基于强化学习的含时间和角度约束的协同制导方法
- 国知局
- 2024-07-31 23:47:17
本发明属于强化学习制导,涉及一种基于强化学习的含时间和角度约束的协同制导方法。
背景技术:
1、当前基于强化学习的飞行器协同制导方法仍然存在一些挑战和不足之处。首先,飞行器协同制导本身是一个复杂的非线性问题,而纯粹的强化学习方法在应对这类问题时可能面临收敛缓慢、数据需求量大以及易陷入局部最优解的问题。飞行器协同制导过程中的时变性和对角度的精确要求增加了问题的难度,而传统强化学习可能需要大量的样本来学习复杂的非线性关系,这对于实际应用来说可能是不切实际的。其次,含有时间和角度约束的飞行器协同制导需要考虑更多的约束条件,这使得强化学习算法需要更高的灵活性和鲁棒性。当前的强化学习方法可能在处理复杂的时空约束时表现不佳,需要更加智能和高效的算法来应对这些挑战。
2、综上所述,虽然基于强化学习的飞行器协同制导方法在理论上提供了一种新的思路,但仍然需要克服一系列挑战,包括处理复杂非线性关系、提高算法的收敛速度、减少对大量样本的依赖,以及更好地适应含有时空约束的实际场景。这些问题的解决将为强化学习在飞行器协同制导领域的应用带来更多的实用性和可行性。
技术实现思路
1、要解决的技术问题
2、为了避免现有技术的不足之处,本发明提出一种基于强化学习的含时间和角度约束的协同制导方法,充分利用强化学习对模型依赖程度低,与环境交互学习策略的优势,同时为避免强化学习数据利用率低的问题,提高强化学习在求解制导问题时的收敛性和通用性,本发明提供了一种将比例导引和强化学习进行结合,实现训练常规ann神经网络来进行含时间约束的制导。
3、技术方案
4、一种基于强化学习的含时间和角度约束的协同制导方法,其特征在于步骤如下:
5、步骤1:建立地面坐标系下的导弹无推力三维质点动力学模型;
6、导弹的三维仿真模型代替导弹运动动力学模型,作为二维的无推力导弹运动动力学方程;
7、
8、其中,d为飞行器飞行过程中所受阻力,以阻力为速度的函数;m为飞行器质量,为弹道倾角,为飞行速度,ψ为弹道偏角,ay,az分别为飞行器在俯仰方向和偏航方向的加速度即攻击时间控制制导律;
9、步骤2:设计神经网络输入输出;
10、采用深度神经网络,以状态空间s作为神经网络的输入,即
11、s=[r,dr,q,θt-θ,tgo]
12、其中,r表示弹目距离,q为视线角,dr表示弹目距离步长间隔的变化大小,θt-θ表示落角约束与当前弹道倾角的差值,tgo表示飞行器在当前位置以比例系数进行比例导引法制导时击中目标所需的时间,即
13、
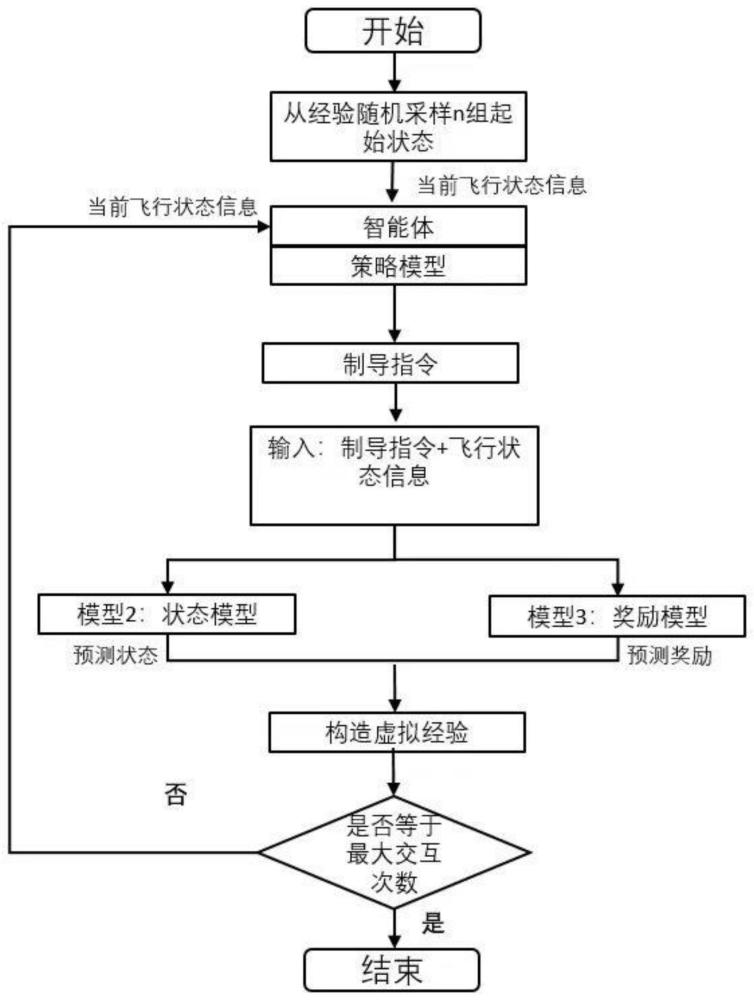
14、攻击时间控制制导律为:
15、
16、其中,ki>2,攻击时间误差的收敛速度取决于ki的大小,输出为动作k=[k1,k2]控制制导过程;n表示导航系数;λ为终端弹目视线角;对固定目标有λfy=θfy,λfz=θfz;
17、步骤3:设计奖励函数;
18、奖励函数起着对收集的经验评价的作用,是引导神经网络优化的关键,所述神经网络的奖励函数为:
19、
20、其中,θt-θ表示飞行器最终落角与期望落角的差值,作为飞行器成功击中目标时的最终奖励函数;dr表示每一步长飞行器与目标的相对距离在间隔步长的变化,作为飞行器在每一回合中单步长的奖励函数,引导飞行器击中目标;
21、步骤4:建立虚拟神经网络环境:
22、采用一般的神经网络形式,通过与环境交互,产生的新的数据用来训练环境模型,使得其与真实的环境更接近;该模型模拟动力学模,输入和输出与步骤1建立的模型一致,通过当前状态以及根据当前策略选择的行为预测下一步的状态;
23、设计交互环境;
24、算法执行时和真实环境与虚拟环境进行迭代交互,通过探索环境获得经验并储存经验,再利用经验去优化神经网络;交互过程为:根据当前状态st,得到动作at,并将at输入至制导率获得导弹的二轴过载,随后将过载代入导弹运动的动力学方程中,到达下一步状态st+1并获得奖励rt+1并组成经验;每回合迭代终止的条件有以下三种:
25、(1)达到最大迭代步数15000;
26、(2)与目标的距离小于容许误差,即命中目标;
27、(3)导弹坠毁;
28、步骤5:初始化算法超参数;执行强化学习算法,收集经验后训练神经网络;
29、神经网络由两部分组成,分别为价值神经网络和策略神经网络,神经网络的优化流程具体为:
30、步骤5-1:更新价值神经网络,价值函数表示为
31、
32、
33、q函数参数可以通过优化最小化与估计值的差来得到:
34、
35、梯度表示为
36、
37、mbpo用了两个网络来减轻策略更新步骤的正偏差,每次更新独立的对他们进行更新去优化,同时用二者中小的q值来对来作为td-error里的新q
38、步骤5-2:策略神经网络的优化目标函数:
39、
40、其中α是不断优化的温度参数,在上述目标函数中以温度参数作为熵的权重,该参数优化的目标函数为
41、
42、所述步骤1建立无推力导弹运动动力学方程时,导弹推力为0,则导弹在飞行过程中质量不变;忽略导弹传感器误差。
43、所述步骤2的比例系数取3-6。
44、所述策略神经网络的优化目标函数中,通过最大熵鼓励策略探索,为具有相近的q值的动作分配近乎均等的概率,不会给动作范围内任何一个动作分配非常高的概率,避免反复选择同一个动作而陷入次优;同时通过最大化奖赏,放弃明显没有前途的策略即放弃低奖赏策略:
45、
46、有益效果
47、本发明提出的一种基于强化学习的含时间和角度约束的协同制导方法,该发明通过将强化学习和比例导引方法结合,应用于协同制导问题中。当前基于强化学习的飞行器协同制导方法仍然存在一些挑战和不足之处。飞行器协同制导本身是一个复杂的非线性问题,而纯粹的强化学习方法在应对这类问题时可能面临收敛缓慢、数据需求量大以及易陷入局部最优解的问题。飞行器协同制导过程中的时变性和对角度的精确要求更增加了问题的难度,本发明结合比例导引增强制导精度,同时利用强化学习提升了在未知环境中自主决策的能力,可以解决未知环境中着陆制导问题。不仅可以满足满足终端落角约束,还可以满足时间协同,提升了算法稳定性。
48、本发明将比例制导方法和强化学习结合,针对复杂约束的含时间约束的制导问题,通过使用比例制导作为基本策略,提升了探索效率与算法收敛速度;利用强化学习输出比例系数,通过mbpo算法提升策略探索能力和数据利用效率,提升算法自适应能力。根据本发明的算法,可以得到神经网络形式策略,提升在线计算效率。
技术特征:1.一种基于强化学习的含时间和角度约束的协同制导方法,其特征在于步骤如下:
2.根据权利要求1所述基于强化学习的含时间和角度约束的协同制导方法,其特征在于:所述步骤1建立无推力导弹运动动力学方程时,导弹推力为0,则导弹在飞行过程中质量不变;忽略导弹传感器误差。
3.根据权利要求1所述基于强化学习的含时间和角度约束的协同制导方法,其特征在于:所述步骤2的比例系数取3-6。
4.根据权利要求1所述基于强化学习的含时间和角度约束的协同制导方法,其特征在于:所述策略神经网络的优化目标函数中,通过最大熵鼓励策略探索,为具有相近的q值的动作分配近乎均等的概率,不会给动作范围内任何一个动作分配非常高的概率,避免反复选择同一个动作而陷入次优;同时通过最大化奖赏,放弃明显没有前途的策略即放弃低奖赏策略:
技术总结本发明涉及一种基于强化学习的含时间和角度约束的协同制导方法,该发明通过将强化学习和比例导引方法结合,应用于协同制导问题中。当前基于强化学习的飞行器协同制导方法仍然存在一些挑战和不足之处。飞行器协同制导本身是一个复杂的非线性问题,而纯粹的强化学习方法在应对这类问题时可能面临收敛缓慢、数据需求量大以及易陷入局部最优解的问题。飞行器协同制导过程中的时变性和对角度的精确要求更增加了问题的难度,本发明结合比例导引增强制导精度,同时利用强化学习提升了在未知环境中自主决策的能力,可以解决未知环境中着陆制导问题。不仅可以满足满足终端落角约束,还可以满足时间协同,提升了算法稳定性。技术研发人员:泮斌峰,岳克圆,焦杰,吴文博,谭清杜,杨帅斌受保护的技术使用者:西北工业大学技术研发日:技术公布日:2024/6/20本文地址:https://www.jishuxx.com/zhuanli/20240730/198508.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。