一种面向机动目标的水下自主航行器跟踪控制方法
- 国知局
- 2024-07-31 23:57:45
本发明属于动态目标跟踪,具体地,涉及一种面向机动目标的水下自主航行器跟踪控制方法。
背景技术:
1、自主水下航行器的发展使许多最初在水下环境中由载人航行器完成的任务实现了自动化。自主水下航行器在海洋研究、深海勘探和研究以及军事领域都有较多的应用。随着人工智能技术的不断发展,水下相关技术的不断突破,为响应蓝海战略,对自主水下航行器控制的深入探索与研究是未来国家发展的重要趋势。
2、获得水下目标的位置(例如,被标记的物种或用于监测海洋环境的水下航行器),并能够随时间和空间跟踪它们,对于许多应用来说都非常有意义。量化动物的运动可以提供空间生态学信息,使保护和管理策略(例如在海洋保护区)得到有效应用。然而,在任务执行过程中,auv的运动容易受到洋流、波浪等因素的干扰。此外,由于auv结构复杂,其动力学是非线性的。因此,auv的控制问题变得更加难以解决。
3、随着深度学习、批量学习和经验回放技术的发展,深度强化学习在连续控制任务中表现出优异的性能,但在水下动态目标跟踪方面还没有产生完美的结果。
技术实现思路
1、针对上述问题,本发明提出了一种面向机动目标的水下自主航行器跟踪控制方法,利用深度强化学习来解决水下自主航行器的动态目标跟踪的控制问题,并且在构建过程中融入动态目标的状态信息,提高在动态目标发生机动时持续跟踪的可能性以及水下航行器的自主性。
2、本发明通过以下技术方案实现:
3、一种面向机动目标的水下自主航行器跟踪控制方法:
4、所述方法具体包括以下步骤:
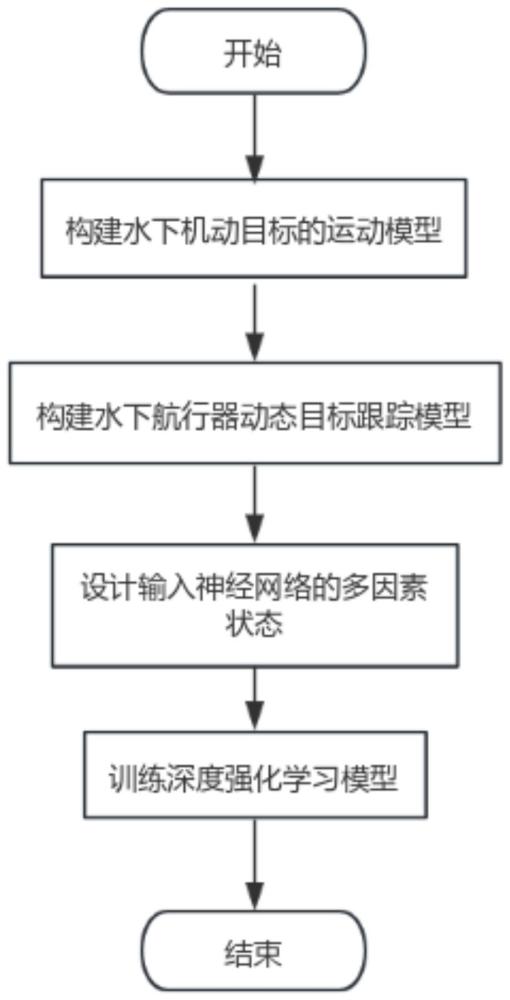
5、步骤1,构建机动目标运动模型,通过循环神经网络以及历史海洋生物的运动数据生成机动目标的运动模型,来预测机动目标的下一时刻位置;
6、步骤2,构建仿真模型,根据水下航行器数据构建航行器动态目标跟踪仿真模型,确定可行的控制量,以模拟真实的环境和水下航行器的控制行为;
7、步骤3,多因素状态的设计,定义需要输入神经网络的包含多种因素的状态表示,用于水下航行器决策时考虑的位置和方向信息;
8、步骤4,水下航行器的控制和数据存储,水下航行器根据当前状态通过行动者网络生成控制动作,并在仿真环境中执行这些动作,同时将交互数据存储到重放缓冲器中以供后续学习使用;
9、步骤5,价值评估与网络更新,水下航行器从重放缓冲器中抽取数据,使用评论家网络评估之前动作的价值,并通过计算损失来更新行动者和评论家网络,以此优化水下航行器的跟踪策略,实现面向机动目标的水下自主航行器跟踪控制。
10、进一步的,在步骤1中,
11、步骤11,从movebank中获取海洋动物追踪的数据,对数据进行处理及增强,然后由这些数据进行目标运行轨迹的生成;
12、步骤12,搭建循环神经网络,输入为海洋动物当前时刻的轨迹,输出为海洋生物下一时刻的位置,进行训练,将训练好的模型作为机动目标的运动模型。
13、进一步的,在步骤2中,所述控制量包括推进器的转速、升降舵角以及方向舵角;
14、所述航行器动态目标跟踪仿真模型包括控制模块、声呐探测模块、数据记录模块和通信模块;
15、控制模块通过推进器的转速、升降舵角以及方向舵角来控制水下航行器的移动和转向;
16、声纳探测模块通过声波的发送,反射和接受来进行目标的探测;
17、数据记录模块会将其探测到的物体以及经过的位置信息记录到存储器中;
18、通信模块用来模拟水下航行器与地面站或水面舰艇等建立通信链接,以传输数据、接收指令,以及报告任务执行情况。
19、进一步的,在步骤3中,所述多因素状态包括上一时刻水下航行器的位置以及朝向、当前水下航行器的位置以及朝向、上一时刻水下航行器采取的动作、机动目标相对当前水下航行器的位置以及朝向。
20、进一步的,在步骤4中,
21、水下航行器从模拟环境中获取当前的多因素状态信息,输入到行动者网络从而实现对水下航行器的控制,并将此过程中使用及生成的数据存储到重放缓冲器中;
22、所述重放缓冲器是指在水下航行器的内存中定义的一块保存历史经验的区域,以时间步为存储单位;使用、生成及存储的每条数据均包含水下航行器的多因素状态、当前水下航行器执行的动作以及动作执行后水下航行器的状态和获得的奖励。
23、进一步的,步骤4具体的执行过程为:将水下航行器的多因素状态信息输入到行为者网络中进行决策获得动作,在模拟环境中执行该动作,获得新的状态及奖励信息;然后将输入的状态信息、采取的动作决策、获得的状态以及奖励信息拼接在一起,形成经验,最后将拼接的经验存储在一个重放缓冲器中;
24、奖励设置由三个部分组成:当水下航行器未发现目标时,给予一个巨大的奖励来鼓励其搜索目标,并且这个奖励会随着发现时间的增大而减少,催促水下航行器尽快寻找目标;当水下航行器发现目标后,需要尽快接近目标,防止目标丢失,此时通过水下航行器与目标的距离进行奖励,距离越大,水下航行器获得的奖励越小,并进行时间惩罚,催促水下航行器尽快接近目标;当水下航行器撞到边界时,给予一个巨大的惩罚,警告水下航行器远离边界,防止发生不可控的影响。
25、进一步的,在步骤5中,
26、水下航行器从重放缓冲器中读取多条数据,将每一条数据中水下航行器的状态及生成的控制量动作输入到评论家网络,得到该条数据中动作的价值,并通过计算损失更新行动者和评论家网络;
27、评论家网络的损失函数如下:
28、
29、行动者网络的策略梯度如下:
30、
31、其中: e为期望,表示策略关于智能体的神经网络参数的梯度;是智能体的神经网络参数,是当前智能体的多因素状态,是下一步智能体的多因素状态,
32、是价值函数,是随着q函数一起更新的目标价值函数,
33、是由目标q函数预测的q值,是智能体的动作,是智能体下一步的动作;
34、是智能体执行当前动作之后获得的奖励值,是折扣值,是重放缓存器;是当前策略的参数;是目标策略的参数;
35、所述更新行动者和评论家网络具体为:
36、首先从重放缓冲器的数据中随机抽取数条经验,然后在抽取到的数条经验中抽出当前水下航行器的状态和采取的动作,合并输入到评论家网络中,得到动作评价的q值;然后根据行动者网络的策略梯度更新行动加网络;再从目标评论家网络中得到预测的q值,根据这两个q值更新评论家网络。
37、一种电子设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
38、一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时实现上述方法的步骤。
39、本发明有益效果
40、本发明相较于现有技术至少具备以下优势:
41、传统的控制方法难以适应复杂、动态和不确定的水下环境,本发明的深度强化学习可以实现端到端的学习,直接从原始输入到控制输出,减少了人为干预;
42、随着智能体与环境的持续交互,本发明的策略可以不断改进,而传统方法需要重新设计和调整来适应新的情况。
43、本发明的深度强化学习框架可以扩展到多任务和多目标跟踪场景,而传统方法需要为每个新任务或目标重新设计控制系统。
44、本发明实现了对水下机动目标的跟踪控制,提高了水下航行器的自主性,使水下航行器在目标发生机动时,能够做到有效的跟踪,减少丢失目标的可能性。
本文地址:https://www.jishuxx.com/zhuanli/20240730/199405.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。