水面无人艇航迹跟踪控制参数匹配方法
- 国知局
- 2024-07-31 23:56:44
本发明属于无人艇航迹跟踪控制领域,具体涉及一种基于软更新算法的无人艇航迹跟踪控制参数匹配方法。
背景技术:
1、在无人艇航迹跟踪领域pid控制相比于其他的控制应用范围广,调参较容易,但pid控制参数整定较复杂,传统pid控制器的控制参数无法随无人艇航行状态变化自适应调整,且固定参数的pid控制器存在控制精度差和超调量大等问题,导致无人艇在航迹跟踪时抗干扰性差。
技术实现思路
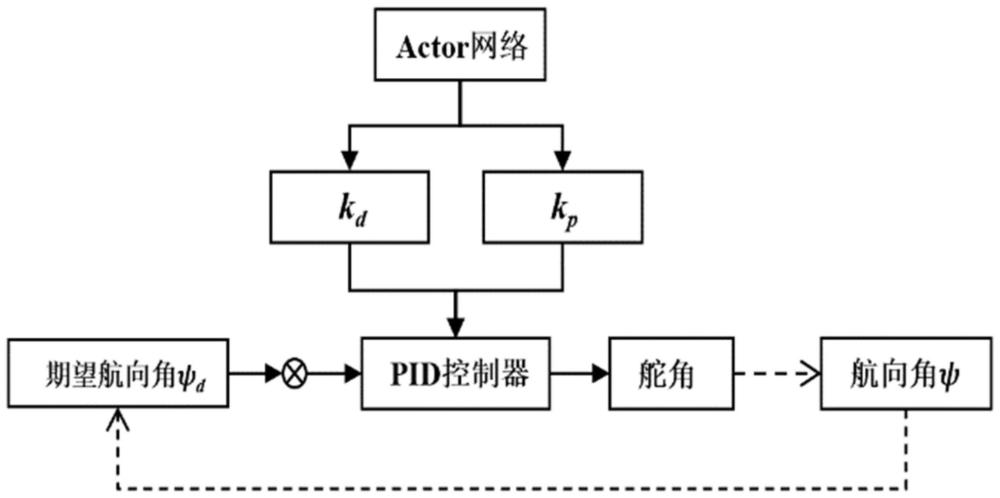
1、本发明的目的在于提供一种水面无人艇航迹跟踪控制参数匹配的方法,它采用深度强化学习算法训练出pid或pd参数匹配器,然后将输出的pid或pd参数作为水面无人艇航迹跟踪pid或pd控制器的输入,解决了控制参数随水面无人艇航行变化自适应调整的问题,同时提高了控制的鲁棒性,即在干扰情况下仍可快速视线轨迹跟踪。本发明提出的方法以神经网络逼近的形式替代数学推导,并且由程序自动训练参数匹配器,不需要人工干预。
2、根据实施例的第一方面,提供一种水面无人艇航迹跟踪控制参数匹配方法,该方法是采用深度强化学习训练出的智能体输出pid或pd参数作为无人艇航迹跟踪pid或pd控制器的输入,智能体的观测状态s为:其中u为无人艇x轴速度、v为y轴速度、r为角速度、为航向角、ye为无人艇与目标航线横向距离、αk为目标航线的倾斜角度,epsi为航向角目标航线倾角的偏差为,d为舵角,为舵角的导数,为航向角偏差的导数,kp,kd分别为pid或pd参数;智能体动作a为pd参数[kp,kd]。
3、采用actor-critic模型训练智能体,其方法包括:
4、初始化actor网络和critic网络参数:迭代次数epoch,每次迭代最大步数steps,软更新参数τ,网络学习率,衰减因子γ,熵值系数α,并将网络参数赋值给target actor和target critic;
5、初始化经验池r;
6、获得第t步观测状态st:
7、actor网络输入为状态st,输出为动作at,智能体执行动作后与环境交互得到奖励rt和下一步的状态st+1,将(st,at,rt,st+1,done)存入经验池r,done代表任务是否完成,取值为0或1,然后根据done的值将经验池划分为失败经验池和成功经验池;
8、当本次训练达到最大执行步steps,分别从失败经验池和成功经验池中随机抽取[σ*batch_size」条的样本,智能体开始学习,其中σ为自适应采样批次函数输出值,batch_size为初始设置样本数据数量;
9、将状态st,动作at输入到critic网络,得到当前状态-动作价值q,将下一状态st+1输入到tatget-actor网络中得到下一动作at+1,同样将st+1,at+1输入到target-critic网络得到状态-动作价值q’,并梯度下降更新critic网络:
10、拿从经验池中采出的数据(st,at,rt,st+1,done)进行actor网络的更新:
11、更新target-actor和target-critic网络:
12、保存训练参数。
13、根据实施例的第二方面,提供一种无人艇,包括:处理器,其被配置为利用所述的水面无人艇航迹跟踪控制参数匹配方法来控制无人艇。
14、根据实施例的第三方面,提供一种存储介质,用于存储非暂时性指令,当所述非暂时性指令由处理器执行时能够实现所述的水面无人艇航迹跟踪控制参数匹配方法。
技术特征:1.一种水面无人艇航迹跟踪控制参数匹配方法,其特征在于,该方法是采用深度强化学习训练出的智能体输出pid或pd参数作为无人艇航迹跟踪pid或pd控制器的输入,
2.根据权利要求1所述的方法,其特征在于,深度强化学习框架为:
3.根据权利要求1所述的方法,其特征在于,采用actor-critic模型训练智能体,其方法包括:
4.根据权利要求3所述的方法,其特征在于,奖励值包括:角度误差奖励rpsi和横向距离奖励
5.根据权利要求3所述的方法,其特征在于,自适应采样批次函数σ:
6.根据权利要求3所述的方法,其特征在于,随着经验池内经验条数量的增加,采样批次大小逐渐增加直至2倍的初始设定采样批次。
7.一种无人艇,其特征在于,包括:处理器,其被配置为利用权利要求1-5任一项所述的水面无人艇航迹跟踪控制参数匹配方法来控制无人艇。
8.一种存储介质,用于存储非暂时性指令,其特征在于,当所述非暂时性指令由处理器执行时能够实现权利要求1-5任一项所述的水面无人艇航迹跟踪控制参数匹配方法。
技术总结本发明属于无人艇路径跟踪领域,公开了一种水面无人艇航迹跟踪控制参数匹配方法,该方法采用改进DDPG算法对PID或PD参数进行合理的预测,让无人艇“学会”根据当前的状态动态地调整PID参数。方法包括:S1,搭建无人艇运动仿真模型,定义无人艇运动参数;S2,设计深度强化学习与视线法结合的框架;S3,设计基于深度强化学习基本框架对PID进行预测,拟采用单层全连接神经网络作为改进DDPG四个网络的基本结构;S4,对步骤S3中设计好的模型进行训练并保存训练参数。本发明的方法使得无人艇在干扰情况下获得更高精度、更快速的航迹跟踪。技术研发人员:宋利飞,郝乐,许传毅,孙昊,史晓骞,徐凯凯受保护的技术使用者:武汉理工大学技术研发日:技术公布日:2024/6/30本文地址:https://www.jishuxx.com/zhuanli/20240730/199319.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表