TNFR1修饰的间充质干细胞及其制备方法和应用与流程
- 国知局
- 2025-01-10 13:37:59
本发明属于细胞治疗领域,具体涉及tnfr1修饰的间充质干细胞及其制备方法和应用。
背景技术:
1、间充质干细胞(mesenchymal stem cell,以下简称msc)是来源于发育早期中胚层的具有高度自我更新能力和多向分化潜能的多能干细胞,广泛存在于全身多种组织中。它不仅支持造血干细胞的生长,还可以在不同诱导条件下在体外分化为多种组织细胞如神经细胞、成骨细胞、软骨细胞、脂肪细胞、心肌细胞等。msc在体外易于培养,免疫原性低,具有免疫调节作用,目前被用于多种自身免疫性疾病的治疗。此外,msc具有促进组织再生的功能,被用于肝脏纤维化、多器官衰竭、糖尿病足等疾病的治疗。临床实验研究结果表明干细胞可长期有效缓解炎症性肠病,并且逐渐被临床指南认可。
2、原代未经修饰的间充质干细胞有异质性,输注的细胞有不同的亚群(并且各亚群的比例并不稳定),导致其功能也不稳定而不能完全发挥治疗效果;另外原始未经修饰的msc针对某个疾病的生物功能不够强大,不能持续表达生物功能分子,并且表达水平较低,也导致了治疗效果的差异。而修饰的msc能将与疾病相关的蛋白、因子等转入msc,使msc能持续高水平表达,从而驯化msc,使其成为均一化、稳定、生物功能强的msc药物,提高疾病的治疗效果。
3、目前间充质干细胞修饰用的载体多为病毒载体,包括慢病毒、腺病毒等。尽管病毒基因递送是高效的,但病毒载体会将目的基因向宿主基因组中随机整合,这可能会中断重要的基因表达和细胞过程;病毒载体的生产通常包括稳定生产系的原始细胞库的产生和认证,因此在基因、细胞治疗中造成了高成本。为弥补病毒载体的不足,非病毒递送系统因其低毒性、靶向递送的潜力、长期稳定性、dna装载量较高、化学结构可控、免疫原性较小、易于大量制备且生产成本相对较低而受到越来越多的关注。随着两款mrna疫苗被批准用于接种预防新冠病毒,mrna用于细胞的转染和修饰逐渐成为可能,由于mrna对于细胞的修饰无需进入细胞核,规避了整合入宿主基因组dna的风险,同时在转染mrna前,对mrna的结构元件进行修饰提高其稳定性,避免降解;因此选择mrna进行修饰间充质干细胞是一个可行的选择。
4、炎症性肠病(inflammatory bowel disease,ibd),主要包括溃疡性结肠炎(ulcerative colitis,uc)和克罗恩病(crohn's disease,cd),是一种主要累及胃肠道的慢性、非特异性、复发性、炎症性疾病。既往中国ibd罕见,但是近20年来,中国ibd发病率快速增长,ibd发病率为1.74/10万人年,其中uc发病率为1.18/10万人年,cd发病率为0.4/10万人年。目前,ibd已经成为我国消化系统常见的疑难疾病之一,是消化系统疾病基础研究和临床诊疗的重点、热点和难点。ibd多始发于青少年,具有复发性、进展性及致残性,严重影响患者的生长和发育、结婚和生育以及学习、工作和日常生活。ibd不仅累及消化道,而且累及消化道外几乎所有的器官和系统,还可继发消化道内外感染、肿瘤等并发症,是一种涉及临床多学科的系统性疾病。
5、近20余年来,虽然国内外学者对ibd的发生机制和临床诊疗进行了深入的研究,目前多数学者认为ibd的发病为感染、饮食、环境、精神心理等因素作用于遗传易感者,在肠道菌群的参与下,启动了肠道免疫和非免疫系统,使肠道黏膜对抗原呈高敏状态,免疫调节功能紊乱,最终导致肠黏膜细胞慢性炎症和组织细胞持久损伤且难以自限,而在这一过程中细胞因子和炎症介质间的相互作用扮演着重要角色。ibd涉及到的免疫因素包括t细胞、细胞因子和自身抗体等。
6、ibd的治疗暂时未发现能够治愈的药物和方法。
技术实现思路
1、针对现有技术中存在的上述技术问题,本发明在单抗等生物大分子制剂治疗ibd的基础上,针对ibd的发病机制,将tnfr1(肿瘤坏死因子受体1)的mrna用阳离子脂质体递送系统修饰msc,在降低基因修饰msc成本的同时,提高msc的免疫调节能力,通过开发mrna修饰的msc药物,可以解决单抗治疗后失应答的问题,提高ibd治疗的应答有效率,满足临床需求。
2、本发明技术方案如下:
3、本发明的第一个目的是提供修饰的tnfr1序列,所述修饰的tnfr1序列为seq idno.1所示核苷酸序列,或seq id no.1所示核苷酸序列的互补序列:
4、taatacgactcactatagggagatcagagagaaaagaagagtaagaagaaatataagagccaccgccaccatggggctaagcactgtcccggatctcctgctccccctggtactgctcgagctcctggtggggatctacccatcaggagttatcgggctagtaccacacctgggggaccgggagaaacgggacagtgtttgcccccagggcaagtatatccatccccagaacaactcgatttgttgtacaaagtgccacaaaggcacttatttgtacaacgactgcccgggccccgggcaggacactgattgcagggagtgcgagtcgggctcgttcaccgcgtcggagaaccacctgcgccattgtctttcctgcagcaaatgcaggaaagagatggggcaggtggagatctcctcctgcaccgtagaccgggacacggtctgcgggtgcaggaagaaccagtacaggcactactggagtgagaacctgtttcagtgttttaactgcagtttgtgcctgaacgggacagtgcacctgtcgtgtcaggagaagcagaacactgtttgtacctgtcacgcagggttcttcctgcgcgagaacgagtgcgtctcgtgctccaactgcaagaagtcgctggagtgcacaaagttgtgcctcccgcaaatcgagaatgttaaggggacggaggatagtggcaccacttgataataggctgccttctgcggggcttgccttctggccatgcccttcttctctcccttgcacctgtacctcttggtctttgaataaagcctgagtaggaaggcggccgctcgagcatgcatctagaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaatgcaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa(seq id no.1)。
5、进一步的,所述修饰的tnfr1序列通过以下修饰方式获得:
6、修饰前的tnfr1(在ncbi里的编号ncbi reference sequence:nm_001065.4)核苷酸序列为:
7、actcttcccctcccaccttctctcccctcctctctgctttaattttctcagaattctctggactgaggctccagttctggcctttggggttcaagatcactgggaccaggccgtgatctctatgcccgagtctcaaccctcaactgtcaccccaaggcacttgggacgtcctggacagaccgagtcccgggaagccccagcactgccgctgccacactgccctgagcccaaatgggggagtgagaggccatagctgtctggcatgggcctctccaccgtgcctgacctgctgctgccactggtgctcctggagctgttggtgggaatatacccctcaggggttattggactggtccctcacctaggggacagggagaagagagatagtgtgtgtccccaaggaaaatatatccaccctcaaaataattcgatttgctgtaccaagtgccacaaaggaacctacttgtacaatgactgtccaggcccggggcaggatacggactgcagggagtgtgagagcggctccttcaccgcttcagaaaaccacctcagacactgcctcagctgctccaaatgccgaaaggaaatgggtcaggtggagatctcttcttgcacagtggaccgggacaccgtgtgtggctgcaggaagaaccagtaccggcattattggagtgaaaaccttttccagtgcttcaattgcagcctctgcctcaatgggaccgtgcacctctcctgccaggagaaacagaacaccgtgtgcacctgccatgcaggtttctttctaagagaaaacgagtgtgtctcctgtagtaactgtaagaaaagcctggagtgcacgaagttgtgcctaccccagattgagaatgttaagggcactgaggactcaggcaccacagtgctgttgcccctggtcattttctttggtctttgccttttatccctcctcttcattggtttaatgtatcgctaccaacggtggaagtccaagctctactccattgtttgtgggaaatcgacacctgaaaaagagggggagcttgaaggaactactactaagcccctggccccaaacccaagcttcagtcccactccaggcttcacccccaccctgggcttcagtcccgtgcccagttccaccttcacctccagctccacctatacccccggtgactgtcccaactttgcggctccccgcagagaggtggcaccaccctatcagggggctgaccccatccttgcgacagccctcgcctccgaccccatccccaacccccttcagaagtgggaggacagcgcccacaagccacagagcctagacactgatgaccccgcgacgctgtacgccgtggtggagaacgtgcccccgttgcgctggaaggaattcgtgcggcgcctagggctgagcgaccacgagatcgatcggctggagctgcagaacgggcgctgcctgcgcgaggcgcaatacagcatgctggcgacctggaggcggcgcacgccgcggcgcgaggccacgctggagctgctgggacgcgtgctccgcgacatggacctgctgggctgcctggaggacatcgaggaggcgctttgcggccccgccgccctcccgcccgcgcccagtcttctcagatgaggctgcgcccctgcgggcagctctaaggaccgtcctgcgagatcgccttccaaccccacttttttctggaaaggaggggtcctgcaggggcaagcaggagctagcagccgcctacttggtgctaacccctcgatgtacatagcttttctcagctgcctgcgcgccgccgacagtcagcgctgtgcgcgcggagagaggtgcgccgtgggctcaagagcctgagtgggtggtttgcgaggatgagggacgctatgcctcatgcccgttttgggtgtcctcaccagcaaggctgctcgggggcccctggttcgtccctgagcctttttcacagtgcataagcagttttttttgtttttgttttgttttgttttgtttttaaatcaatcatgttacactaatagaaacttggcactcctgtgccctctgcctggacaagcacatagcaagctgaactgtcctaaggcaggggcgagcacggaacaatggggccttcagctggagctgtggacttttgtacatacactaaaattctgaagttaaa(seq id no.2);
8、分别修饰seq id no.2所示tnfr1序列的5’-非翻译区、编码区域、3’-非翻译区,构建修饰后的5’-非翻译区(utr)-修饰后的tnfr1 mrna序列编码区域(即图1所示tnfr1(cds))-修饰后的3’-非翻译区(utr),并在3’-非翻译区(utr)添加-poly-a尾;
9、所述修饰后的tnfr1 mrna序列编码区核苷酸序列如seq id no.3所示;
10、具体的,所述编码区域的修饰方式为将seq id no.2的第263bp~895bp处所示编码区域在不改变其氨基酸序列的基础上通过哺乳动物细胞密码子偏好设计优化基因序列,具体操作方法可通过https://www.vectorbuilder.cn在线优化,选择最佳密码子适应指数(cai)最高的序列。优化后的编码区序列为:
11、atggggctaagcactgtcccggatctcctgctccccctggtactgctcgagctcctggtggggatctacccatcaggagttatcgggctagtaccacacctgggggaccgggagaaacgggacagtgtttgcccccagggcaagtatatccatccccagaacaactcgatttgttgtacaaagtgccacaaaggcacttatttgtacaacgactgcccgggccccgggcaggacactgattgcagggagtgcgagtcgggctcgttcaccgcgtcggagaaccacctgcgccattgtctttcctgcagcaaatgcaggaaagagatggggcaggtggagatctcctcctgcaccgtagaccgggacacggtctgcgggtgcaggaagaaccagtacaggcactactggagtgagaacctgtttcagtgttttaactgcagtttgtgcctgaacgggacagtgcacctgtcgtgtcaggagaagcagaacactgtttgtacctgtcacgcagggttcttcctgcgcgagaacgagtgcgtctcgtgctccaactgcaagaagtcgctggagtgcacaaagttgtgcctcccgcaaatcgagaatgttaaggggacggaggatagtggcaccact(seq id no.3);
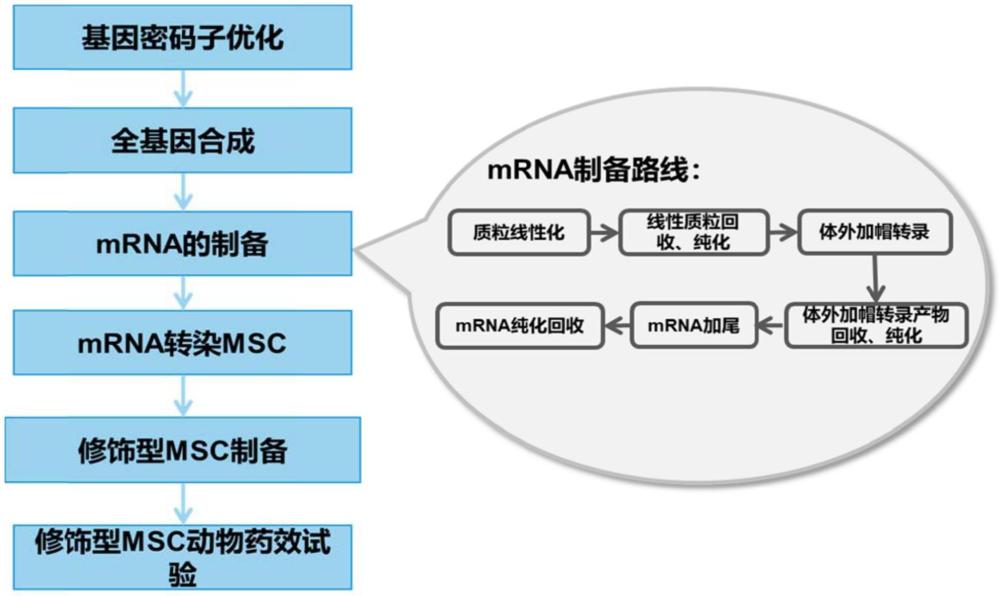
12、所述修饰后的5’-非翻译区核苷酸序列如seq id no.4所示;
13、5’-非翻译区修饰方式为将seq id no.2的第1bp~262bp处所示5’-非翻译区将替换为短于100bp核苷酸序列,规避mrna降解的风险;在某个实施例中,所述短于100bp核苷酸序列为taatacgactcactatagggagatcagagagaaaagaagagtaagaagaaatataagagccaccgccacc(seq id no.4)所述修饰后的3’-非翻译区核苷酸序列如seq id no.5所示;
14、3’-非翻译区修饰方式为选择珠蛋白作为seq id no.2的第1631bp~2171bp处所示3’-非翻译区,序列为:
15、gctgccttctgcggggcttgccttctggccatgcccttcttctctcccttgcacctgtacctcttggtctttgaataaagcctgagtaggaaggc ggccgctcgagcatgcatctaga(seq id no.5)。
16、末尾处添加poly-a尾的序列为:
17、aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaatgcaaaaaaaaaaaaaaaaaaaaaaa aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa(seq id no.6)。
18、本发明的第二个目的是提供修饰的tnfr1 mrna序列,为将修饰的tnfr1序列转录并在5’端加帽后得到。
19、进一步的,所述修饰的tnfr1 mrna序列如seq id no.7所示:
20、uaauacgacucacuauagggagaucagagagaaaagaagaguaagaagaaauauaagagccaccgccaccauggggcuaagcacugucccggaucuccugcucccccugguacugcucgagcuccugguggggaucuacccaucaggaguuaucgggcuaguaccacaccugggggaccgggagaaacgggacaguguuugcccccagggcaaguauauccauccccagaacaacucgauuuguuguacaaagugccacaaaggcacuuauuuguacaacgacugcccgggccccgggcaggacacugauugcagggagugcgagucgggcucguucaccgcgucggagaaccaccugcgccauugucuuuccugcagcaaaugcaggaaagagauggggcagguggagaucuccuccugcaccguagaccgggacacggucugcgggugcaggaagaaccaguacaggcacuacuggagugagaaccuguuucaguguuuuaacugcaguuugugccugaacgggacagugcaccugucgugucaggagaagcagaacacuguuuguaccugucacgcaggguucuuccugcgcgagaacgagugcgucucgugcuccaacugcaagaagucgcuggagugcacaaaguugugccucccgcaaaucgagaauguuaaggggacggaggauaguggcaccacuugauaauaggcugccuucugcggggcuugccuucuggccaugcccuucuucucucccuugcaccuguaccucuuggucuuugaauaaagccugaguaggaaggcggccgcucgagcaugcaucuagaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaugcaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa(seq id no.7)。
21、本发明的第三个目的是提供所述修饰的tnfr1 mrna序列的构建方法,为将前述修饰的tnfr1序列转录获得seq id no.7所示mrna序列并在5’端加帽后得到所述修饰的tnfr1mrna序列。
22、进一步的,所述方法包括以下步骤:
23、1)质粒线性化:取1-10μg含修饰的tnfr1序列的puc57-kan质粒,质粒载体为puc57-kan,加入1-5μl的ecori内切酶、5-25μl的ecori内切酶缓冲液并加双蒸水至终体系为50-200μl,在37℃下孵育30min-3h;
24、2)线性化质粒的纯化:使用fastpure gel dna extraction mini kit试剂盒对线性化后的质粒进行纯化,纯化后的产物经过凝胶电泳判断产物大小以及完整性无误后用于后续的体外转录实验;
25、使用fastpure gel dna extraction mini kit试剂盒对线性化后的质粒进行纯化,以50μl线性化体系为例,每体系加入50μl无核糖核酸酶水,再加入500μl的buffer gdp,混合均匀后转移到吸附柱中,离心弃除滤液,再加入洗脱液收集洗脱液,即为纯化后的线性质粒,最后经过凝胶电泳判断产物大小以及完整性无误后用于后续的体外转录实验;
26、3)体外转录加帽:使用hisynth t7 co-transcription rna synthesis kit试剂盒进行体外加帽共转录,取1-5μg线性质粒加入适量无核酸酶水中,再依次加入2-10μl的10×反应缓冲液,2-10μl的2×ntp/帽类似物以及1-5μl的t7 rna polymerase,混合均匀后在37℃下孵育2-3h,获得加帽的seq id no.7所示mrna;
27、4)mrna纯化:使用rna cleanup kit试剂盒进行纯化,每100μl加入200μl试剂盒中的浓缩结合液,混匀后再加入300μl无水乙醇混匀,高速离心过柱弃滤液;用0.1-1ml洗涤液高速离心清洗2次后用1-100μl洗脱液溶解加帽mrna并高速离心洗脱,收集滤液。
28、5)mrna的最终纯化:加入0.1-1ml清除结合缓冲液,混匀后再加入0.1-1ml无水乙醇混匀,高速离心过柱弃滤液;用0.1-1ml洗涤液高速离心清洗2次后,向滤柱中央滤膜中央加入提前预热的10-50μl无核酸酶水溶解加帽mrna并高速离心洗脱,收集滤液即完成高翻译稳定性tnfr1 mrna的制备。
29、本发明的第三个目的是提供mrna脂质体复合物,采用脂质体包封前述修饰的tnfr1mrna序列,脂质体与修饰的tnfr1 mrna序列的摩尔比为1:3-1:6,所述脂质体包括可电离阳离子脂质、胆固醇(chol)、中性辅助磷脂、peg脂质,所述可电离阳离子脂质为dlin-mc3-dma或dotap,中性辅助磷脂为dspc或dope,peg脂质为dspe-peg2000。
30、进一步的,mrna脂质体复合物中可电离阳离子脂质、胆固醇(chol)、中性辅助磷脂、peg脂质之间的摩尔比优选为40:40:10:5、40:40:10:10、40:40:10:15中的一种。
31、本发明的第四个目的是提供tnfr1修饰的间充质干细胞,tnfr1修饰的间充质干细胞采用前述mrna脂质体复合物转染间充质干细胞。
32、本发明的第五个目的是提供前述修饰的tnfr1序列或前述修饰的tnfr1 mrna序列或前述的mrna脂质体复合物或前述的tnfr1修饰的间充质干细胞在制备治疗炎症性肠病的药物中的应用。
33、本发明的有益效果在于
34、1)本发明设计和优化了tnfr1 mrna结构,获得优化后的稳定的tnfr1 mrna序列;
35、2)本发明建立了mrna-脂质体复合物,能够高效转染间充质干细胞。
36、3)将mrna转染msc获得赋能型干细胞:本发明所述mrna脂质体复合物能够安全、高效的对msc进行赋能,做到细胞活性和强化功能的平衡,具体为:通过mrna转染,mrna无需进入细胞核,规避了整合入宿主基因组dna带来的安全性风险;优化的mrna和阳离子脂质体复合物递送系统,实现mrna的高效转染,在保持细胞活率的前提下,使tnfr1在msc中高水平稳定表达
37、4)开展mrna基因修饰的间充质干细胞动物研究:建立ibd疾病动物模型,完成tnfr1修饰的间充质干细胞的治疗ibd的动物药效试验。
38、将tnfr1 mrna修饰的msc用于dss(葡聚糖硫酸钠)造模的ibd小鼠中,与模型组、未修饰msc相比,修饰的msc无论在个体体重的变化、疾病活动指数、结肠长度均有显著的差异,初步显示了良好的疗效,为其他免疫性疾病的治疗打下了坚实的基础。
本文地址:https://www.jishuxx.com/zhuanli/20250110/354369.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。