一种基于不平衡感知图神经网络的欺诈预测方法
- 国知局
- 2024-07-31 23:25:26
本发明属于欺诈检测,具体涉及一种基于不平衡感知图神经网络的欺诈预测方法。
背景技术:
1、随着社会的发展,各领域的欺诈行为日益增多,导致重大损失。在招聘领域,虚假招聘信息会欺骗求职者提供个人信息或支付费用,从而浪费他们的努力,并可能导致严重的身份盗用问题。同样,一些复杂的虚假在线网站也构成了严重威胁,骗子通过创建看似合法的门户网站来获取用户的凭证和敏感的财务数据,从而造成经济损失并泄露隐私。因此,欺诈检测在当今发挥着至关重要的作用。有效的欺诈检测策略有利于识别和减少各个领域的欺诈事件,保护个人和企业的安全。
2、欺诈检测不是一件小事。在过去几十年里,各种预测性机器学习模型已被用于应对这一挑战。然而,欺诈检测的效果往往会因为该领域的数据不平衡问题而大打折扣。通常,欺诈者的数量可能远远少于良性欺诈者的数量。例如,在一个信用卡交易数据集中,284807笔交易中仅有0.172%是欺诈交易;在一个职位描述数据集中,17014个合法职位中仅有4.8%是欺诈职位。为了缓解数据不平衡问题,人们开发了一些平衡方法,包括对多数类进行降采样,对少数类进行升采样,或混合使用这几种方法。尽管效果有所改善,但这些方法往往没有考虑到用户信息相似性所产生的潜在语义关系,尤其是在以用户为中心的欺诈检测中。
3、随着图神经网络(gnn)的出现,各个领域都取得了重大发展,吸引了众多关注。将图神经网络用于欺诈检测,构建图结构并从语义关系中提炼知识,是一种很有前景的方法。
4、然而,即使提取的图具有良好的语义邻接关系,将gnn应用于欺诈检测也并非没有挑战。gnn模型通常会聚合来自邻居的信息,这就会掩盖少数类节点的信息,进一步影响欺诈检测的效果,因此现有预测模型具备局限性。
技术实现思路
1、本发明的目的是克服现有技术中的不足,提供一种基于不平衡感知图神经网络的欺诈预测方法。
2、一种基于不平衡感知图神经网络的欺诈预测方法,包括以下步骤:
3、步骤1、欺诈数据集采集及预处理,得到预处理后的欺诈数据集;
4、步骤2、构建guardnet模型;
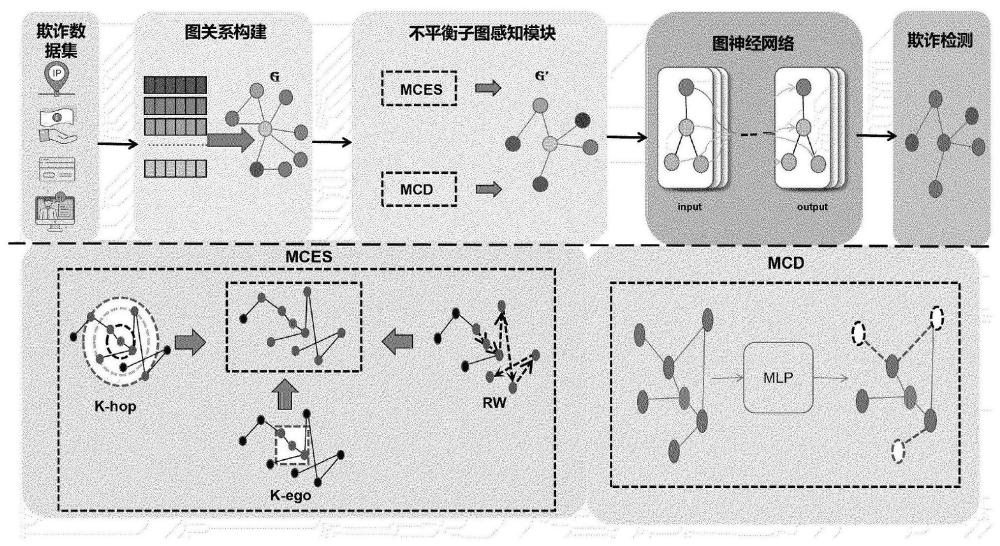
5、所述的guardnet模型包括依次连接的图构建模块、不平衡感知子图洗牌模块和欺诈预测模块;
6、所述的图构建模块包括依次连接的数据对齐层和一个全连接层;
7、所述的不平衡感知子图洗牌模块包括依次连接的以欺诈节点为中心探索的子图和以非欺诈节点为中心的下采样单元;
8、所述的欺诈检测模块包括依次连接的图神经网络和全连接层;
9、步骤3、利用预处理后的欺诈数据集对guardnet模型进行训练,将训练好的guardnet模型用于信用卡的交易记录、保险骗保申请、钓鱼网址、虚假招聘申请的欺诈检测,得到欺诈的检测结果。
10、对于来自不同领域的具有不同结构的数据集,guardnet构建考虑语义关系的图。然后,guardnet设计了一种不平衡感知的子图混洗方法来重构图,同时突出少数类节点的重要性,降低多数类节点的重要度。图神经网络编码器的使用有助于获取高级表示和随后的欺诈检测结果。在不同领域的七个欺诈检测数据集上进行的大量实验验证了guardnet的优越性和稳健性,它优于所有最先进的方法,分别将召回率、f1分数和几何均值提高了2.53%、2.45%和1.69%。
11、步骤1中,所述的欺诈数据包括欺诈交易数据、异常行为数据、恶意软件数据和恶意网址数据。
12、步骤1中,预处理包括:
13、1.1)数据清洗;
14、1.2)对于清洗后的数据属于数值类型的特征,进行归一化,将不同类型的数据转换为同一范围内的分数或度量;
15、1.3)对于清洗后的数据属于非数值类型的数据,采用onehot编码的方式转换为数值形式。
16、步骤2中,所述的子图包括依次连接的randomwalk生成子图层、k-hop生成子图层、k-ego生成子图层,所述的下采样单元包括依次连接的多层感知器模型和聚合子图模块。
17、所述的子图部署有以下算法:
18、vn+1~uniform(ng(vi))
19、l0:n0(v0)={v0}
20、
21、上式中,vn+1代表第n+1个节点,ng(vi)是节点vi的邻居集合,li是指第i个节点的邻居子图,uniform是均匀分布,指每个数值都有相等的概率被选择。
22、通过这种算法部署,欺诈节点被指定为目标节点。为了应对图数据中常见的类不平衡挑战,子图部署整合了三种邻居采样策略。这种多方面的策略可生成三个不同的子图g1,g2,g3,每个子图都包含与目标节点相关的多层次上下文信息。这种算法捕捉到了不同领域节点的丰富连接模式,因此大大提高了图神经网络在欺诈检测任务中的性能和通用性。将欺诈节点集中在子图中,不仅能放大其重要性,还能协调图中各种类型节点的重要性。这种对欺诈节点的战略性关注有效地优化了图神经网络在欺诈检测中的性能。
23、所述的下采样单元部署有以下算法:
24、
25、xv代表v节点的特征向量,γ代表被丢弃的概率,对于节点的操作将根据mlp分类的类别,被分类为"保留"的节点将保留在原始图g中,而被分类为"删除"的节点则会被从中删除,从而生成一个新的子图g4,挑选出与欺诈节点更相似的非欺诈节点,能使模型欺诈检测性能有所提升。
26、通过这种算法部署,我们可以保留非欺诈节点,同时按照规定的比率减少图中节点的数量,从而解决类不平衡问题。此外,这种方法还有助于在训练阶段将重点转移到欺诈节点上。最后将g1,g2,g3,g4合并,这样,模型就能更有效地从这些欺诈行为中学习,从而提高整体性能。
27、进一步优选,这种基于不平衡感知图神经网络的欺诈检测方法,包括以下步骤:
28、步骤1、各类欺诈数据采集及预处理;各类欺诈数据包括欺诈行为或个体的内部特征数据和标识是否为欺诈的分类标签;
29、步骤2、构建guardnet模型;guardnet模型包括图构建模块、不平衡感知子图洗牌模块和欺诈预测模块;图构建模块由数据对齐层和一个全连接层依次连接组成;不平衡感知子图洗牌模块由以少数类节点为中心探索的子图(mces)和以主要节点为中心的下采样(mcd)两部分构成,mces包括一个randomwalk生成子图层,k-hop生成子图层,k-ego生成子图层,mcd包括一个多层感知器(mlp)模型和一个聚合子图模块;欺诈检测模块由三个gcn层和一个全连接层依次连接组成;
30、步骤3、利用预处理后的多源异构城市数据对hdm-gnn模型进行训练,将训练好的hdm-gnn模型用于区域级犯罪风险预测,得到对应区域的犯罪风险预测值。
31、作为优选,步骤1中:
32、欺诈行为相关的特征数据是指与欺诈活动相关的各种信息,用于分析和识别潜在的欺诈行为。这类特征数据通常包括交易信息、账户信息、设备信息、地理信息以及用户行为数据等;
33、标签信息是在数据集中为每个样本或实例分配的标识符,用于指示该样本的类别或属性。在欺诈检测等应用中,标签信息通常用于标记每个交易或用户是否涉及欺诈行为。这些标可以是二元的,表示欺诈或非欺诈,也可以是多类别的,表示不同类型的欺诈行为。
34、作为优选,步骤1中对欺诈数据的预处理具体为:
35、首先数据清洗是数据预处理的第一步,主要是为了处理原始数据中存在的错误、缺失、重复、异常等问题。对于数值类型的特征,进行归一化,将不同类型的数据转换为同一范围内的分数或度量;对于非数值类型的数据,文本的分类数据采用onehot编码的方式转换为数值形式,对于诸如网址之类的文本通过bert将文本转化为数值向量来进行特征表示。
36、作为优选,4.步骤2中mces的randomwalk生成子图层,k-hop生成子图层,k-ego生成子图层邻居数k分别取10,2,3,mcd的mlp为2层,欺诈检测模块的gcn层输入和输出通道数均为1,使用sigmoid作为激活函数。
37、作为优选,步骤3具体包括以下步骤:
38、步骤3.1、将所有欺诈数据样本按设定比例划7:1:2分为训练集和测试集,
39、步骤3.2、将训练集用于训练guardnet模型;
40、将训练集中的欺诈数据作为guardnet模型的输入,利用guardnet模型输出的每个节点的欺诈预测标签和真实的欺诈标签,用bceloss误差作为损失函数来计算每次训练后的损失,bceloss损失函数的表达式如下:
41、
42、其中,是损失值,n是节点数,c是类数,yi,c是节点vi的真实标签,是节点vi的预测标签。采用sgd随机梯度下降策略对guardnet模型进行训练,每个样本进行前向计算和误差计算后,都对guardnet模型参数进行一次更新;
43、步骤3.3、用测试集验证guardnet模型的效果;
44、步骤3.4、将训练好的guardnet模型用于欺诈预测。
45、作为优选,步骤3.4具体包括以下步骤:
46、步骤3.4.1、我们的目标是将复杂的原始欺诈数据表示转换成图,对于有id的数据情况下,采取将每一个id作为一个单独的数据节点储存在图中,将欺诈行为相关的特征数据作为该节点的特征数据,将标签信息作为节点分类的标签,对于没有id的数据情况下,每一条的数据作为一个节点,将该条数据的欺诈行为相关的特征数据作为该节点的特征数据,将标签信息作为节点分类的标签;随后计算各节点之间的特征相似性,计算公式为:
47、
48、上式中,vi,vj表示图中的某一节点,对于vi,vj的计算表示对该节点节点特征的计算,sim(vi,vj)表示两个节点之间的节点相似性。最后根据节点各自特征的相似性建立节点之间的关系。当两个节点之间的相似度超过预定义的阈值时,就会在这两个节点之间建立连接或边,从而把原来的将复杂的原始欺诈数据表示转换成图g。
49、步骤3.4.2、基于3.4.1已构建的无向图g,我们重点关注少数类和多数类的邻居节点的抽样。
50、对于少数类节点,为了应对图数据中类不平衡,我们的方法整合了三种邻居采样策略:k-hop邻居、k-ego邻居和随机行走邻居。下面是k-hop邻居、k-ego邻居和随机行走邻居的公式:
51、vn+1~uniform(ng(vi))
52、l0:n0(v0)={v0}
53、
54、上式中其中,vn+1代表第n+1个节点,ng(vi)是节点vi的邻居集合,li是指第i个节点的邻居子图,uniform是均匀分布。
55、对于少数类节点分别取这三种邻居,这种多方面的策略产生了三个不同的子图g1,g2,g3;
56、对于多数类节点,我们将参数γ定义为下采样率。为了方便这一过程,我们采用了多层感知器(mlp)模型,将节点分为两组:保留和丢弃。丢弃类别会被分配一个与γ相对应的比率,这表示我们打算按照这个指定比率对多数类别的节点进行降采样,下面是mlp的相关公式:
57、
58、xv代表v节点的特征向量,对于节点的操作将根据mlp分类的类别,被分类为"保留"的节点将保留在原始图g中,而被分类为"删除"的节点则会被从中删除,从而生成一个新的子图g4;
59、步骤3.4.3、欺诈检测模块内,我们利用l层图卷积网络(gcn)来预测欺诈风险。欺诈风险。gcn的基本原理在于利用节点之间的关系信息来增强特征表示。通过学习节点之间的连接gcn可以捕捉图数据中的复杂关系,并有效地传播信息。
60、在gcn的训练阶段,来自不同节点的信息会在多个图卷积层之间进行系统性汇聚。这种循序渐进的方法有助于完善网络中的特征表示。这种逐层传递信息的顺序对gcn熟练掌握图数据至关重要,尤其是在处理具有固有层次结构的数据时,其定义如下:
61、
62、
63、
64、其中是节点vi在第l层的节点嵌入值。n(i)是节点vi的邻居集合,w(l)是第l层的可学习权重矩阵,σ是激活函数,v是节点特征矩阵,每列对应一个节点的特征向量。d代表度矩阵,a是邻接矩阵。最后输出节点的欺诈预测类别。
65、作为优选,步骤3.4.2中kego,khop,krw分别取3,2,10取得最好的效果
66、作为优选,步骤3.4.3中gcn取3层以取得最好效果。
67、本发明的有益效果是:
68、本发明能够充分利用各领域的欺诈数据,利用图神经网络研究欺诈检测问题,并考虑到固有语义关系来解决数据不平衡问题;本发明可以为欺诈检测任务提出了一个有效的基于gnn的框架guardnet。具体来说,我们首先构建以图为中心的用户作为节点,以语义关系作为边。然后,我们设计了一种不平衡感知子图洗牌方法来重新构建图,同时减轻数据不平衡问题,并通过分层融合组件来融合多个以少数类节点为中心的子图,以提高少数类节点的重要性;可以达到更好的预测效果。
本文地址:https://www.jishuxx.com/zhuanli/20240730/197479.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表