所述存储器存储有可在处理器上运行的计算机程序,所述处理器执行所述程序时实现以上方法中的步骤。
5、本申请的有益效果至少包括:本申请提供的基于人工智能的教育评价目标数据处理方法及系统,采用对感兴趣分布密度序列分箱得到的分箱信息段落,在教育评价文本中截取得到教育评价子文本进行识别,这样一来,相较于识别未处理的教育评价文本的不同段落分别进行识别,可以更准确识别教育评价文本中的细节信息,将第一感兴趣信息识别结果作为教育评价文本的第二感兴趣信息识别结果的补充,克服了因为感兴趣信息在教育评价文本中的分布随机性导致信息提取不准确的问题,换言之,本申请的方案中,针对感兴趣信息的提取更加精准,防止信息遗漏。
技术特征:1.一种基于人工智能的教育评价目标数据处理方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述对所述教育评价文本进行感兴趣分布密度序列预估,得到所述教育评价文本的感兴趣分布密度序列,包括:
3.根据权利要求2所述的方法,其特征在于,所述根据所述教育评价文本使用优化好的感兴趣分布密度序列预估算法进行感兴趣分布密度序列预估,得到所述教育评价文本的感兴趣分布密度序列,包括:
4.根据权利要求1所述的方法,其特征在于,所述对所述感兴趣分布密度序列进行信息分箱,得到所述感兴趣分布密度序列中的多个分箱信息段落,包括:
5.根据权利要求4所述的方法,其特征在于,所述不同粒度的隐式表示通过共享算子执行获得,所述共享算子包括特征提炼模块、组成方式相同的不少于一个第一共享分支算子和不少于一个第二共享分支算子;所述第一共享分支算子和所述第二共享分支算子均具有多个按序连接的阶段模块;
6.根据权利要求5所述的方法,其特征在于,所述根据所述特征提炼结果使用所述第一共享分支算子中的多个按序连接的阶段模块进行阶段处理,得到所述第一共享分支算子中每个阶段模块的阶段处理结果,包括:
7.根据权利要求6所述的方法,其特征在于,所述阶段模块包括基准阶段模块和移动阶段模块;所述根据所述第一共享分支算子的第s阶段处理结果使用所述第一共享分支算子中的第s+1阶段模块进行阶段处理,得到所述第一共享分支算子的第s+1阶段处理结果,包括:
8.根据权利要求7所述的方法,其特征在于,所述基准阶段模块包括基准框、规范化单元和前向神经单元;所述根据所述第一共享分支算子的第s阶段处理结果使用所述第一共享分支算子中的第s+1基准阶段模块进行阶段处理,得到所述第一共享分支算子的第s+1基准阶段处理结果,包括:
9.根据权利要求6所述的方法,其特征在于,所述初阶感兴趣信息识别是采用相同架构的不少于一个第一多粒度特征表示算法和不少于一个第二多粒度特征表示算法执行得到,所述第一多粒度特征表示算法的数量等于所述第一共享分支算子的数量,所述第二多粒度特征表示算法的数量等于所述第二共享分支算子的数量;所述对所述多个粒度不同的隐式表示进行初阶感兴趣信息识别,得到与每个所述粒度的隐式表示对应的初阶感兴趣信息识别结果,包括:
10.一种计算机系统,包括存储器和处理器,所述存储器存储有可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现权利要求1至9任一项所述方法中的步骤。
技术总结本申请提供一种基于人工智能的教育评价目标数据处理方法以及系统,采用对感兴趣分布密度序列分箱得到的分箱信息段落,在教育评价文本中截取得到教育评价子文本进行识别,这样一来,相较于识别未处理的教育评价文本的不同段落分别进行识别,可以更准确识别教育评价文本中的细节信息,将第一感兴趣信息识别结果作为教育评价文本的第二感兴趣信息识别结果的补充,克服了因为感兴趣信息在教育评价文本中的分布随机性导致信息提取不准确的问题,换言之,本申请的方案中,针对感兴趣信息的提取更加精准,防止信息遗漏。技术研发人员:胡文清,李静宜,李必飞,陈文芯,吕佳利,杨圣云,邹启新受保护的技术使用者:深圳云卷科技有限公司技术研发日:技术公布日:2025/1/6本文地址:https://www.jishuxx.com/zhuanli/20250110/353452.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。