兼具身份保持和编辑灵活性的人脸定制化生成方法
- 国知局
- 2024-07-31 23:17:24
本发明涉及兼具身份保持和编辑灵活性的人脸定制化生成方法,属于图像生成领域。
背景技术:
1、人脸定制生成技术旨在依据特定身份的图像和文本描述,创造出与文本场景相匹配的身份图像。该任务具有广泛的应用场景,如个性化写真制作和艺术创作等。随着文本到图像生成大模型的发展,人脸定制化生成任务也取得了巨大的进步。通过将人物身份编码到文生图大模型的特征空间中,现有的方法可以生成照片级的定制化图像。
2、目前,人脸定制化生成的方法主要分为两类:基于优化和基于编码。基于编码的方法在推理时所需的资源更少,从而拥有更为广泛的实际应用潜力。然而,这类方法往往难以同时实现身份特征的保留和图像内容的高度可编辑性,这限制了它们在满足用户真实需求方面的能力。因此,开发既能保持身份一致性又具备高度编辑灵活性的人脸定制生成技术,是当前领域中一个亟待解决的问题。
技术实现思路
1、本发明目的是为了解决传统人脸定制化生成的方法难以同时实现身份特征的保留和图像内容的高度可编辑性的问题,本发明提供了一种兼具身份保持和编辑灵活性的人脸定制化生成方法。
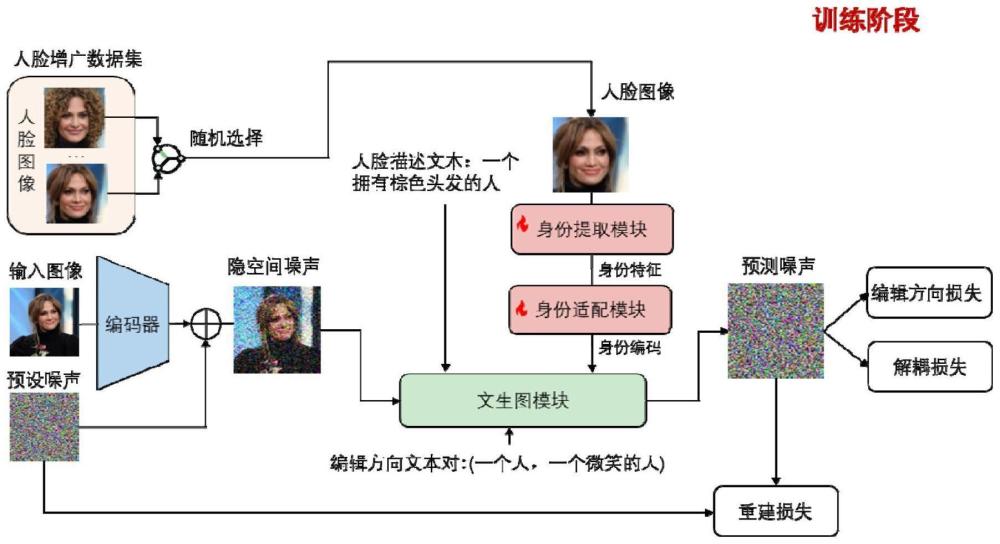
2、兼具身份保持和编辑灵活性的人脸定制化生成方法,该方法基于由身份提取模块、身份适配模块和文生图模块构成的噪声预测模块实现;该方法包括如下步骤:
3、s1、构建的训练样本:
4、对输入图像进行裁剪得到人脸图像,对人脸图像进行图像增广,得到人脸增广数据集;
5、对输入图像进行编码后添加预设噪声,得到隐空间噪声;
6、由输入图像、人脸增广数据集中的任意一张人脸图像、隐空间噪声、人脸描述文本和编辑方向文本对形成一个训练样本;编辑方向文本对包括源描述文本和目标描述文本;
7、s2、利用各训练样本对噪声预测模块进行训练,获得训练后的噪声预测模块:
8、身份提取模块对各训练样本中的人脸图像进行身份特征提取,提取到的身份特征通过身份适配模块进行编码,得到原始身份编码;对原始身份编码进行增广,得到增广身份编码;
9、文生图模块根据各训练样本所对应的原始身份编码、隐空间噪声和人脸描述文本生成原始预测噪声;还根据各训练样本所对应的增广身份编码、隐空间噪声和人脸描述文本生成增广预测噪声;还根据各训练样本所对应的隐空间噪声和编辑方向文本对生成无人脸信息的源预测噪声和无人脸信息的目标预测噪声;还根据各训练样本所对应的隐空间噪声、编辑方向文本对和人脸图像生成有人脸信息的源预测噪声和有人脸信息的目标预测噪声;
10、根据各训练样本所对应的预设噪声和原始预测噪声,获取重建损失
11、根据各训练样本所对应的增广预测噪声和原始预测噪声,获取解耦损失
12、根据各训练样本所对应的所有源预测噪声和目标预测噪声,获取编辑方向损失
13、根据重建损失、解耦损失和编辑方向损失,利用梯度下降算法对身份提取模块和身份适配模块进行参数更新,从而完成对噪声预测模块的训练;
14、s3、将待定制人脸图像、预设隐空间噪声、人脸描述文本输入至训练后的噪声预测模块生成预测噪声,从该预测噪声中剔除预设隐空间噪声后进行解码,得到定制化图像。
15、优选的是,根据各训练样本所对应的预设噪声和原始预测噪声,获取重建损失的实现方式包括:
16、
17、式中,∈表示预设噪声,为期望分布,∈θ'(zt,t,τ(y),f)为原始预测噪声,f为原始身份编码,‖·‖2为l2范数,t是时间步长,zt是t时间的隐空间噪声,τ(y)表示目标描述文本的文本特征。
18、优选的是,文生图模块根据各训练样本所对应的增广预测噪声和原始预测噪声,获取解耦损失的实现方式包括:
19、
20、式中,∈θ′(zt,t,τ(y),f)为原始预测噪声,∈θ′(zt,t,τ(y),a(f))为增广预测噪声,m为人脸图像中人脸区域的掩码,f为原始身份编码,t是时间步长,zt是t时间的隐空间噪声,τ(y)表示目标描述文本的文本特征,a(f)为增广身份编码。
21、优选的是,文生图模块根据各训练样本所对应的隐空间噪声和编辑方向文本对生成无人脸信息的源预测噪声和无人脸信息的目标预测噪声的实现方式包括:
22、将各训练样本所对应的隐空间噪声和编辑方向文本对中的源描述文本y输入至文生图模块,生成无人脸信息的源预测噪声;
23、将各训练样本所对应的隐空间噪声和编辑方向文本对中的目标描述文本y′输入至文生图模块,生成无人脸信息的目标预测噪声。
24、优选的是,文生图模块根据各训练样本所对应的隐空间噪声、编辑方向文本对和人脸图像生成有人脸信息的源预测噪声和有人脸信息的目标预测噪声的实现方式包括:
25、将各训练样本所对应的隐空间噪声、编辑方向文本对中的源描述文本y和人脸图像输入至文生图模块,生成有人脸信息的源预测噪声;
26、将各训练样本所对应的隐空间噪声、编辑方向文本对中的目标描述文本y′和人脸图像输入至文生图模块,生成有人脸信息的目标预测噪声。
27、优选的是,根据各训练样本所对应的所有源预测噪声和目标预测噪声,获取编辑方向损失的实现方式包括:
28、
29、
30、
31、式中,sim(·)为余弦相似度度量,m为人脸图像中人脸区域的掩码,为无人脸图像输入时所对应的编辑方向文本对的参考噪声编辑方向,y和y′分别为编辑方向文本对中的源描述文本和目标描述文本;为有人脸图像输入时所对应的编辑方向文本对的预测噪声编辑方向,∈θ(zt,t,τ(y)为无人脸信息的源预测噪声,∈θ(zt,t,τ(y′))为无人脸信息的目标预测噪声,∈θ'(zt,t,τ(y),f)为有人脸信息的源预测噪声,∈θ'(zt,t,τ(y′),f)为有人脸信息的目标预测噪声,f为原始身份编码,m为人脸图像中人脸区域的掩码,t是时间步长,zt是t时间的隐空间噪声,τ(y)表示源描述文本的文本特征,τ(y′)表示目标描述文本的文本特征。
32、优选的是,对人脸图像进行图像增广采用基于文本的人脸属性编辑网络实现。
33、优选的是,对人脸图像进行图像增广的增广属性包含发型、表情、年龄和饰品中的一种或多种。
34、优选的是,身份提取模块采用可学习的交叉注意力层、前向网络和自注意力层级联组成的神经网络实现。
35、优选的是,身份适配模块采用2m个独立的可学习的线性层所形成的神经网络实现。
36、本发明的优点:
37、本发明基于由身份提取模块、身份适配模块和文生图模块构成的噪声预测模块实现定制化图像信息的噪声预测;训练阶段引入解耦损失编辑方向损失和重建损失对身份提取模块、身份适配模块进行训练,采用解耦损失可以促进模型学习忠实的身份特征;采用编辑方向损失和人脸增广数据集可以有效提升定制化图像的可编辑性;因此,本发明可以生成照片级定制化人脸图像的同时,可以通过文本灵活的定制生成场景。
38、解耦损失通过约束身份编码变化前后,背景区域的噪声保持不变来有效地解耦身份信息和背景信息之间的解耦,从而提升生成的定制化图像的身份保持特性。
39、编辑方向损失中,表示了原始文生图中一个与身份无关的属性编辑方向(如发型和表情等),当约束本发明的属性方向与其相似(这里采用余弦相似度度量)时,即可有效地保留原始文生图模型的编辑先验,从而使得本发明训练后的模型的定制化图像具有灵活的编辑性。此外,由于编辑方向和仅与属性相关而与身份无关,采用编辑方向损失训练网络不会影响定制化图像的身份保持特性。
40、增广人脸图像与输入图像为同一身份不同属性的图像,该样本对训练可以有效地促进属性解耦的身份特征学习,从而提升定制化人脸图像的编辑灵活性。
本文地址:https://www.jishuxx.com/zhuanli/20240730/196832.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表