一种基于无监督和分组机制的动态加权个性化联邦元学习故障诊断方法
- 国知局
- 2024-07-31 22:53:46
:本发明涉及工业设备的零部件故障诊断,尤其是涉及基于联邦学习的故障诊断方法。
背景技术
0、背景技术:
1、旋转机械设备在航空航天、石油化工、风电、交通运输、医疗设备等领域发挥着至关重要的作用,轴承、齿轮等设备关键部件的故障将直接影响系统的安全性。因此,监测运行状态并识别发生的故障对机械设备的正常运行具有重要意义。
2、随着人工智能技术的发展,智能诊断方法已成为机械故障诊断的“主力军”。尽管智能诊断方法取得了成功,但这些方法需要利用足够和全面的训练数据。然而,在真实的工业场景中,考虑到经济和时间因素,用户通常很难收集足够的训练数据。这种情况制约了智能诊断方法在真实的工业中的应用。一个理想的选择是直接聚合多个用户数据,这样可以大大节省获取样本时间成本。但在实践中,由于行业竞争、利益冲突、隐私安全等问题,数据源之间存在难以打破的壁垒。这些数据只能掌握在业主自己手中,难以实现信息交换和数据整合。即使在同一家公司的不同部门,由于隐私安全、数据安全或复杂的管理流程,数据也无法集成。因此,直接聚合多个用户数据在真实的行业中并不可行。
3、满足隐私保护和数据安全的联邦学习技术是上述情况的解决方案之一。联邦学习的本质是一种分布式机器学习技术,该技术的特点是用户在本地进行模型训练,无需上传原始数据。由第三方服务器协调各用户共同训练一个全局模型,并使用同态加密、差分隐私等技术加密传输中间参数。相比传统的诊断模型,联邦学习技术不需要集中原始数据,也没有后续的数据传输和公开共享,这可以确保数据隐私。在实际的工业应用中,这个方法仍然表现出明显的缺点:1)忽略了客户端上只存在数据而缺少标签的情况。没有对这些客户群体进行优化。2)忽略了客户来自于不同集群的可能性,高度非独立同分布的数据会严重影响模型的性能。
4、为此,现有技术需要进一步改进和完善。
技术实现思路
0、技术实现要素:
1、本发明提供了一种基于无监督和分组机制的动态加权个性化联邦元学习故障诊断方法,不仅能够让拥有无标签数据的客户端参与联邦学习的训练,还可以为每个客户端提供一个最适合本地数据集的模型。
2、为达到上述目的,本发明采用如下技术方案:
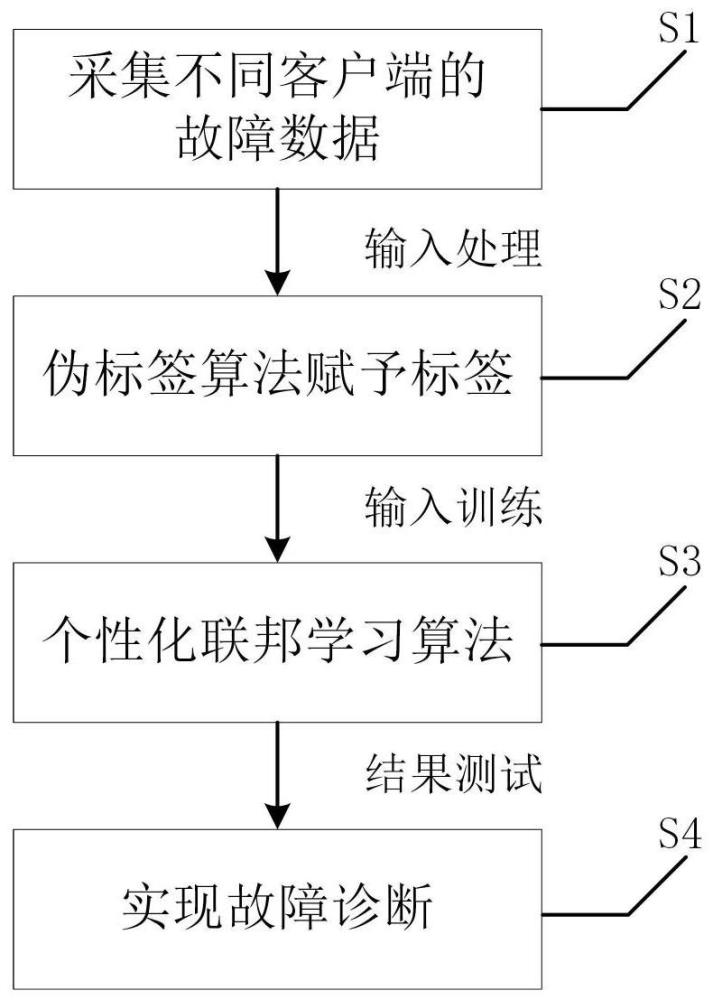
3、一种基于无监督和分组机制的动态加权个性化联邦元学习故障诊断方法,包括以下步骤:
4、s1、采集不同设备(工况)下的故障轴承的振动信号作为不同客户端的初始数据集;
5、s2、针对有数据但无标签的客户端,使用基于局部离群因子的伪标签算法为所有的样本信号打上伪标签。然后服务器向此客户端发送仿真数据,通过计算仿真数据与真实数据的欧式距离,从而得到真实标签;
6、s3、针对客户间可能存在非独立同分布数据,设计一种基于分组机制的个性化联邦元学习算法。每个数据集都会经过特征工程提取出峰值、平均值和均方根等特征值构建特征矩阵,然后计算这组数据集的聚类中心并上传到服务器。通过计算不同客户端之间的聚类中心的距离,使得距离相近,即特征相似的客户端放在一组训练全局模型;
7、s4、在每个全局模型的训练过程中,引入了元学习策略。每个客户端的数据集被划分为支持集和查询集,每个客户端接收到全局模型之后,在自己的支持集上进行微调得到新模型,然后在查询集上测试得到损失值。这个损失值被用来更新全局模型;
8、s5、引入了动态加权组合更新参数策略。根据设计的公式计算出当前客户端可以从其他客户端模型中受益多少,来有效地得到每个客户端的最佳加权模型组合。
9、上述方案进一步是,所诉步骤s2中使用基于局部离群因子的伪标签算法,它的整体过程如下:
10、假设某客户端上有多段不知类别的信号,先抽取一段为基准数据并赋予伪标签,再从基准数据之外选取一段为比较数据。然后把他们都划分为相同数量的子样本。这些子样本组成比较数据集,然后使用局部离群因子算法(lof)在比较数据集上进行异常检测。理论上,两段不同类别信号的子样本组成的比较数据集的异常样本比例会更高,所以,当比例大于设定阈值时,则判定为非同类,打上不同的伪标签。当比例小于设定阈值时,则判定为同类,打上相同的伪标签。接着选取下一段信号作为比较数据。通过上述过程循环可以为所有同类别的信号打上相同的伪标签。
11、上述方案进一步是,所诉步骤s5中动态加权组合更新参数策略过程如下:
12、每个客户端在本地数据的支持集上微调完自己的模型之后,为了更近一步提高本地模型的性能,根据公式计算出当前客户端可以从其他客户端模型中受益多少,来有效地得到每个客户端的最佳加权模型组合。其中权重的公式如下:
13、
14、其中i为本地客户端,n为其他客户端。θ代表模型参数,l代表模型在本地数据的查询集中测试得到的损失值。如果wn是负值,表明客户端n的模型在本地客户端i的数据上表现不好,它的参数不会被采纳。此外,分母代表了本地客户端和其他客户端模型参数之间的差异,物理意义为在关注模型性能的同时避免不同客户端之间的模型参数差异过大,从而提高泛化能力避免过拟合。最终,本地客户端i的参数更新如下:
15、θi(t)←θi(t-1)+∑n∈[n]wn(θn(t)-θn(t-1))
16、本发明使用了一种基于局部离群因子的无监督算法,使得无标签客户端也能顺利参与联邦学习。同时针对客户端之间的故障数据存在高度非独立同分布问题,提出了一种基于分组机制的联邦学习框架,并且在每个全局模型的训练中引入了元学习和动态加权组合更新参数策略;与传统的用于故障诊断的联邦学习方法相比,不仅考虑了各种客户端所处的环境,同时能够提高模型的性能,提升了轴承故障诊断准确性,并能及时诊断轴承健康状态,降低经济损失。
技术特征:1.一种基于无监督和分组机制的动态加权个性化联邦元学习故障诊断方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于无监督和分组机制的动态加权个性化联邦元学习故障诊断方法,其特征在于,所诉步骤s2中使用基于局部离群因子的伪标签算法,它的整体过程如下:
3.根据权利要求1所述的一种基于无监督和分组机制的动态加权个性化联邦元学习故障诊断方法,其特征在于,所诉步骤s5中使动态加权组合更新参数策略具体如下:
技术总结本发明公开了一种基于无监督和分组机制的动态加权个性化联邦元学习故障诊断方法,旨在提高机械故障诊断的准确性和效率。该方法首先通过采集不同设备下的故障轴承振动信号,为缺乏标签的数据集生成伪标签。进一步,通过设计一种个性化的联邦元学习算法,将特征相似的客户端进行分组,以处理非独立同分布数据的问题。此外,该方法引入动态加权策略,优化全局模型更新过程。通过这种方式,该方法不仅能有效利用分布式数据,还能根据每个客户端的数据特性,动态调整学习策略,最终实现更为精确和个性化的故障诊断。技术研发人员:蒋飞,邝毅聪,李涛,卢沛聪,刘振华,吴兆乾受保护的技术使用者:东莞理工学院技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/195225.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表