一种基于PPO改进算法的路径规划方法及系统与流程
- 国知局
- 2024-07-31 23:56:41
本发明属于机器人路径规划,具体涉及一种基于ppo改进算法的路径规划方法及系统。
背景技术:
1、在未知环境中,无人车运行须躲避任意形状的静态和动态障碍物,为提高无人车的智能性控制算法须考虑一系列环境状态。基于规则的方法需要人工经验编程,并且很难应对其它突发情况,因此有必要提出一种更加智能的算法来解决。
2、随着强化学习的发展越来越多的研究者将其应用在无人车控制中。强化学习的目的是通过与环境的交互学习最优的行为。与传统的机器学习相比,强化学习有以下优势第一,由于不需要样本标注过程它能更有效地解决环境中存在的特殊情况;第二可把整个系统作为一个整体,从而使其中的一些模块更加鲁棒。
3、但是由于强化学习需要智能体与环境交互后得到奖励反馈后去调整其动作,这个过程十分耗时,尤其是再学习初期,智能体需要不断地随机产生动作,进而来选择价值高的动作。
技术实现思路
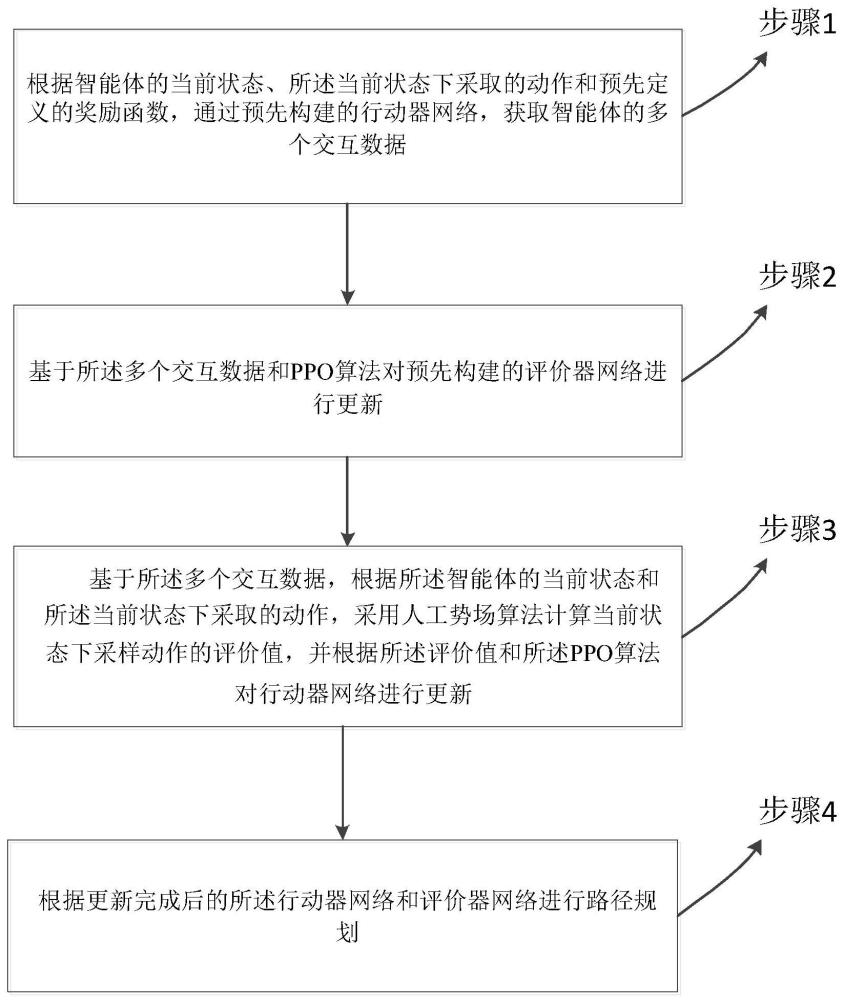
1、为克服上述现有技术的不足,本发明提出一种基于ppo改进算法的路径规划方法,包括:
2、根据智能体的当前状态、所述当前状态下采取的动作和预先定义的奖励函数,通过预先构建的行动器网络,获取智能体的多个交互数据;
3、基于所述多个交互数据和ppo算法对预先构建的评价器网络进行更新;
4、基于所述多个交互数据,根据所述智能体的当前状态和所述当前状态下采取的动作,采用人工势场算法计算当前状态下采取动作的评价值,并根据所述评价值和所述ppo算法对行动器网络进行更新;
5、根据更新完成后的所述行动器网络和评价器网络进行路径规划;
6、其中,所述评价器网络是基于深度神经网络并以智能体的当前状态为输入,以智能体的当前状态的价值为输进行构建的;
7、所述行动器网络是基于深度神经网络并以智能体的当前状态为输入,以智能体的下一步的动作为输出进行构建的。
8、优选的,所述根据智能体的当前状态、所述当前状态下采取的动作和预先定义的奖励函数,通过预先构建的行动器网络,获取智能体的多个交互数据,包括:
9、根据智能体的当前状态、所述当前状态下采取的动作和预先定义的奖励函数,在一个预设周期通过预先构建的行动器网络控制智能体按照多个预设时间步和环境进行数据交互,得到所述智能体在多个预设时间步长分别对应的交互数据;
10、并将所述智能体的多个交互数据在所述行动器网络的经验池中进行存储;
11、其中,所述交互数据包括:当前时间步对应的智能体的当前状态,所述当前状态下采取的动作和所述当前状态下采取的动作后得到的奖励。
12、优选的,所述基于所述多个交互数据和ppo算法对预先构建的评价器网络进行更新,包括:
13、基于所述智能体的多个交互数据,按照预设批次数目对所述智能体的多个交互数据进行筛选,获取预设批次的交互数据;
14、根据所述预设批次的交互数据,通过评价器网络损失函数计算所述评价器网络的损失值;
15、通过所述损失值对所述评价器网络的网络参数进行求导,并根据评价器网络的学习率获取评价器目标权重值;
16、将所述评价器目标权重值与所述评价器网络的初始权重值进行相加,获取评价器网络新的权重值;
17、通过所述评价器网络新的权重值,通过ppo算法对评价器网络进行更新。
18、优选的,所述评价器网络的损失值的计算式如下:
19、
20、其中,j(φ)表示评价器网络损失函数;lossj(φ)表示评价器网络的损失值;γ表示折扣系数;t表示时间步;t′表示时间步t之后的时间步;r表示预设批次的交互数据中通过奖励函数得到的奖励;t预设批次数目的交互数据;∑t′>tγ(t′-t)rt′表示按时间衰减累加的奖励和,vφ(st)为评价器对状态st的评价。
21、优选的,所述根据所述评价值和所述ppo算法对行动器网络进行更新,包括:
22、根据所述评价值、ppo算法和行动器网络损失函数,计算所述行动器网络的损失值;
23、通过所述损失值对所述行动器网络的网络参数进行求导,并根据行动器网络的学习率获取行动器目标权重值;
24、将所述行动器目标权重值与所述行动器网络的初始权重值进行相加,获取行动器网络新的权重值;
25、通过所述行动器网络的损失值,计算所述行动器网络新的权重值,根据所述行动器网络新的权重值对行动器网络进行更新。
26、优选的,所述行动器网络的损失值得计算式如下:
27、
28、其中,j(θ)表示行动器网络损失函数;lossj(θ)表示行动器网络的损失值;t表示时间步;表示优势函数;β表示调节因子;πθ表示新策略;πold表示旧策略;st是当前时间步t智能体的当前状态,at是智能体在当前状态st下采取的动作,rt是智能体在当前状态st下采取动作后得到的奖励;πθ(at|st)表示新策略πθ分布下智能体在当前状态st下采取的动作的概率;πold(at|st)表示旧策略πold分布下智能体在当前状态st下采取的动作的概率;为新旧策略分布下动作的概率比;ε表示固定参数;clip表示将概率比限制在1-ε,1+ε之间;qapf(st,at)表示人工势场评价器网络在是智能体在当前状态st下采取的动作at的评价;
29、其中,所述优势函数的计算式如下:
30、
31、上式中,t表示时间步;t′表示时间步t之后的时间步;r表示预设批次的交互数据中通过奖励函数得到的奖励;γ表示折扣系数;∑t′>tγ(t′-t)rt′表示按时间衰减累加的奖励和,vφ(st)为评价器对状态st的评价。
32、优选的,所述基于所述多个交互数据,根据所述智能体的当前状态和所述当前状态下采取的动作,采用人工势场算法计算当前状态下采取动作的评价值,包括:
33、基于所述多个交互数据,根据所述智能体的当前状态,计算当前状态下预设目标点的引力场和避撞斥力场;
34、并根据所述引力场和避撞斥力场,计算叠加势场,并将所述叠加势场作为人工势场;
35、通过所述人工势场的负梯度,获取智能体和预设目标点之间的合力;
36、通过所述合力和和所述当前状态下采取的动作计算均方差损失,并将所述均方差损失作为所述当前状态下智能体采取的动作的评价值。
37、基于同一发明构思,本发明还提供一种基于ppo改进算法的路径规划系统,包括:
38、数据获取模块,用于根据智能体的当前状态、所述当前状态下采取的动作和预先定义的奖励函数,通过预先构建的行动器网络,获取智能体的多个交互数据;
39、评价器网络更新模块,用于基于所述多个交互数据和ppo算法对预先构建的评价器网络进行更新;
40、行动器网络更新模块,用于基于所述多个交互数据,根据所述智能体的当前状态和所述当前状态下采取的动作,采用人工势场算法计算当前状态下采取动作的评价值,并根据所述评价值和所述ppo算法对行动器网络进行更新;
41、路径规划模块,用于根据更新完成后的所述行动器网络和评价器网络进行路径规划;
42、其中,所述评价器网络是基于深度神经网络并以智能体的当前状态为输入,以智能体的当前状态的价值为输进行构建的;
43、所述行动器网络是基于深度神经网络并以智能体的当前状态为输入,以智能体的下一步的动作为输出进行构建的。
44、优选的,所述数据获取模块具体用于:
45、根据智能体的当前状态、所述当前状态下采取的动作和预先定义的奖励函数,在一个预设周期通过预先构建的行动器网络控制智能体按照多个预设时间步和环境进行数据交互,得到所述智能体在多个预设时间步长分别对应的交互数据;
46、并将所述智能体的多个交互数据在所述行动器网络的经验池中进行存储;
47、其中,所述交互数据包括:当前时间步对应的智能体的当前状态,所述当前状态下采取的动作和所述当前状态下采取的动作后得到的奖励。
48、优选的,所述评价器网络更新模块具体用于:
49、基于所述智能体的多个交互数据,按照预设批次数目对所述智能体的多个交互数据进行筛选,获取预设批次的交互数据;
50、根据所述预设批次的交互数据,通过评价器网络损失函数计算所述评价器网络的损失值;
51、通过所述损失值对所述评价器网络的网络参数进行求导,并根据评价器网络的学习率获取评价器目标权重值;
52、将所述评价器目标权重值与所述评价器网络的初始权重值进行相加,获取评价器网络新的权重值;
53、通过所述评价器网络新的权重值,通过ppo算法对评价器网络进行更新。
54、优选的,所述评价器网络的损失值的计算式如下:
55、
56、其中,j(φ)表示评价器网络损失函数;lossj(φ)表示评价器网络的损失值;γ表示折扣系数;t表示时间步;t′表示时间步t之后的时间步;r表示预设批次的交互数据中通过奖励函数得到的奖励;t预设批次数目的交互数据;∑t′>tγ(t′-t)rt′表示按时间衰减累加的奖励和,vφ(st)为评价器对状态st的评价。
57、优选的,所述行动器网络更新模块中根据所述评价值和所述ppo算法对行动器网络进行更新,包括:
58、根据所述评价值、ppo算法和行动器网络损失函数,计算所述行动器网络的损失值;
59、通过所述损失值对所述行动器网络的网络参数进行求导,并根据行动器网络的学习率获取行动器目标权重值;
60、将所述行动器目标权重值与所述行动器网络的初始权重值进行相加,获取行动器网络新的权重值;
61、通过所述行动器网络的损失值,计算所述行动器网络新的权重值,根据所述行动器网络新的权重值对行动器网络进行更新。
62、优选的,所述行动器网络的损失值得计算式如下:
63、
64、其中,j(θ)表示行动器网络损失函数;lossj(θ)表示行动器网络的损失值;t表示时间步;表示优势函数;β表示调节因子;πθ表示新策略;πold表示旧策略;st是当前时间步t智能体的当前状态,at是智能体在当前状态st下采取的动作,rt是智能体在当前状态st下采取动作后得到的奖励;πθ(at|st)表示新策略πθ分布下智能体在当前状态st下采取的动作的概率;πold(at|st)表示旧策略πold分布下智能体在当前状态st下采取的动作的概率;为新旧策略分布下动作的概率比;ε表示固定参数;clip表示将概率比限制在1-ε,1+ε之间;qapf(st,at)表示人工势场评价器网络在是智能体在当前状态st下采取的动作at的评价;
65、其中,所述优势函数的计算式如下:
66、
67、上式中,t表示时间步;t′表示时间步t之后的时间步;r表示预设批次的交互数据中通过奖励函数得到的奖励;γ表示折扣系数;∑t′>tγ(t′-t)rt′表示按时间衰减累加的奖励和,vφ(st)为评价器对状态st的评价。
68、优选的,所述行动器网络更新模块中基于所述多个交互数据,根据所述智能体的当前状态和所述当前状态下采取的动作,采用人工势场算法计算当前状态下采取动作的评价值,包括:
69、基于所述多个交互数据,根据所述智能体的当前状态,计算当前状态下预设目标点的引力场和避撞斥力场;
70、并根据所述引力场和避撞斥力场,计算叠加势场,并将所述叠加势场作为人工势场;
71、通过所述人工势场的负梯度,获取智能体和预设目标点之间的合力;
72、通过所述合力和和所述当前状态下采取的动作计算均方差损失,并将所述均方差损失作为所述当前状态下智能体采取的动作的评价值。
73、与最接近的现有技术相比,本发明具有的有益效果如下:
74、本发明提供一种基于ppo改进算法的路径规划方法及系统,包括:根据智能体的当前状态、所述当前状态下采取的动作和预先定义的奖励函数,通过预先构建的行动器网络,获取智能体的多个交互数据;基于所述多个交互数据和ppo算法对预先构建的评价器网络进行更新;基于所述多个交互数据,根据所述智能体的当前状态和所述当前状态下采取的动作,采用人工势场算法计算当前状态下采取动作的评价值,并根据所述评价值和所述ppo算法对行动器网络进行更新;根据更新完成后的所述行动器网络和评价器网络进行路径规划;其中,所述评价器网络是基于深度神经网络并以智能体的当前状态为输入,以智能体的当前状态的价值为输进行构建的;所述行动器网络是基于深度神经网络并以智能体的当前状态为输入,以智能体的下一步的动作为输出进行构建的。通过人工势场计算当前状态下智能体和目标点之间的吸引力与排斥力的合力,然后根据合力计算智能体在当前状态下采取动作的评价值,根据所述评价值评价当前状态智能体采取动作的好坏程度来指导ppo中行动器网络的更新,然后进行路径规划,从而可以解决强化学习前期数据不足的问题,而强化学习解决了规划难以处理不确定环境的问题,在智能体路径规划问题上收敛速度更快,鲁棒性强。
本文地址:https://www.jishuxx.com/zhuanli/20240730/199312.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。