用于医疗大模型的医学元数据处理和去标识化方法、系统
- 国知局
- 2025-01-17 13:04:25
本发明涉及大数据处理,尤其涉及一种用于医疗大模型的元数据处理和去标识化方法、系统。
背景技术:
1、在当前大数据和人工智能技术的快速发展背景下,大模型已逐渐展现出在医疗领域的重要临床意义,尤其是在辅助诊断、病情预测及个性化治疗等方面。在国际上,chatdoctor 模型是由美国麻省理工学院研发的一款医学大模型, 该模型可以通过自然语言处理技术,实现与患者的自然对话,从而提供精准的医疗咨询和服务。此模型的研发是为了解决现有大型语言模型(如 chatgpt)在医学知识上的局限性,其通过使用来自在线医疗咨询平台的10 万个患者-医生对话,该模型的准确性得到了显著提高。此外,disc-med llm 模型是由斯坦福大学研发的一款医学大模型,该模型可以通过深度学习技术,对大量的医疗文献进行学习和理解,从而为医生提供更精确的诊断参考;为了构建高质量的监督微调(sft)数据集,disc-med llm 模型采用了三种策略:利用医学知识图谱、重构真实世界的对话以及结合人工引导的偏好重述,这些策略在训练 disc-med llm 中起到了关键作用,超越了现有的医学 llms 在单轮和多轮咨询场景中的表现。 在国内,hua tuo 模型是由中国科学院计算技术研究所研发的一款医学大模型,该模型可以通过深度学习技术,对大量的医疗影像数据进行学习和理解,从而为医生提供更精确的诊断参考。hua tuo 模型不仅基于开源的 llama-7b 基模型,还整合了来自中文医学知识图谱(c me kg)的结构化和非结构化医学知识。
2、医学元数据是指医学数据的描述性信息,它帮助解释、管理和使用具体的医学数据。医学元数据包括但不限于数据来源、采集时间、数据类型、数据质量、数据格式和标准、数据的相关性和依赖性、以及数据的安全和隐私信息等。 医学元数据的高效治理是医学大模型研发的基础保障。不管国际还是国内,因为医学元数据为单病种数据、数据量有限等原因,基于上述医学模型开发的众多ai产品均存在产品适用单一场景和单一功能的问题。大规模高质量医学数据集是医学大模型研发的核心基础,因此如何实现多模态数据、多中心数据的标准化、同质化、系统化治理迫在眉睫。
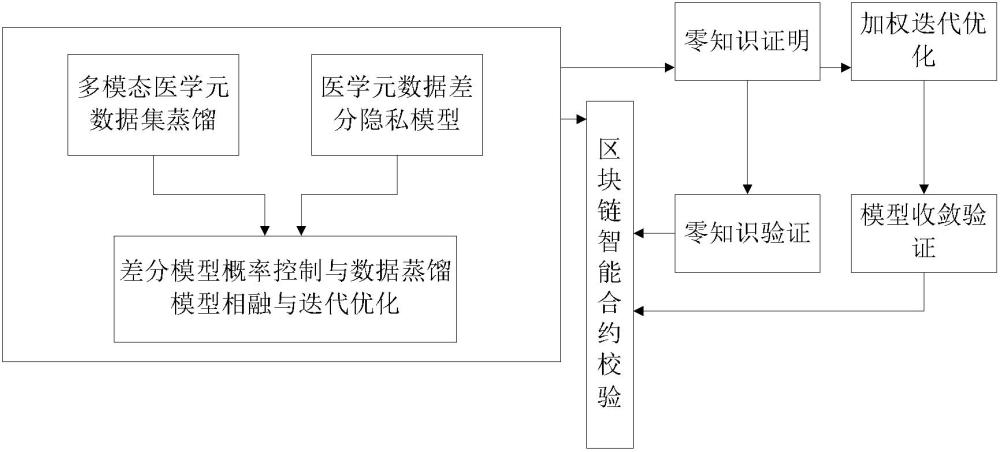
3、医学模型的训练和构造需要大量的数据作为支撑,大规模数据训练的需求直接带来两个问题:(1)存储资源、计算资源、训练时间消耗过大;(2)隐私信息容易泄露。这些客观问题的存在已经明显阻碍了可支持医疗大模型训练的医疗数据集的分享并进一步阻碍了相关技术的进一步发展。虽然,针对上述问题,现有技术中有提出多种数据隐私保护的分享方法,如差分隐私保护方法,提供了一套严谨的数学框架,用于量化和控制随机查询或统计分析中数据隐私的泄露风险,平衡数据分析和隐私保护的需求,成为涉及敏感数据应用中的一种重要隐私保护工具;然而,将传统差分隐私方法融入模型的训练会降低模型的性能,此外还会增加模型训练成本。因此,如何均衡高质量医学数据分享与数据隐私保护也是需要解决的技术问题。
技术实现思路
1、鉴于上述问题,提出了本发明以便提供一种克服上述问题或者至少部分地解决上述问题的技术方案。
2、本发明提供一种用于医疗大模型的医学元数据处理和去标识化方法,该方法包括:基于初始数据蒸馏模型对医学元数据进行压缩,生成压缩后的数据;利用压缩后的数据对数据蒸馏模型进行训练,生成优化后的模型参数;利用优化后的模型参数对压缩后的数据继续压缩;所述压缩步骤和训练步骤交替迭代,直至模型参数收敛。
3、可选的,在所述压缩步骤和训练步骤,分别对医学元数据和模型参数执行相同的算法模型。
4、可选的,基于初始数据蒸馏模型对医学元数据进行压缩,生成压缩后的数据,包括:基于初始数据蒸馏模型对第一模态医学元数据和第二模态医学元数据的差分数据进行压缩;利用优化后的模型参数对压缩后的数据继续压缩,包括:利用优化后的模型参数对压缩后的第一模态医学元数据和第二模态医学元数据的差分数据继续压缩;非当前任务的医学元数据为第二模态医学元数据,当前任务的医学元数据为第一模态医学元数据。
5、可选的,第一模态医院元数据的差分系数采用 beta 随机函数确定。
6、可选的,在对医学元数据进行压缩之前,该方法还包括:依据预先建立的医学元数据标准将原始医疗数据分为不同类型的模态;根据与所述类型的模态对应的标准进行数据采集;对所采集的数据进行特征数据提取;依据分级标识原则对提取后的特征数据进行去隐私处理;对去隐私处理后的特征数据进行标注;对标注后的特征数据进行量化管理并存储,生成医学元数据。
7、本发明还提供一种用于医疗大模型的医学元数据处理和去标识化方法,该方法包括:将离散的文本转换到连续的特征空间,生成文本特征;将文本特征作为条件输入,基于初始数据蒸馏模型,对医学元数据进行压缩,生成压缩后的数据;利用压缩后的数据、文本特征对数据蒸馏模型进行训练,生成优化后的模型参数;利用优化后的模型参数将文本特征作为条件输入对压缩后的数据继续压缩;所述压缩步骤和训练步骤交替迭代,直至模型参数收敛。
8、可选的,通过预训练好的文本大模型将离散的文本转换到连续的特征空间。
9、可选的,该方法还包括:利用压缩前的医学元数据进行医疗大模型的迭代式训练,获得每轮的梯度值,作为第一梯度值;利用压缩后的医学元数据进行医疗大模型的迭代式训练,获得每轮的梯度值,作为第二梯度值;判断每轮的第一梯度值、第二梯度值是否相似,在相似的情况下,判断压缩前后的医学元数据对医疗大模型进行训练的效果相近。
10、可选的,在每轮进行迭代式训练时,第二梯度值加上一个噪声,以实现压缩后的医学元数据达到预定隐私级别。
11、本发明提供一种用于医疗大模型的医学元数据处理和去标识化系统,该系统包括:蒸馏压缩模块,用于基于初始数据蒸馏模型对医学元数据进行压缩,生成压缩后的数据;蒸馏训练模块,用于利用压缩后的数据对数据蒸馏模型进行训练,生成优化后的模型参数;所述蒸馏压缩模块利用优化后的模型参数对压缩后的数据继续压缩;所述蒸馏压缩模块与蒸馏训练模块交替迭代执行压缩操作、训练操作,直至模型参数收敛。
12、本发明提供一种用于医疗大模型的医学元数据处理和去标识化系统,该系统包括:文本转换模块,用于将离散的文本转换到连续的特征空间,生成文本特征;蒸馏压缩模块,用于将文本特征作为条件输入,基于初始数据蒸馏模型,对医学元数据进行压缩,生成压缩后的数据;蒸馏训练模块,利用压缩后的数据、文本特征对数据蒸馏模型进行训练,生成优化后的模型参数;所述蒸馏压缩模块利用优化后的模型参数将文本特征作为条件输入对压缩后的数据继续压缩;所述蒸馏压缩模块与蒸馏训练模块交替迭代执行压缩操作、训练操作,直至模型参数收敛。
13、本发明提供一种计算机设备,该计算机设备包括处理器和存储器,所述存储器上存储有计算机程序,所述计算机程序由处理器执行时,执行前面所述的医学元数据处理和去标识化方法。
14、本发明能够实现在信息几乎不丢失的情况下以最小的数据量支持特定任务的模型高效训练,使得在浓缩后的数据集上训练出的模型与在原数据集上训练而成的模型表现相似。通过上述方法压缩重构后的数据具有泛用性,能支持不同架构的人工智能模型训练。
15、上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述技术方案和其目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
本文地址:https://www.jishuxx.com/zhuanli/20250117/356064.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表