兵棋智能体的训练方法、预测方法及相应系统
- 国知局
- 2024-07-11 16:28:26
本公开总体说来涉及计算机,更具体地讲,涉及一种兵棋智能体的训练方法、预测方法及相应系统。
背景技术:
1、兵棋推演是一种模拟现实战争的游戏,其状态动作空间复杂度远高于棋牌类游戏,且具有不完美信息、长时决策等特点,能够为更复杂智能决策技术的研究提供策略验证环境。
2、现有智能体的构建方法可以分为基于知识规划、基于有监督学习和基于强化学习三类。基于知识规划的智能体通过有限状态自动机、规则系统、条件树、参数化脚本等技术编码人类专家高水平知识,构建智能体决策策略,擅于处理相对固定的常见战场态势,具备优秀的可解释性和良好的性能。基于有监督学习的智能体通过计算模型与复盘数据在相同状态下生成策略的差异作为监督信号来指导模型向数据拟合,这使得智能体在获得应对高维状态和动作空间能力的同时,摆脱了复杂的人工规则设计,并且与更复杂的强化学习等方法相比具有显著简单轻量、容易训练的优点。基于强化学习的智能体通过在环境中的探索试错,根据环境反馈的奖励不断调整自身策略,以实现最大化累积奖励的目标,这种机制与人类的学习过程一致,具有超越人类水平的潜能,近年来在游戏博弈领域屡创佳绩。
3、兵棋推演中智能体的构建面临多项挑战,然而目前缺乏一套适配兵棋推演特点且能够高效获得具备良好决策水平智能体的系统和方法。
技术实现思路
1、本公开的示例性实施例在于提供一种兵棋智能体的训练方法、预测方法及相应系统,其针对兵棋推演奖励稀疏、决策因素复杂、状态转移随机性高等特点,提出一种更适合兵棋推演特点的智能体构建系统和方法,通过系统结构和相应方法流程的创新实现具有更高性能智能体的高效获取。
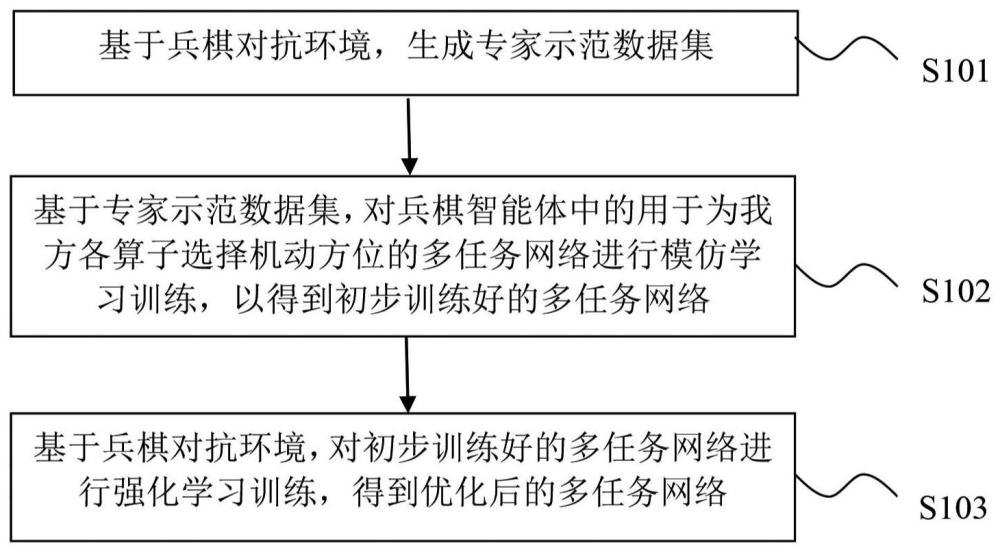
2、根据本公开实施例的第一方面,提供一种兵棋智能体的训练方法,所述训练方法包括:基于兵棋对抗环境,生成专家示范数据集;基于所述专家示范数据集,对所述兵棋智能体中的用于为我方各算子选择机动方位的多任务网络进行模仿学习训练,以得到初步训练好的多任务网络;基于所述兵棋对抗环境,对初步训练好的多任务网络进行强化学习训练,得到优化后的多任务网络;其中,所述专家示范数据集包括:所述多任务网络决策所需的态势特征、我方的n个算子的机动方位标签,n为大于1的整数。
3、可选地,所述多任务网络包括:共享特征处理分支和n个算子分支,所述n个算子分支与所述n个算子一一对应;其中,所述共享特征处理分支的输入量包括:兵棋对抗整体的态势特征,所述共享特征处理分支的输出量包括:共享特征;其中,第i个算子分支的输入量包括:所述共享特征和第i个算子自身的态势特征,所述第i个算子分支的输出量包括:为所述第i个算子选择的机动方位,i为大于0且小于或等于n的整数。
4、可选地,所述第i个算子分支包括:第一卷积神经网络模块、第一注意力机制模块、第二注意力机制模块、第三注意力机制模块、拼接模块、基于自注意力机制的深度学习模块、输出模块;所述共享特征处理分支包括:第一多层感知机模块、第二多层感知机模块、第二卷积神经网络模块;其中,所述第一卷积神经网络模块的输入量包括所述第i个算子自身的位置特征,所述第一注意力机制模块的输入量包括所述第一卷积神经网络模块的输出量和所述第二卷积神经网络模块的输出量,所述第二注意力机制模块的输入量包括所述第二多层感知机模块的输出量,所述第三注意力机制模块的输入量包括所述第一多层感知机模块的输出量,所述拼接模块的输入量包括所述第一注意力机制模块的输出量、所述第二注意力机制模块的输出量以及所述第三注意力机制模块的输出量,所述深度学习模块的输入量包括所述拼接模块的输出量,所述输出模块的输入量包括所述深度学习模块的输出量,所述输出模块的输出量包括为所述第i个算子选择的机动方位;其中,所述第一多层感知机模块的输入量包括兵棋对抗整体统计特征,所述第二多层感知机模块的输入量包括所有参与方各算子的属性状态特征、所述第二卷积神经网络模块的输入量包括兵棋对抗整体空间特征。
5、可选地,基于兵棋对抗环境生成专家示范数据集的步骤包括:获取用户使用所述兵棋对抗环境产生的复盘数据;对所述复盘数据进行质量筛选;基于筛选出的复盘数据,生成所述专家示范数据集。
6、可选地,基于所述专家示范数据集,对所述多任务网络进行模仿学习训练的步骤包括:使用行为克隆算法,训练所述多任务网络对所述专家示范数据集进行拟合,以使所述多任务网络输出的我方各算子机动方位的数据分布情况逼近所述专家示范数据集中的机动方位标签的数据分布情况。
7、可选地,基于所述兵棋对抗环境,对初步训练好的多任务网络进行强化学习训练的步骤包括:使用强化学习算法,通过与所述兵棋对抗环境进行交互,对初步训练好的多任务网络的参数进行更新。
8、可选地,使用强化学习算法,通过与所述兵棋对抗环境进行交互,对初步训练好的多任务网络的参数进行更新的步骤包括:在强化学习训练的每轮迭代中,基于当前的兵棋对抗环境获取所述多任务网络决策所需的态势特征输入到所述多任务网络,并在所述兵棋对抗环境中按照所述多任务网络为我方各算子选择的机动方位来控制我方各算子动作,以更新所述兵棋对抗环境;以实现所述兵棋对抗环境对动作的奖励的累积和最大化为目标,对所述多任务网络的参数进行更新。
9、根据本公开实施例的第二方面,提供一种兵棋智能体的预测方法,所述预测方法包括:基于当前的兵棋对抗环境,获取所述兵棋智能体中的多任务网络决策所需的态势特征;将获取的态势特征输入到所述多任务网络,得到所述多任务网络为我方各算子选择的机动方位;在所述兵棋对抗环境中按照所述多任务网络为我方各算子选择的机动方位来控制我方各算子动作;其中,所述兵棋智能体是通过执行如上所述的训练方法而训练得到的。
10、根据本公开实施例的第三方面,提供一种兵棋智能体的训练系统,所述训练系统包括:专家数据生成装置,被配置为基于兵棋对抗环境,生成专家示范数据集;模仿学习训练装置,被配置为基于所述专家示范数据集,对所述兵棋智能体中的用于为我方各算子选择机动方位的多任务网络进行模仿学习训练,以得到初步训练好的多任务网络;强化学习训练装置,被配置为基于所述兵棋对抗环境,对初步训练好的多任务网络进行强化学习训练,得到优化后的多任务网络;其中,所述专家示范数据集包括:所述多任务网络决策所需的态势特征、我方的n个算子的机动方位标签,n为大于1的整数。
11、根据本公开实施例的第四方面,提供一种兵棋智能体的预测系统,所述预测系统包括:态势表示装置,被配置为基于当前的兵棋对抗环境,获取所述兵棋智能体中的多任务网络决策所需的态势特征;预测装置,被配置为将获取的态势特征输入到所述多任务网络,得到所述多任务网络为我方各算子选择的机动方位;动作控制装置,被配置为在所述兵棋对抗环境中按照所述多任务网络为我方各算子选择的机动方位来控制我方各算子动作;其中,所述兵棋智能体是通过执行如上所述的训练方法而训练得到的。
12、根据本公开实施例的第五方面,提供一种存储指令的计算机可读存储介质,当所述指令由电子设备的处理器执行时,使得所述电子设备能够执行如上所述的训练方法和/或预测方法。
13、根据本公开实施例的第六方面,提供一种电子设备,所述电子设备包括:至少一个处理器;至少一个存储计算机可执行指令的存储器,其中,所述计算机可执行指令在被所述至少一个处理器运行时,促使所述至少一个处理器执行如上所述的训练方法和/或预测方法。
14、根据本公开实施例的第七方面,提供一种计算机程序产品,包括计算机可执行指令,所述计算机可执行指令被至少一个处理器执行时实现如上所述的训练方法和/或预测方法。
15、根据本公开的示例性实施例的兵棋智能体的训练方法、预测方法及相应系统,提供了一种将训练数据集与强化学习训练环境有序结合的系统结构与训练流程,支持模仿学习与强化学习集成的智能体训练,能够提升训练效率,并可获得更高性能的智能体。
16、在接下来的描述中,将会阐述本公开总体构思的一些方面和/或优点,还有一些方面和/或优点将通过下述描述或者本公开总体构思的实施而得知。
本文地址:https://www.jishuxx.com/zhuanli/20240615/79538.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。