一种应用于害虫识别领域的视觉和知识多模态大模型算法
- 国知局
- 2025-01-10 13:43:13
本发明涉及害虫识别领域,具体为一种应用于害虫识别领域的视觉和知识多模态大模型算法。
背景技术:
1、在传统的害虫识别模型中,训练数据集主要依赖于人工标注的害虫图像样本。通常的流程是通过采集大量的害虫图像样本,再由领域专家对这些样本进行人工标注,以此形成训练集。在模型训练过程中,利用卷积神经网络(cnn)等图像识别算法对图像进行特征提取和分类。基于这种训练方法,识别模型能够逐步学习不同害虫的外部特征,从而对输入的图像进行分类,判断图像中的害虫种类。此外,现有的一些害虫识别技术也开始尝试引入先验知识,例如使用知识库或简单的规则系统,将专家的经验引入模型,以提升模型的识别能力。然而,这类方法的知识体系较为静态,无法适应复杂、多变的害虫图像特征,也难以通过模型学习动态优化其推理能力。
2、专利公开号为cn113673340b的中国专利文献公开了一种害虫种类图像识别方法及系统,通过引入空间注意力模块和通道注意力网络,对害虫图像更加精确的定位和跨通道的交互机制,并使害虫识别模型更加关注有效的通道,进而降低了图像背景对于害虫分类准确性的影响,提高了分类的精度,实现了对害虫种类的精准的识别,为农业植物保护领域做出了贡献;
3、然而现有技术中存在大规模害虫图像数据集的标注需要大量人工参与,既耗时又容易出错,严重影响了模型的训练效率和识别效果;传统识别模型对图像特征过于依赖,无法充分利用害虫知识图谱中的先验知识,导致模型在处理复杂图像和语义信息时表现不佳。
技术实现思路
1、针对现有技术的不足,本发明提供了一种应用于害虫识别领域的视觉和知识多模态大模型算法,通过自动标注生成的第一伪随机预测标签与第二伪随机预测标签经过多次迭代优化,逐步生成干净预测标签,解决了背景技术中提出的技术问题。
2、为实现以上目的,本发明通过以下技术方案予以实现:
3、一种应用于害虫识别领域的视觉和知识多模态大模型算法,算法用于害虫识别模型进行害虫的识别;识别方法,包括:
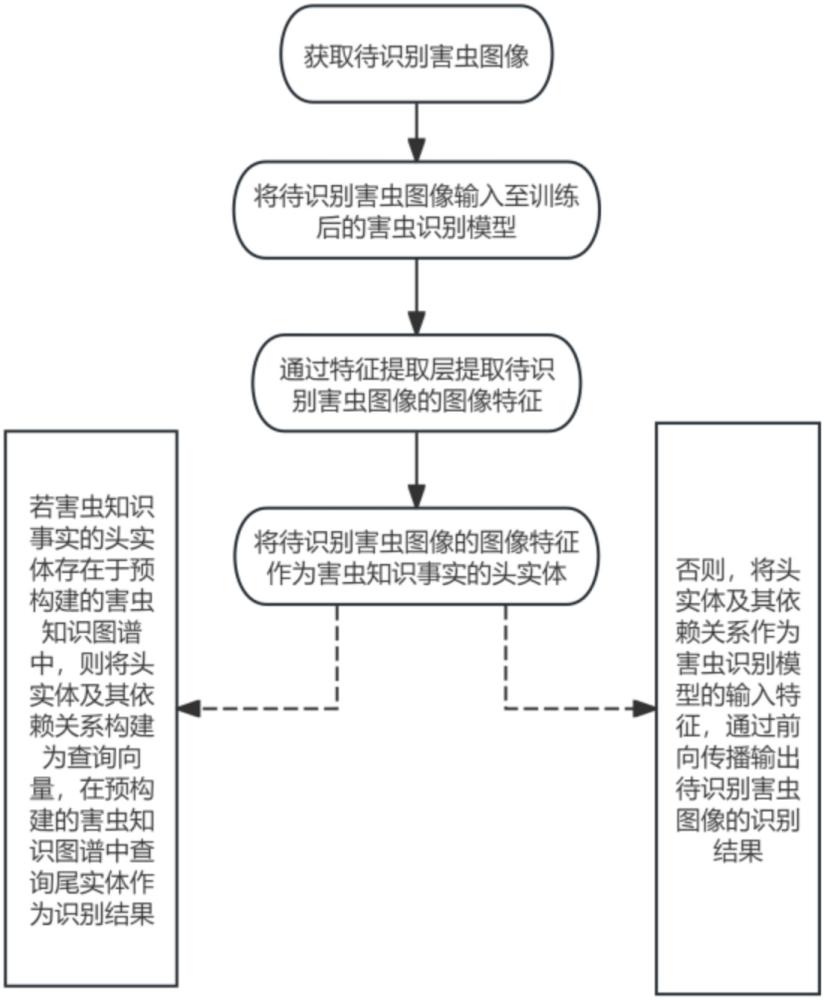
4、获取待识别害虫图像;
5、将待识别害虫图像输入至训练后的害虫识别模型;
6、通过特征提取层提取待识别害虫图像的图像特征;
7、将待识别害虫图像的图像特征作为害虫知识事实的头实体;
8、若害虫知识事实的头实体存在于预构建的害虫知识图谱中,则将头实体及其依赖关系构建为查询向量,在预构建的害虫知识图谱中查询尾实体作为识别结果;
9、否则,将头实体及其依赖关系作为害虫识别模型的输入特征,通过前向传播输出待识别害虫图像的识别结果。
10、在其中的一些实施例中,害虫识别模型的训练流程包括:
11、s1.获取害虫图像训练集,害虫图像训练集的训练样本是具有干净预测标签的害虫图像样本;
12、s2.使用害虫图像训练集训练知识图谱模型;其中,知识图谱模型嵌入有预构建的害虫知识图谱;
13、s3,若训练至收敛条件,停止训练导出具有当前迭代模型参数的知识图谱模型作为害虫识别模型。
14、在其中的一些实施例中,获取害虫图像训练集,包括:
15、s1-1.获取若干未标注的害虫图像样本并将其构建为初始图像集;
16、s1-2.接收初始图像集的害虫图像样本作为大模型的输入特征,输出第一伪随机预测标签;
17、输出第一伪随机预测标签的表达式为:
18、表示初始图像集中第q个害虫图像样本的第一伪随机预测标签,表示激活函数,表示大模型的权重矩阵,表示初始图像集中第q个害虫图像样本的图像特征,表示大模型的偏置项;
19、s1-3.将带有第一伪随机预测标签的害虫图像样本构建为伪随机标注集;
20、s1-4.通过伪随机标注集自训练小模型,得到干净预测标签;
21、s1-5.选择干净预测标签对应的害虫图像样本,构建害虫图像训练集。
22、在其中的一些实施例中,通过伪随机标注集自训练小模型,包括:
23、s1-4-1.接收伪随机标注集的害虫图像样本作为小模型的输入特征,输出第二伪随机预测标签;
24、输出第二伪随机预测标签的表达式为:
25、表示伪随机标注集中第q个害虫图像样本的第二伪随机预测标签,表示小模型的权重矩阵,表示伪随机标注集中第q个害虫图像样本的图像特征,表示小模型的偏置项;
26、s1-4-2.对第一伪随机预测标签编码,生成第一伪随机真实标签;
27、s1-4-3.计算第二伪随机预测标签和第一伪随机真实标签的分类损失;
28、分类损失的表达式为:
29、表示分类损失,n表示害虫图像样本数量,k表示类别标签总数,表示第i个样本的第一伪随机真实标签,表征样本i属于类别标签j的预测概率,表示第i个样本的第二伪随机预测标签,表征小模型输出的样本i属于类别标签j的预测概率,表示第i个样本的第二伪随机预测标签的对数,用于计算交叉熵损失;
30、s1-4-4.根据预设的小损失策略,判定分类损失是否低于预设损失值;
31、判定分类损失是否低于预设损失值的表达式为:
32、表示预设损失值,预设损失值表示允许的最大分类损失;
33、s1-4-5.选择低于预设损失值的分类损失对应的第二伪随机预测标签,确定为干净预测标签。
34、在其中的一些实施例中,使用害虫图像训练集训练知识图谱模型,包括:
35、s2-1.将害虫知识图谱的头实体定义为知识图谱模型的输入特征.尾实体定义为知识图谱模型的输出标签.关系定义为知识图谱模型中头实体和尾实体之间的依赖关系,构建真实的害虫知识事实;
36、构建真实的害虫知识事实的表达式为:
37、t表示真实的害虫知识事实,表征在害虫知识图谱中的一个关系实体,表示头实体,表示依赖关系,表征头实体与尾实体之间的关联,表示尾实体,表征与头实体通过依赖关系连接的对象;
38、s2-2.接收害虫图像训练集中的害虫图像样本作为知识图谱模型输入特征,通过图像特征提取得到害虫图像样本的特征向量;
39、s2-3.给定害虫图像样本的特征向量作为害虫知识事实的头实体,基于头实体与依赖关系,输出预测的尾实体,以得到预测的害虫知识事实;
40、得到预测的害虫知识事实的表达式为:
41、
42、表示预测的害虫知识事实,表示给定的害虫图像样本的特征向量;表示知识图谱模型预测的尾实体,表示知识图谱模型的权重矩阵,是知识图谱模型的偏置项;
43、s2-4.计算预测的害虫知识事实和真实的害虫知识事实之间的匹配度;
44、计算预测的害虫知识事实和真实的害虫知识事实之间的匹配度的表达式为:
45、
46、表示预测的害虫知识事实和真实的害虫知识事实之间的匹配度,表示给定的害虫图像样本的特征向量和尾实体向量之间的范数;
47、s2-5.根据匹配度计算害虫知识事实损失;
48、计算害虫知识事实损失的表达式为:
49、
50、表示害虫知识事实损失,表示负样本害虫知识事实和真实的害虫知识事实之间的匹配度,表示预测超参数,表示非负符号;
51、s2-6.执行反向传播,逐步调整模型参数,以得到最小化害虫知识事实损失。
52、在其中的一些实施例中,执行反向传播,包括:
53、s2-6-1,获取当前迭代的害虫知识事实损失,计算当前迭代的害虫知识事实损失相对于模型参数的梯度;
54、s2-6-2,根据模型参数的梯度,将其反向传播,得到更新后模型参数
55、s2-6-3,根据更新后模型参数,执行下一迭代的前向传播,输出预测尾实体。
56、在其中的一些实施例中,收敛条件包括:害虫知识事实损失达到预设损失阈值或训练轮次达到预设最大训练次数。
57、在其中的一些实施例中,根据查询向量在预构建的害虫知识图谱中查询尾实体作为识别结果,包括:
58、获取害虫知识事实(h,r,x),其中,h是已获取的头实体,r是已获取的头实体和待识别尾实体x之间的依赖关系;
59、在预构建的害虫知识图谱中,查询是否存在已获取头实体h;若存在,将已获取的头实体h和依赖关系r构建为查询向量q;
60、使用查询向量在预构建的害虫知识图谱中查询,根据头实体和依赖关系,选择确定的尾实体作为查询的识别结果。
61、本发明提供了一种应用于害虫识别领域的视觉和知识多模态大模型算法,通过自动标注生成的第一伪随机预测标签与第二伪随机预测标签经过多次迭代优化,实现了自动化标签生成,减少了人工干预和时间成本,大幅提高了高质量训练集构建效率;能在标签不足或标注不全的情况下,依赖知识图谱提供的背景信息,增强模型的推理能力,从而提高害虫识别准确性。
本文地址:https://www.jishuxx.com/zhuanli/20250110/354915.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。