一种基于边缘计算的风险数据检测方法及系统与流程
- 国知局
- 2025-01-17 13:07:47
本发明涉及基于边缘计算的风险数据检测,特别涉及一种基于边缘计算的风险数据检测方法及一种基于边缘计算的风险数据检测系统。
背景技术:
1、风险数据通常指在边缘计算环境中产生、传输或存储的,可能对系统、网络、设备或业务造成潜在威胁或不利影响的数据。这些数据可能具有以下特点和表现形式:异常的数据流量模式:例如突然出现的大量数据传输,或者流量方向、频率等方面的异常变化。错误或不完整的数据:可能导致系统处理错误、决策失误或业务流程中断。敏感信息的泄露或未经授权的访问:如个人身份信息、商业机密等。来自不可信源的数据:来源不明或被认为具有潜在风险的数据源提供的数据。与已知的安全威胁模式相关的数据:例如与病毒、恶意软件活动相关的数据特征。不符合预设规则或策略的数据操作:比如超出权限的数据修改、删除等。
2、边缘计算中的数据产生速度快,需要及时检测风险数据,但由于资源限制和网络延迟等因素,可能无法做到实时准确检测。
技术实现思路
1、本发明的主要目的为提供一种基于边缘计算的风险数据检测方法,旨在解决现有技术中的技术问题。
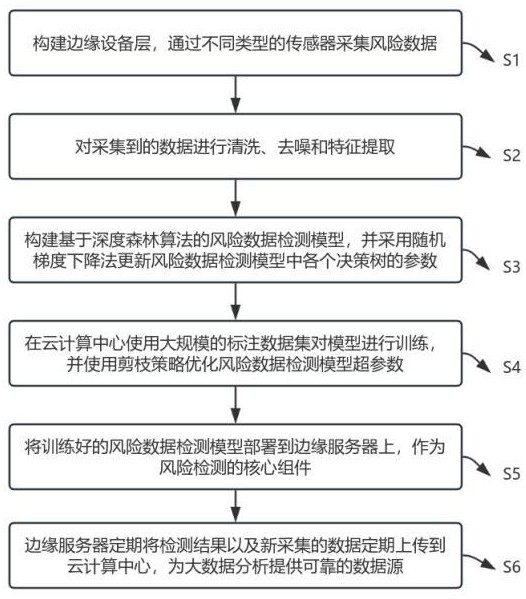
2、本发明提出一种基于边缘计算的风险数据检测方法,包括:
3、s1、构建边缘设备层,通过不同类型的传感器采集风险数据。
4、s2、对采集到的数据进行清洗、去噪和特征提取。
5、s3、构建基于深度森林算法的风险数据检测模型,并采用随机梯度下降法更新风险数据检测模型中各个决策树的参数。
6、s4、在云计算中心使用大规模的标注数据集对模型进行训练,并使用剪枝策略优化风险数据检测模型超参数,具体步骤包括:
7、s41、从公开数据集或行业内部获取大量的标注数据,涵盖各种类型的风险场景,并对数据进行清洗和预处理,确保数据质量,并将预处理后的数据集划分为训练集、验证集和测试集。
8、s42、采用云计算资源对风险数据检测模型进行大规模并行训练,利用验证集对模型进行调优,使用剪枝策略优化风险数据检测模型超参数。
9、s43、在测试集上评估训练后的模型性能,计算准确率、召回率、f1值指标,根据评估结果,进一步优化模型结构和训练策略,直到达到预期的性能目标。
10、s5、将训练好的风险数据检测模型部署到边缘服务器上,作为风险检测的核心组件。
11、s6、边缘服务器定期将检测结果以及新采集的数据定期上传到云计算中心,为大数据分析提供可靠的数据源。
12、作为优选,在步骤s1中,所述采集风险数据包括:
13、s11、在边缘设备层部署各种传感器设备,用于采集原始数据,传感器包括温度传感器、湿度传感器、压力传感器、电流传感器,分别用于采集设备运行状态的相应物理量。通过摄像头采集视频图像数据。
14、s12、根据监测对象的特点,使用奈奎斯特采样定理设置数据采样频率,公式表达为:
15、 ;
16、式中,为采样频率,为信号的最高频率。
17、s13、根据风险数据类型选择相应的数据格式。
18、s14、根据预设的数据传输协议,对风险数据进行传输。
19、作为优选,在步骤s2中,包括:
20、s21、数据清洗,包括:采用z-score标准化方法检查数据中的异常值,剔除超出合理范围的数据点和明显的错误数据等。使用平均值填充处理缺失值。并消除数据中的重复项,减少冗余,其中,所述z-score标准化公式为:
21、 ;
22、式中,x为数据点,为样本均值,为样本标准差,当∣z∣大于设定阈值时,认为该数据点为异常值。
23、所述平均值填充公式为:
24、 ;
25、式中,m是数据集中非缺失值的数量。
26、s22、数据去噪,利用傅里叶变换对数据进行频域分析,识别并去除噪声成分,连续时间信号的傅里叶变换定义为:
27、 ;
28、式中,是的频谱,是角频率,j是虚数单位,是复指数函数。
29、s23、将熵值作为数据特征指标,提取数据的重要特征。
30、作为优选,所述熵值的计算公式为:
31、 ;
32、式中,为随机变量y取值的概率。
33、作为优选,在步骤s3中,构建基于深度森林算法的风险数据检测模型包括:
34、s31、根据特征提取结果,选择与风险检测相关性较高的特征作为模型输入并使用相关系数指标对特征进行评估和筛选,所述相关系数的表达式为:
35、 ;
36、式中,和分别是两个变量的第i个观测值,和分别是a和b的均值,n是观测值的数量,相关系数r的取值范围在-1到1之间。
37、s32、将预处理后的数据集划分为训练集、验证集和测试集。
38、s33、构建多个深度决策树模型,每个模型的结构为:
39、 ;
40、式中,为第t棵决策树的检测结果。
41、将全部决策树模型集成起来,形成风险数据检测模型:
42、 ;
43、式中,k为决策树的数量。
44、s34、采用随机梯度下降更新风险数据检测模型各个决策树的参数。
45、s35、在测试集上评估模型的检测性能,包括准确率、召回率、f1值指标。
46、作为优选,随机梯度下降公式为:
47、 ;
48、式中,是在第t次迭代时的模型参数,是更新后的模型参数,是学习率,控制参数更新的步长,是损失函数l关于参数的梯度,在给定的样本上计算。
49、作为优选,准确率的公式为:
50、 ;
51、召回率的公式为:
52、 ;
53、f1值的公式为:
54、 ;
55、其中,
56、 ;
57、式中,tp表示被正确检测为正例的样本数量,tn表示被正确检测为负例的样本数量,fp表示被错误检测为正例的样本数量,fn表示被错误检测为负例的样本数量。
58、作为优选,风险数据检测模型超参数的过程包括:
59、s421、将减少模型的复杂度,避免过拟合,提高模型的泛化能力作为剪枝目标。
60、s422、根据节点分裂带来的信息增益评估指标衡量决策树中的节点的重要性。
61、s423、权衡模型复杂度和泛化能力及重要性计算结果,设定剪枝阈值。
62、s424、删除重要性低于剪枝阈值的节点及其相关的分支。
63、s425、剪枝后,对模型进行微调,包括重新训练和调整其他超参数。
64、作为优选,所述信息熵的公式为:
65、 ;
66、式中,i是信息熵,是类别k在节点中对比例。
67、信息增益的公式为:
68、 ;
69、式中,n是父节点的样本数量,是子节点i的样本数量,i(p)表示父节点的信息熵,表示第i个子节点的信息熵。
70、本技术还提供一种基于边缘计算的风险数据检测系统,包括:
71、数据采集模块,其用于采集风险数据。包括温度传感器、湿度传感器、压力传感器、电流传感器和摄像头,分别用于采集设备运行状态的温度、湿度、压力、电流和视频图像数据。
72、数据预处理模块,其用于对采集到的数据进行清洗、去噪和特征提取。
73、风险数据检测模块,其用于构建基于深度森林算法的风险数据检测模型,采用随机梯度下降法更新风险数据检测模型各个决策树的参数。
74、模型训练优化模块,其用于在云计算中心使用大规模标注数据集对检测模型进行训练,并使用剪枝策略优化风险数据检测模型的超参数。
75、边缘部署模块,其用于将优化后的风险数据检测模型部署到边缘服务器上,作为风险检测的核心组件。
76、数据上传模块,其用于将边缘服务器定期将检测结果和新采集的数据上传到云计算中心,为大数据分析提供可靠的数据源。
77、本发明的有益效果为:通过在边缘设备层部署各种传感器,可以实时采集与风险相关的各种物理量数据,部署摄像头可以获取视频图像数据,从而充分感知环境和设备的运行状态,为后续的数据分析和风险检测提供高质量的原始数据支撑;通过数据预处理消除数据中的各种干扰因素,提高数据的信噪比;通过特征提取技术,从原始数据中提取出与风险检测相关的关键特征,减少数据的冗余度,为后续的模型训练提供更有效的输入;从而大幅降低云端的计算开销,提高整个系统的响应速度;采用深度森林算法构建风险数据检测模型,具有更强的表达能力和泛化性能;使用随机梯度下降法更新模型参数,可以提高检测模型的收敛速度和预测准确性,可以确保边缘设备上的风险检测模型具有较高的性能和鲁棒性;采用剪枝策略对模型的超参数进行调优,可以进一步提高模型的泛化能力和检测的准确性。
本文地址:https://www.jishuxx.com/zhuanli/20250117/356254.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。