一种基于深度强化学习的无人协同系统和运用方法与流程
- 国知局
- 2024-07-31 23:52:17
本发明涉及多无人机集群控制领域,具体涉及一种基于深度强化学习的无人协同系统和运用方法。
背景技术:
1、随着时代的发展,无人系统的智能决策能力变得至关重要。过去,无人系统主要依赖人为设定的脚本和直接操作,但这种方法在多变和复杂的环境中已经不再适应。智能决策的需求日益增长,它能够赋予系统更强的自适应性和灵活性,从而迅速响应即时变化。
2、传统的无人系统引入基于规则的方法和简易学习算法来提高无人机的操作智能,但这些方法在实际应用中的局限性明显,面对复杂环境的不确定性,这些方法经常不能提供有效的应对方案,难以覆盖所有潜在的变数。
3、部分系统开始采用集成单智能体强化学习算法来提升多无人机系统的决策质量。这类算法通过模拟环境交互,旨在增强每个智能体的独立决策能力。但这些算法在智能体的集体行动和协作效率上仍显不足。尤其在无人机协同这类高度依赖协调的任务中,这类算法难以有效整合智能体间的交互作用,导致资源配置不当和协同行动不同步,降低了作战效率,加剧了资源损耗。
4、因此,迫切需要一种新型的无人机协同系统和方法,它能够在复杂的环境中,通过高度智能化的学习算法,实现快速的决策制定和准确的策略执行,从而提升协同效果和单位的生存能力。
技术实现思路
1、发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种基于深度强化学习的无人协同系统和运用方法,包括创建一个模拟仿真环境;构造多无人机协同场景的状态空间、动作空间;设计群体利益奖励函数,以引导无人机有效协同,优化集体战术决策;设置智能体局部网络和混合网络的初始参数和网络结构,对决策模型训练,得到适应动态对抗环境的决策策略。
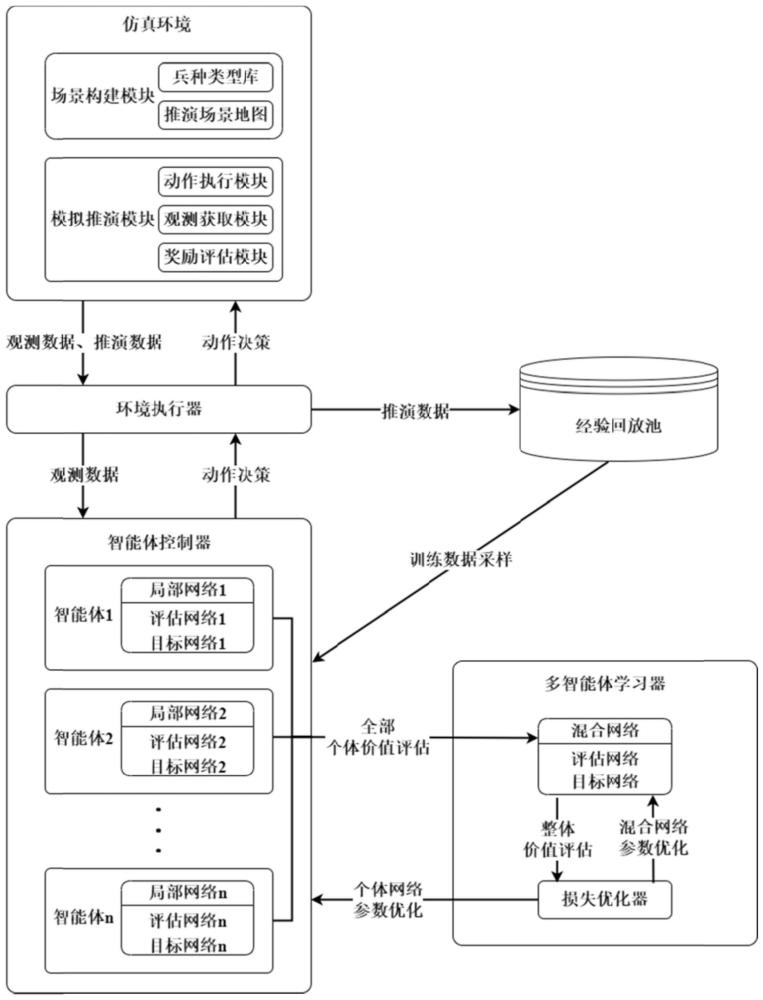
2、本发明提供了一种基于深度强化学习的无人协同系统,包括仿真环境模块、智能体控制器模块、环境执行器模块、经验回放池模块和多智能体学习器模块;
3、所述仿真环境模块负责构建和更新反映现实或假设条件的仿真环境,所述仿真环境模块模拟地面及空中单位的特性,为智能体控制器提供交互接口;此外,所述仿真环境模块允许用户根据具体需求和场景进行自定义地图和各个单位分布的调整,从而实现高度个性化的模拟和测试;
4、所述智能体控制器模块包括智能体评估局部网络和智能体目标局部网络,所述智能体评估局部网络负责处理环境的观测信息,并基于当前策略输出行动的价值估计;所述智能体目标局部网络对评估局部网络的输出进行目标值的设定,以引导策略向更优解的方向逐步逼近,从而实现行动决策的最优化;
5、所述环境执行器模块在仿真环境中实施智能体控制器产生的行动指令,同时,所述环境执行器模块记录指令执行结果和环境状态的变化;
6、所述经验回放池模块存储从环境执行器模块收集的数据,包括状态转换、所采取的行动以及对应的奖励信号,所述数据将被用于支持多智能体学习器模块的训练过程;
7、所述多智能体学习器模块应用深度强化学习算法对智能体控制器的策略进行迭代优化。
8、本发明还提供了一种基于深度强化学习的无人协同运用方法,包括:
9、步骤1:在仿真系统中从已有无人机库中实例化对应对象,构造无人机对抗模型;
10、步骤2:在仿真系统中根据无人机对抗模型设置相应推演规则和奖励;
11、步骤3:初始化我方各个无人机智能体控制器c(i)的参数θ(i)和智能体学习器l的参数θtot,i取值为1~n,n表示自然数;
12、步骤4:将仿真环境和无人机智能体控制器c(i)交由环境执行器e,根据仿真环境提供给的各个无人机智能体的当前t时刻观测和无人机智能体控制器中局部网络中评估网络的参数θ(i)所确定的策略让无人机智能体不断选取动作在环境执行器e中不断进行推演,直至推演到结束状态,得到一组与环境交互的样本数据di;
13、步骤5:将样本数据di加入到经验回放池p中;
14、步骤6:判断经验回放池p中样本数据量是否满足预设要求,如果不满足预设要求,重复步骤4~步骤5,否则执行步骤7;
15、步骤7:从经验回放池p中采集样本数据d′,读取相邻的两组时刻数据(dt,dt+1),交给各个无人机智能体控制器c(i),根据c(i)中的局部网络评估各个无人机智能体对t时刻各自观测下所选动作的价值组合得到全体局部价值评估qt;根据c(i)中的局部网络计算各个无人机智能体对t+1时刻各自观测下所选动作的价值评估组合得到全体局部价值评估qt+1;
16、步骤8:将全体局部价值评估qt和全局状态st输入到多智能体学习器m的混合网络leval(θtot)中评估t时刻下的整体价值
17、将全体局部价值评估qt+1和全局状态st+1输入到多智能体学习器m的混合网络ltar(θ*tot)中评估t+1时刻下的整体价值计算t时刻的回报参考值yt;
18、步骤9:重复步骤7~步骤8,直到将所述采集的样本数据d′全部处理,得到采集样本数据的全部的整体价值评估qm′;
19、步骤10:根据采集样本的全部整体评估qm′,计算相关损失项l;
20、步骤11:使用相关损失项l优化更新多智能体学习器m的混合网络中评估网络的参数θtot和各个无人机智能体控制器c(i)的局部网络中评估网络的参数θ(i);
21、步骤12:判断距离上次将多智能体学习器m和各个无人机智能体控制器c(i)中的评估网络参数更新到目标网络的时间间隔是否达到预设训练次数,如果达到,则将多智能体学习器m和各个无人机智能体控制器c(i)中的评估网络参数更新到各自的目标网络中;
22、步骤13:判断当前策略是否收敛,如果不收敛,重复步骤4~步骤12,否则执行步骤14;
23、步骤14:停止训练更新,将当前各个无人机智能体控制器c(i)的局部网络中评估网络的模型保存,得到适应当前场景的多个无人机智能体各自的决策模型。
24、步骤1中,所述无人机对抗模型中包括我方目标和敌方目标,所述我方目标包括战斗机、轰炸机、突击坦克、反导弹坦克,所述敌方目标包括防空导弹基地、指挥中心目标、火炮坦克车;在仿真系统中设置我方目标和敌方目标的位置、状态,初始化场景地图。
25、步骤2中,所述推演规则包括:在指定的最大时间步t内,突破敌方各类防御和攻击目标的掩护,摧毁指定的指挥中心目标。
26、步骤4中,所述样本数据中t时刻的数据为dt,dt包括全局状态st、各个无人机智能体在t时刻的观测ot、各个无人机智能体在t时刻选择的动作at、执行动作at后的奖励rt,公式为:
27、
28、dt=(st,ot,at,rt)
29、
30、
31、
32、其中,i表示从经验回放池中取出的样本序号,t取值为1~t,ki表示第i个样本数据推演到终止状态所用的实际时间步,取值为1~t,即任何样本最少1步推演至终止状态,最多t步推演至终止状态,但各个样本的推演步数可能有所不同,n表示无人机智能体个数,观测包括无人机单位的自身属性、视野范围下友军和敌军的相关属性、相对各个友军和敌军的距离;全局状态st包括全部友军和敌军单位的全部属性;表示第i个样本数据最终时刻即ki时刻的状态、观测、动作、奖励数据,表示第n个无人机智能体在t时刻的观测,表示第n个无人机智能体在t时刻的动作,动作对应无人机智能体所选取的移动、选定目标、攻击目标动作。
33、步骤7中,样本数据d′形式为:
34、d′=(d1,d2,…,db) (2)
35、其中,b表示一批量的样本数量,db表示第b个样本从开始状态到结束状态所有时刻的数据。
36、步骤7中,所述全体局部价值评估qt计算公式为:
37、
38、步骤8中,采用如下公式计算t时刻的回报参考值yt:
39、
40、其中γ表示衰减因子。
41、步骤9中,采用如下公式计算采集的第i个样本数据的全部的整体价值评估qi′:
42、
43、其中i表示样本序号,t表示第i个样本的第t个时间步,yi,t表示第i个样本中t时刻的回报参考值,t的取值范围为1~ki,表示第i个样本中t时刻的整体价值评估。
44、步骤10中,采用如下公式计算相关损失项l:
45、
46、在强化学习中,评估网络和目标网络是已经存在的技术概念,它们通常用于提高训练效率和稳定性。评估网络用于估计当前策略的价值或动作的潜在价值,而目标网络则用于稳定训练过程,减少价值函数的波动性。通常每隔一段时间用当前的评估网络去更新目标网络,以达到稳定训练、避免过度拟合的目的。
47、在多智能体强化学习中,局部网络和混合网络也是已有的技术概念,是属于集中式训练分布式学习(centralized training with decentralized execution,ctde)方法中的重要组成部分。局部网络指的是每个智能体所拥有的个体网络,用于处理其所观察到的局部环境信息并作出决策。混合网络则是将多个智能体的局部网络结合起来,以实现协同决策或信息共享。
48、有益效果:采用本发明提出的基于深度强化学习的无人机协同系统与方法,由于采用了上述方案,具有以下优点:
49、1、本发明可以根据实际需求和特定目标,定制和构建相应的具体场景,模拟无人机对抗。这种场景构建具有灵活性和适应性,可以模拟各种复杂条件和敌我配置。
50、2、本发明可以基于仿真协同系统快速进行大量模拟训练,这使得无人机协同系统得以在各种设定条件下不断学习和优化作战策略。通过这种高效率的迭代学习过程,系统能够在短时间内对大量可能的场景进行深入分析,从而迅速提升决策的质量和效率。此外,模拟训练可以大幅减少实际演习的成本和资源消耗,同时降低训练过程中的风险。
51、3、本发明利用了深度强化学习的算法,平衡了无人机协作时的个体利益和集体利益。通过集中式训练与分布式执行的结构,单个无人机能够根据全局信息和自身观察来优化个体行动,同时促进全体协同作战,以达成整体作战目标。这样的算法设计不仅提高了单个无人机的策略执行能力,也加强了无人机群体间的配合和效率,显著提升了对抗操作的整体性能。
本文地址:https://www.jishuxx.com/zhuanli/20240730/198912.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表