DDR门控信号的训练系统、训练方法及介质与流程
- 国知局
- 2024-07-31 19:48:01
本发明涉及集成电路领域,尤其涉及一种ddr门控信号的训练系统、训练方法及介质。
背景技术:
1、双倍数据传输速率(double data rate,ddr)系统是双数据传输速率同步动态随机存取存储器系统的习惯性简称,其优点是存储容量大、成本低、接口成熟,而且并行突发访问时,可以达到较高的访问速率。ddr的对外信号接口主要有:时钟信号、数据信号、选通信号和命令/地址信号。
2、为了完成正常的读功能,ddr控制器需要正确接收读数据选通信号(readdatastrobe,rdqs),并通过rdqs对读数据(read data,rdq)进行采样。根据ddr4标准文档描述,rdqs包含读前导(pre)、与数据伴随的rdqs以及读后导(post)部分。如图1所示,该图1为ddr4正常读命令对应的rdqs波形,其中,读前导部分为1tck(时钟),读后导部分为0.5tck(时钟),与数据伴随的数据选通(data strobe,dqs)信号包含4个完整的rdqs_t高电平。
3、在读操作过程中,rdqs读前导之前以及读后导之后的部分,都为高阻态,高阻态与rdqs有效状态的连接位置会出现毛刺等不稳定状态。因此在ddr系统中,会使用门控信号(gate)对rdqs进行处理,只保留与数据伴随的rdqs部分。处理后的rdqs_new只保留四个完整的周期,如图2所示。由于ddr系统中,经过走线,pad延迟后,rdqs与gate的初始相对位置是不确定的,为了实现对rdqs的正确处理,ddr系统需要对门控信号进行训练,以确定其合适位置。而传统的训练方式,得到的结果会使gate上升沿与rdqs的第一个上升沿对齐,然后在该基础上将gate直接向前移动半个ui作为最终结果,但实际系统中该位置并不是最佳位置,所以说,传统的训练过程不够灵活,训练结果位置调整不够合理。
技术实现思路
1、本发明的目的在于提供一种ddr门控信号的训练系统、训练方法及介质,用以通过标准延迟单元对门控信号进行延迟控制,控制方式灵活方便,大大增强系统的稳定性,可以减小ddr整体训练过程的硬件逻辑开销。
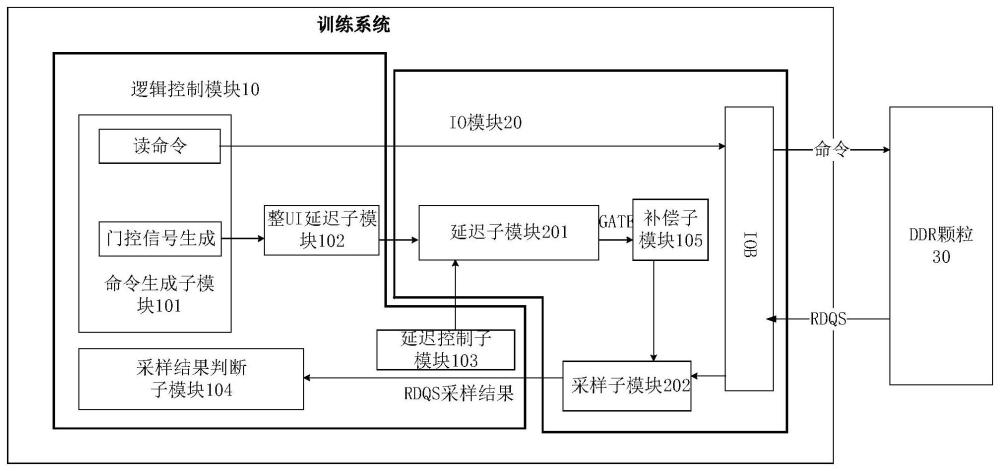
2、为实现上述目的,本发明提供一种ddr门控信号的训练系统,包括逻辑控制模块和io模块,所述io模块连接至ddr颗粒,所述逻辑控制模块包括命令生成子模块、整ui延迟子模块、延迟控制子模块和采样结果判断子模块;所述io模块中设有延迟子模块和采样子模块;所述命令生成子模块,用于生成读取ddr颗粒的读命令,以及根据所述读命令生成对应的门控信号;整ui延迟子模块,用于通过数字逻辑对所述门控信号完成至少一个整ui的粗粒度延迟处理;所述延迟子模块,用于对所述粗粒度延迟处理后的门控信号进行细粒度延迟处理;所述延迟控制子模块,用于通过配置信息调整门控信号在传输过程所经过的所述延迟子模块中标准延迟单元的数量,以细粒度调整延迟时间的长短;所述采样子模块,用于通过io模块的iob接口接收来自所述ddr颗粒的rdqs,并通过经粗粒度和细粒度延迟处理后的门控信号对rdqs进行采样;所述采样结果判断子模块,用于根据所述采样子模块的采样结果,判断当前延迟处理后的门控信号与rdqs的相对位置。
3、在一种可能的实施方式中,所述延迟子模块包括sdl和cdl,其中,sdl是由组合逻辑级联组成的具有固定延迟功能的标准延迟单元,cdl是由模拟电路组成的具有固定延迟功能的标准延迟单元。
4、另一种可能的实施方式中,所述延迟子模块由96级sdl和4级cdl串联组成。
5、其它可能的实施方式中,上述训练系统还包括补偿子模块,用于在训练结束后,分配训练结果的一部分延迟,以便在pvt变化时,对最终的门控信号的位置进行补偿。
6、本发明提供的ddr门控信号的训练系统的有益效果在于:本系统可以基于fpga,利用其内部资源搭建出一种基于可编程指令集的ddr训练平台,通过对fpga资源的组合、调用,可以实现对ddr门控信号的训练。本实施例通过延迟子模块中的标准延迟单元完成时间延迟,延迟子模块的结构简单,而且训练结果精度更高,依托于fpga的灵活性和io较强的通用性,本发明门控信号训练使用的延迟单元在其io通路上的位置与写均衡训练过程中使用的延迟单元在其对应io中的位置完全一致,因此可以复用写均衡训练过程中大部分控制逻辑,可以极大减小硬件开销并降低整体训练过程的复杂性。再者,在训练结束后,会将部分延迟分配到特定延迟单元上,用于在pvt变化时进行门控信号位置的补偿,该配置方式灵活简单,可以极大增强系统的适应性。
7、第二方面,本发明提供一种基于指令集的ddr门控信号训练方法,包括如下步骤:
8、s1,设置所述门控信号的初始位置,进入读前导训练模式,所述逻辑控制模块生成读命令及对应的门控信号;所述读命令从ddr颗粒读取n个完整的rdqs周期信号,n为正整数;
9、s2,所述采样子模块在所述门控信号的上升沿对所述rdqs进行采样,得到初始采样结果,所述多次采样结果均为稳定的参考值;
10、s3,所述整ui延迟子模块和所述延迟子模块基于指令,将所述门控信号从初始位置往后进行延迟处理,并生成读命令及与之对应的门控信号,针对延迟后的门控信号,所述采样子模块在延迟后的门控信号的上升沿对所述rdqs进行采样,得到中间采样结果;
11、s4,若所述中间采样结果均为稳定的参考值,则返回执行s3,当所述中间采样结果首次出现目标值,将首次出现目标值的中间采样结果对应的延迟后的门控信号的位置,作为不稳定区间的左边界位置;
12、s5,返回继续执行s3,当连续多个中间采样结果都为所述目标值时,结束训练,并记录最后一个出现参考值的中间采样结果所对应的门控信号的位置信息,并将其作为不稳定区间的右边界;
13、s6,将所述不稳定区间的左边界位置和右边界之间的中心位置,作为所述rdqs第一个上升沿的位置。
14、一种可能的实施例中,上述方法还包括:若所述门控信号从初始位置往后延迟到最大位置时,仍未发现所述不稳定区间,则训练失败。
15、另一种可能的实施例中,上述方法还包括:当从读前导训练模式切换到正常读模式后,根据rdqs最后一个下降沿位置确定所述门控信号的结束位置。
16、其它可能的实施例中,上述方法还包括:基于指令集在训练结束后,分配训练结果的一部分延迟到补偿子模块,以在pvt变化时,对最终的门控信号的位置进行补偿。
17、一种可能的实施例中,所述ddr颗粒的类型包括但不限于ddr3、ddr4、ddr5或lpddr。
18、本发明提供的ddr门控信号的训练方法的有益效果在于:基于指令集进行训练,对延迟的控制灵活方便,整体训练过程简单,对各种ddr系统的适应性强,训练精度高,可以大大增强系统的稳定性,通过逻辑复用,可以减小ddr整体训练过程的硬件逻辑开销。
19、第三方面,本技术实施例中还提供一种计算机可读存储介质,该计算机可读存储介质包括训练程序,当训练程序在电子设备上运行时,使得所述电子设备执行上述第一方面中的任意一种可能的设计的方法。
20、第四方面,本技术实施例还提供一种包含计算机程序产品,当所述计算机程序产品在电子设备上运行时,使得所述电子设备执行上述第一方面中的任意一种可能的设计的方法。
21、关于上述第三方面至第四方面的有益效果可以参见上述第二方面中的描述。
本文地址:https://www.jishuxx.com/zhuanli/20240731/184098.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表