一种游戏玩法场景的实时推荐方法及系统与流程
- 国知局
- 2024-07-11 16:11:21
本发明涉及信息推荐领域,具体而言,涉及一种游戏玩法场景的实时推荐方法及系统。
背景技术:
1、推荐业务当前覆盖各种领域,包括实体行业、电信行业以及当前覆盖面最广的互联网行业。互联网中推荐形式也存在不同,包括但不限于公众号、视频、新闻、广告、图片等。推荐方法也从一开始的热度推广、人为策略、统计学习、机器学习、到深度学习模型。同时也从实时到非实时,推荐精度精准到小时、分钟,精准到个人,不同人不同时间不同场景推荐不同的内容。真正的达到千人千面个性化推荐的效果。
2、推荐场景的落地范围广,这也是推荐技术受人追捧的原因之一。但是如何在游戏app中将推荐技术灵活应用于不同具体业务中,需要克服的问题还是非常多的,包括推荐目标、推荐样本、推荐策略、推荐模型、推荐服务等如何设计与构建。
技术实现思路
1、有鉴于此,本发明提供一种游戏玩法场景的实时推荐方法及系统,以解决上述问题。
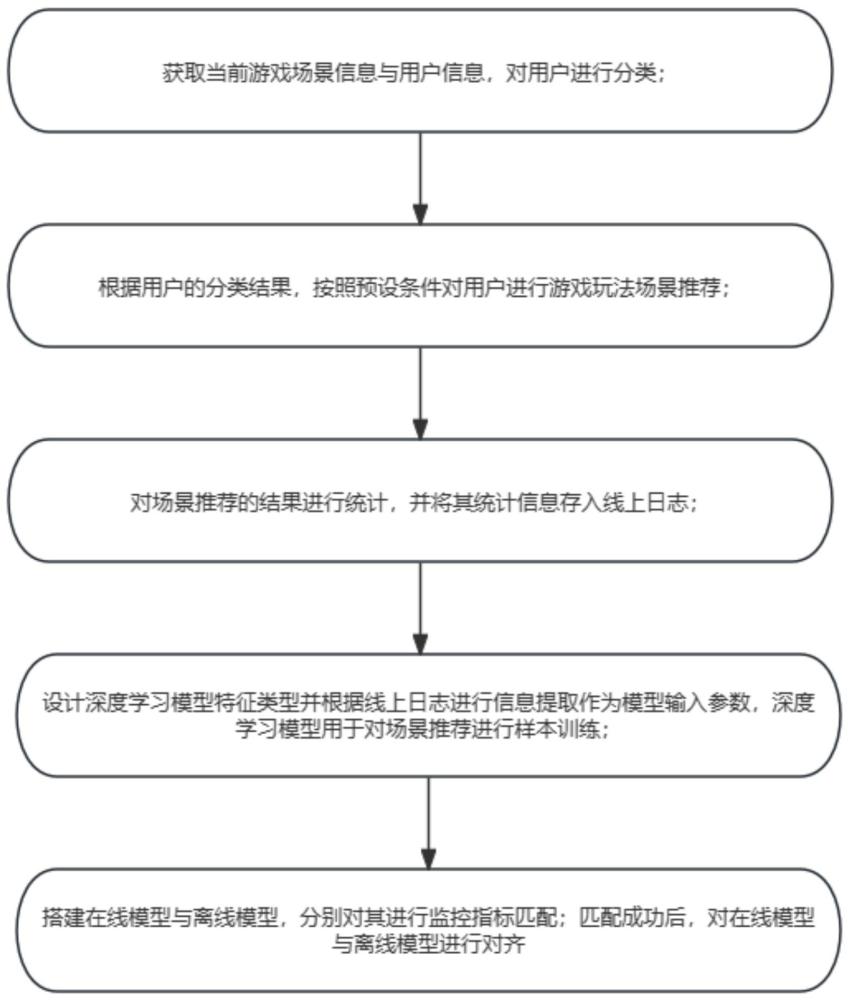
2、为解决以上技术问题,本发明提供了一种游戏玩法场景的实时推荐方法,包括:
3、获取当前游戏场景信息与用户信息,对用户进行分类;
4、根据用户的分类结果,按照预设条件对用户进行游戏玩法场景推荐;
5、对场景推荐的结果进行统计,并将其统计信息存入线上日志;
6、设计深度学习模型特征类型并根据线上日志进行信息提取作为模型输入参数,深度学习模型用于对场景推荐进行样本训练;
7、搭建在线模型与离线模型,分别对其进行监控指标匹配;匹配成功后,对在线模型与离线模型进行对齐;对齐包括:
8、随机批量抽取当日样本来对在线模型与离线模型进行评估,判断其对样本的处理逻辑是否对齐,否则进行告警。
9、作为一种可选方式,对用户进行分类包括:
10、统计用户特征信息,按照u2u构建用户与用户的行为相似度关联,并按照预设条件进行场景推荐;其中,用户特征信息为用户的属性信息及行为信息,
11、作为一种可选方式,预设条件包括:
12、设计推荐逻辑,对行为库中的用户与游戏的历史交互信息进行行为统计,将用户的行为进行清洗与筛选后,确定推荐需求、触发条件与上报类型,并对用户使用过程中符合推荐需求的触发行为进行上报;其中,
13、上报的内容包括:通用内容、用户内容、目标对象内容与行为信息。
14、作为一种可选方式,对场景推荐的结果进行统计,并将其统计信息存入线上日志包括:
15、再次统计用户信息,继续线上日志积累;在预设时间后对线上日志继续数据提取,构建模型样本;其中,
16、数据提取还包括对提取信息的归因处理,包括:拉长时间窗口,并关联不同的因子进行归因获得实际归因关系。
17、作为一种可选方式,设计深度学习模型特征类型:
18、在线上日志中进行特征信息提取,特征信息包括连续型特征、文本型特征、图片型特征与数值型特征;
19、对特征信息进行离散化处理,构建与用户绑定的用户画像与物料画像;并进行特征复杂度增加操作,以提高用户样本区分度,降低用户行为标签的冲突率。
20、作为一种可选方式,深度学习模型用于对场景推荐进行样本训练之前,包括:
21、引入混合专家模型,对深度学习模型进行优化;并设计深度学习模型的训练模式,设计模型训练模式包括:
22、以天数为频次对模型进行数据添加与更新,分段训练密集参数与稀疏参数,包括:在训练的初始日期对初始数据进行添加与更新操作,训练生成初始模型;
23、将上一天更新后的数据作为下一天的添加数据进行更新,按照天数频次进行重复操作,直到训练日期截止,生成最终深度学习模型。
24、作为一种可选方式,监控指标包括:auc、pcoc与gauc;
25、作为一种可选方式,判断其对样本的处理逻辑是否对齐,包括:
26、离线模型更新后,在离线训练时随机选择该模型进行训练的特征,将其处理后传入离线模型,得到该特征在离线模型的处理结果;
27、通过在线服务部署在线模型后,输入离线训练时选择的训练特征,将其在线处理后输入在线模型得到在线模型的处理结果,判断离线模型的处理结果与在线模型的处理结果的插值是否符合阈值。
28、作为一种可选方式,通过kubernetes框架搭建在线模型,并进行托管;采用tensorflow serving热更新机制与本地离线模型进行通讯。
29、另一方面,本发明还提供了一种基于游戏的场景实时推荐系统,包括存储器和处理器,存储器存储有基于游戏的场景实时推荐方法的程序,处理器用于在运行程序时执行上述项方法的步骤。
30、本发明的有益效果为:
31、本发明通过策略与算法结合互相反哺的方式,将深度模型推荐技术在目标item与用户数据少的基础上提升收益,激发用户活跃。并通过结合游戏场景下独有样本复杂性高于目标复杂性特性,创建更符合业务的game-moe网络结构。
技术特征:1.一种游戏玩法场景的实时推荐方法,其特征在于,包括:
2.根据权利要求1所述的一种游戏玩法场景的实时推荐方法,其特征在于,所述对用户进行分类包括:
3.根据权利要求2所述的一种游戏玩法场景的实时推荐方法,其特征在于,所述预设条件包括:
4.根据权利要求1所述的一种游戏玩法场景的实时推荐方法,其特征在于,所述对场景推荐的结果进行统计,并将其统计信息存入线上日志包括:
5.根据权利要求4所述的一种游戏玩法场景的实时推荐方法,其特征在于,所述设计深度学习模型特征类型:
6.根据权利要求1所述的一种游戏玩法场景的实时推荐方法,其特征在于,所述深度学习模型用于对场景推荐进行样本训练之前,包括:
7.根据权利要求1所述的一种游戏玩法场景的实时推荐方法,其特征在于,所述监控指标包括:auc、pcoc与gauc。
8.根据权利要求1所述的一种游戏玩法场景的实时推荐方法,其特征在于,所述判断其对样本的处理逻辑是否对齐,包括:
9.根据权利要求1所述的一种游戏玩法场景的实时推荐方法,其特征在于,通过kubernetes框架搭建在线模型,并进行托管;采用tensorflow serving热更新机制与本地离线模型进行通讯。
10.一种基于游戏的场景实时推荐系统,其特征在于,包括:存储器和处理器,所述存储器存储有基于游戏的场景实时推荐方法的程序,所述处理器用于在运行所述程序时执行所述权利要求1-9任一项方法所述的步骤。
技术总结本发明公开了一种游戏玩法场景的实时推荐方法及系统,包括:获取当前游戏场景信息与用户信息,对用户进行分类;根据用户的分类结果,按照预设条件对用户进行游戏玩法场景推荐;对场景推荐的结果进行统计,并将其统计信息存入线上日志;设计深度学习模型特征类型并根据线上日志进行信息提取作为模型输入参数,深度学习模型用于对场景推荐进行样本训练;搭建在线模型与离线模型,分别对其进行监控指标匹配;匹配成功后,对在线模型与离线模型进行对齐,否则进行告警。本发明通过策略与算法结合互相反哺的方式,将深度模型推荐技术在目标item与用户数据少的基础上提升收益,激发用户活跃。并通过结合游戏场景,创建了更符合业务的Game‑MOE网络结构。技术研发人员:王瑜受保护的技术使用者:成都帆点创想科技有限公司技术研发日:技术公布日:2024/4/22本文地址:https://www.jishuxx.com/zhuanli/20240615/77955.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表