基于强化学习与事件触发的离散非线性系统混合容错协调跟踪控制方法
- 国知局
- 2024-07-31 23:56:31
本发明属于控制学习领域,涉及基于强化学习与事件触发的离散非线性系统混合容错协调跟踪控制方法。
背景技术:
1、在实际的多智能体控制系统中,受限于执行器物理局限性,控制器的输出没办法完全执行施加到对象,执行器饱和发生时,它会导致系统性能下降,系统的吞吐量降低,甚至会导致系统崩溃,并且执行器往往受使用时间的推移慢慢的会损失一些精度甚至产生故障,因此针对执行器输入进行饱和限制以及对执行器故障进行建模分析,在控制器的设计过程中进行考虑以上因素,使得整个系统具有一定容错性,更好的贴近真实的运用场景极具实际应用前景。且在当前的研究中,大都是针对连续系统进行分析和处理,由于离散高阶系统在处理过程中由于很多理论和方法不能直接使用,相对于连续系统来说更加复杂,但是事实上在实际控制系统环路中离散情况居多,比如测量系统状态、计算和发布控制信号等过程,因此采用离散系统模型更合理也更方便。离散系统具备很多连续系统没有的优势,由于当前执行器的智能化发展,允许控制分级以及多路控制,离散系统在针对惯性大且相应慢的系统只需要通过周期的断开输出,便可以较小系统振荡,随者算法硬件化,离散系统在高速控制方面也同样具备连续系统所不具备的优势。同时在实现过程中,很多算法都在较为理想的情况下进行控制器的设计与考虑,对一些具备工程实际意义的因素欠缺考虑,例如本算法提出的针对执行器饱和与故障的混合故障的处理。同时目前很多算法都是基于智能体的实际模型建立的,考虑到实际情况中大多场景系统的模型是很难去用数学模型建立的,本算法基于评价-执行的强化学习框架,建立对系统跟踪过程中的评价指标,并且贯穿整个控制器设计过程,利用神经网络逼近系统模型未知动态,做到无需实际系统的数学模型而进行最优自适应控制。针对当前控制算法的时间触发,通过设计合适的事件触发机制可以有效的节省网络资源,降低通信成本,同时本算法中引入的事件触发补偿机制可以进一步的减少触发频率,更加有效的节省通信带宽以及资源。
技术实现思路
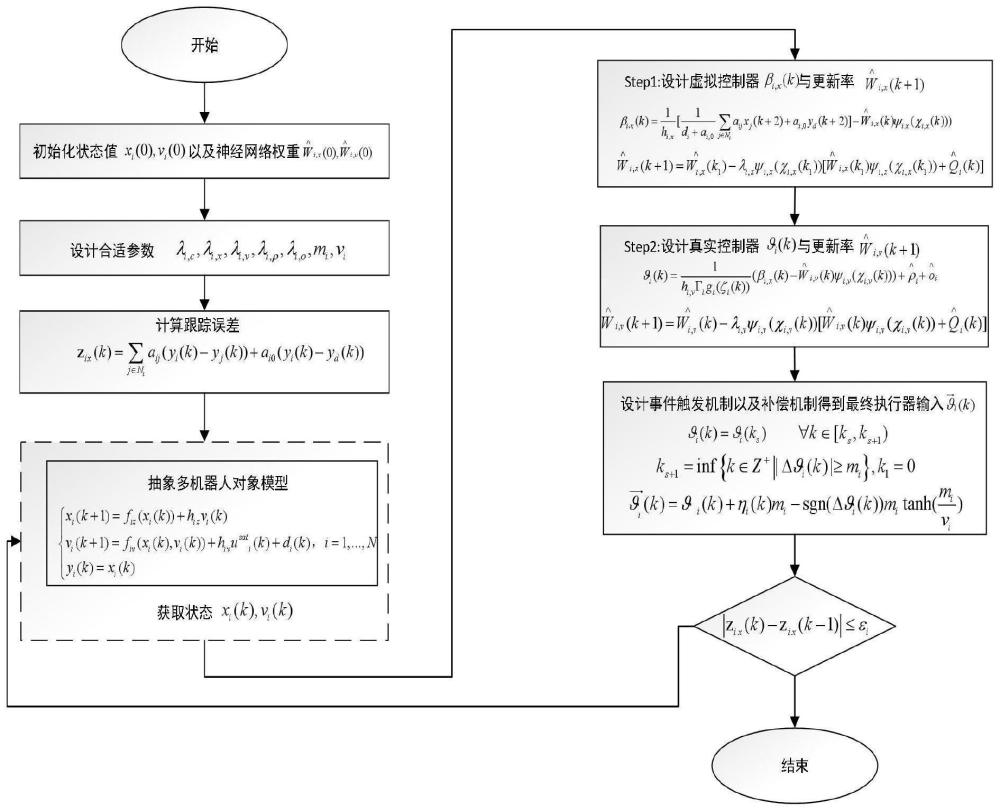
1、有鉴于此,本发明的目的在于提供基于强化学习与事件触发的离散非线性系统混合容错协调跟踪控制方法。针对当前实际多智能体控制系统中大都是连续系统的控制算法,并且大都是一阶非线性系统,很少考虑到离散下的高阶多智能体系统,且目前考虑的大都是单一的输入约束少有考虑执行器混合故障,同时很多算法需要依赖于实际系统精准的数学模型,在节省资源的事件触发机制中,很少有考虑在触发后到下一次触发前这段时间对系统带来的误差对系统稳定性和性能带来的不利影响。因此本发明为了降低对系统具体模型的依赖,并且能够处理具有执行器饱和与执行器故障的高阶不确定非线性严反馈多智能体系统,提出了一种针对执行器饱和与故障的高阶多智能体系统的容错跟踪算法。算法基于评价-执行强化学习框架,建立对系统跟踪过程中的长期评价指标,并且贯穿整个控制器设计过程,利用神经网络逼近系统模型未知动态,采用变换系统来处理离散高阶系统反步法设计过程中引入的“因果矛盾”问题,引入事件触发补偿项来进一步降低触发期间对系统的影响并且进一步减少触发频率节省网络通信资源,最终选取合适整个系统的李雅普诺夫函数,利用李雅普诺夫稳定理论证明所设计得到的控制器以及设计的参数自适应更新率能使系统稳定并最终达到与领导者的状态一致。
2、为达到上述目的,本发明提供如下技术方案:
3、基于强化学习与事件触发的离散非线性系统混合容错协调跟踪控制方法,该方法包括以下步骤:
4、s1:问题描述;
5、s2:事件触发函数设计;
6、s3:基于神经网络的评价性能函数设计;
7、s4:自适应分布式控制器设计;
8、所述s1具体为:考虑一类由n个跟随机器人一个领导者机器人构成的多移动机器人系统,每个跟随者机器人的动态模型用以下离散严格反馈非线性系统描述:
9、
10、其中ui(k)∈r和yi(k)∈r分别表示第i个跟随者控制输入和输出;f(·)∈rn为未知的内部状态性能函数;hix,hiv∈r为输入函数并有为正常数,其中fi,x,fi,v未知,hi已知;rn表示n维实欧式空间,rn×m表示n×m维实数矩阵集合,di(k)为未知干扰;多个机器人所构成的通信拓扑中需有一棵有向生成树;每个机器人获取各自邻居节点信息及自身信息,在事件触发的控制作用下,完成对领导者的一致性跟踪任务;定义每个机器人的跟踪误差ei1(k)=yi(k)-yd(k),yd(k)是领导者的状态,每个跟随者的局部一致跟踪误差zix(k)定义为:
11、
12、当第i个跟随者直接收到领导者信息时,ai0>0,否则ai0=0;当每个机器人跟踪上领导者且达到局部一致的时候,即(1.3)成立:
13、
14、同时考虑执行器饱和以及故障的混合容错控制问题,对执行器输入进行如下约束:
15、
16、其中θfi是执行器的输入,对其进行限制,和ui分别是控制器输入的上界和下界,同时考虑执行器存在以下故障:
17、θfi(k)=γiθi(k)+bi(k)θfi(k) (1.5)
18、其中θfi,θfi(k)分别是每个机器人执行器的控制信号和误差信号,其中0<γi≤1,且bi是误差信号系数,考虑如下四种情况:
19、(1)当γi=1,bi=0时,即执行器正常工作,即无故障情况;
20、(2)当0<γi<1,bi=0时,即执行器存在部分故障问题;
21、(3)当0<γi<1,bi=1时,即执行器存在偏执故障问题;
22、(4)当γi=0,bi=1时,即执行器完全无法正常工作;
23、采用向前一步预测器的方式来设计控制器:根据(1.1)有:
24、xi(k+1)=fix(xi(k))+hixvi(k):=ψ1(xi(k),vi(k)) (1.6)
25、向前预测一步则为:
26、xi(k+2)=fix(xi(k+1))+hixvi(k+1):=ψ1(xi(k),vi(k),vi(k+1)) (1.7)
27、(1.7)写为:
28、xi(k+2)=fix(xi(k),vi(k))+hixvi(k+1) (1.8)
29、其中fix(xi(k),vi(k))是一个非线性未知函数,利用神经网络的万能逼近性值,在后续的控制器设计中采用神经网络对其进行逼近;
30、结合前面的分析,得到向前一步预测系统模型,(1.1)写为:
31、
32、所述s2具体为:
33、设计带补偿的事件触发策略,定义误差函数:
34、δθi(k)=θti(k)-θi(k)=θi(ks)-θi(k),ks≤k<ks+1 (2.1)
35、其中θti(k)=θi(ks)代表上一触发时刻的控制信号,θi(k)代表当前时刻的控制信号,ks代表触发时刻且ks∈n,则触发机制条件写为:
36、
37、ks+1=inf{k∈z+||δθi(k)|≥mi},k1=0 (2.3)
38、其中mi>0是待设计的参数,则更新此时的控制器输入,根据触发策略设计,即存在一个时变参数|ηi(k)|≤1使得:
39、θti(k)=θi(k)+ηi(k)mi,k∈(ks,ks+1) (2.4)
40、在执行器中设计一个补偿项,实际执行器的输入为:
41、
42、其中是补偿项,这里设计补偿项为如下形式:
43、
44、其中vi是待设计的一个正常数,则最终执行器的输入为:
45、
46、定义补偿项:
47、
48、本发明的有益效果在于:
49、(1)本发明设计算法针对执行器饱和以及执行器故障的非线性高阶严反馈多智能体系统,对实际控制系统中的系统部件的物理局限性以及执行器长期使用下产生的精度遗失问题具有很好的自适应控制能力。
50、(2)本发明针对离散高阶系统反步法设计过程中可能出现的“因果矛盾”问题,采用变换系统的方式进行有效避免,完成了控制算法从连续系统到离散系统的推广,使其更接近实际控制情形的真实系统。
51、(3)本发明引入了评价-执行的强化学习框架,根据跟踪误差来建立合适的评价指标,并贯穿在反步法所设计的虚拟控制器和真实控制器中,使得控制器能更快收敛于最优且达到状态一致性。
52、(4)本发明利用神经网络的万能逼近性来近似多智能体系统的模型,从而进行控制器的设计,消除了对系统模型的依赖,提升了自适应性以及应用前景。
53、(5)本发明相对于传统的时间触发,设计了合适的事件触发机制,有效节省了通信资源与网络带宽,同时考虑在触发后到下一次触发前这段时间事件触发机制给系统稳定性带来的影响,设计了事件触发补偿项降低这种影响的同时进一步减少触发频率即节省了通信资源,在实际一些通信资源受限的场景中有较为强的自适应性。
54、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
本文地址:https://www.jishuxx.com/zhuanli/20240730/199300.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。