一种基于内在奖励增强的强化学习交通信号控制方法
- 国知局
- 2024-07-31 20:29:06
本发明涉及智能交通,特别涉及一种基于内在奖励增强的强化学习交通信号控制方法。
背景技术:
1、
2、传统的交通信号控制方法根据预先设定的交通假设设计的,而这些假设通常与现实世界的交通状况存在偏差。同时,这些系统大多存在可扩展性问题,尤其是随着交通流量的增加以及交通拥堵的出现。因此,我们需要更智能的交通信号控制方法,以更好的感知不同情况下的交通状态。为应对这些挑战,将强化学习应用于交通信号灯控制器已成为交通工程领域的一个热门研究课题。在强化学习框架中,强化学习智能体通过环境状态感知周围环境,通过执行行动进行互动,并立即获得奖励,对相关行动进行相应评估。
3、然而,在许多实际问题中,智能体接收到的奖励信号是延误的或稀疏的,这给训练强化学习代理带来了挑战。内在奖励信号可以帮助代理探索这种环境,以寻求新的状态。目前,现有的内在奖励方法主要有两个常用分支。第一种分支是基于次数的内在奖励,通过密度模型、哈希函数激励智能体访问环境中较少遇到的状态。然而,这种方法在大的或者连续的动作空间存在挑战。第二种分支是基于预测的内在奖励,通过可学习的状态表征、随机网络蒸馏以及逆动力学模型获得当前状态和动作下预测下一个状态的误差。然而,环境中的随机动态和不可预测动态会导致所谓的"噪声电视问题"。
技术实现思路
1、本发明的目的克服现有技术存在的不足,为实现以上目的,采用一种基于内在奖励增强的强化学习交通信号控制方法,以解决上述背景技术中提出的问题。
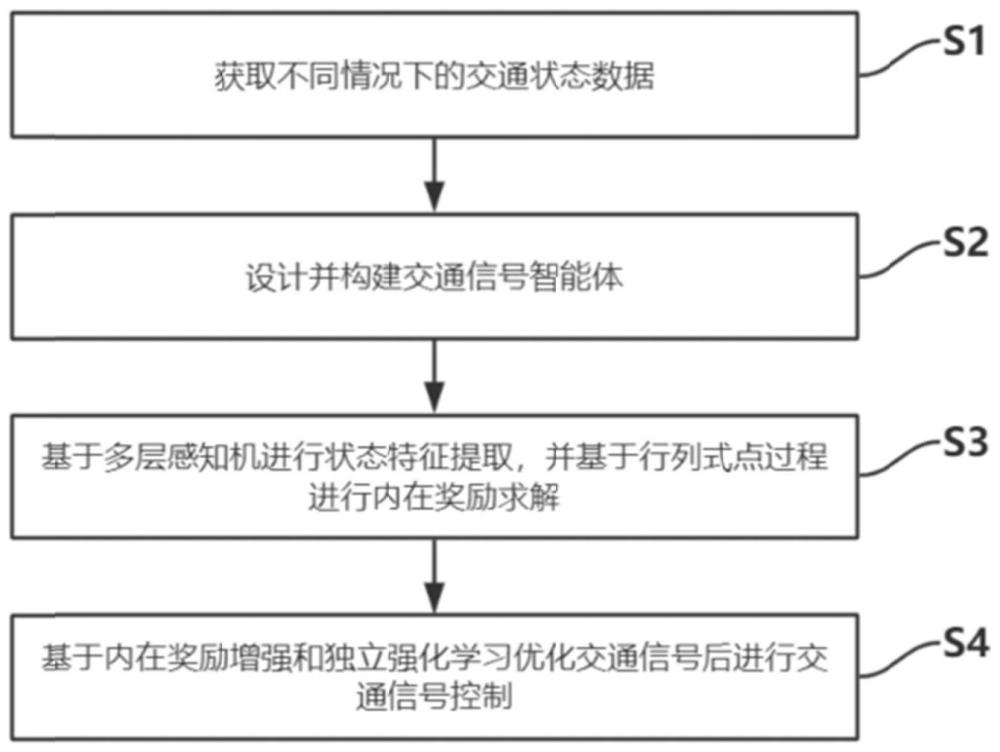
2、一种基于内在奖励增强的强化学习交通信号控制方法,包括以下步骤:
3、步骤s1、获取不同情况下的交通状态数据;
4、步骤s2、设计并构建交通信号智能体;
5、步骤s3、基于多层感知机进行状态特征提取,并基于行列式点过程进行内在奖励求解;
6、步骤s4、基于内在奖励增强和独立强化学习优化交通信号后进行交通信号控制。
7、作为本发明的进一步的方案:所述步骤s2中的具体步骤包括:
8、步骤s21、设计交通信号智能体,其中主要包括动作空间定义、状态表示,以及奖励函数设计;
9、步骤s22、设定四向交叉口i,其中每个交叉口进口道包含具有左转、直行,以及右转三个不同的车道;
10、选取排队长度、平均速度,以及相位作为状态表示,当在t时刻,交叉口i的状态表示si,t为:
11、si,t={qli,t,vli,t,pi,t},l∈li
12、其中,li表示交叉口i的进口道所有车道集合,l表示进口道车道,qli,t表示在t时刻,交叉口i车道l上的排队长度;vli,t表示在t时刻,交叉口i车道l上的的平均车辆速度;pi,t表示交叉口的当前相位;
13、步骤s23、设定四相位信号控制,其中右转车道不做控制,而每个相位对应一个动作,用于控制同一个进口道的左转与直行车道,交叉口i的动作空间ai,t定义如下:
14、ai,t={0,1}
15、其中,当信号灯保持当前相位时,ai,t被设置为1,否则被设置为0;
16、奖励函数ri,t,ex主要考虑排队长度以及压力值,作为外在奖励,具体公式如下:
17、
18、其中,li,out表示交叉口i的出口道所有车道集合,m表示出口道车道,mi表示交叉口i内进口道与出口道之间可运动集合,nli,t+1表示在t+1时刻,交叉口i车道l上的车辆数,nmi,t+1表示在t+1时刻,交叉口i车道m上的车辆数,w1与w2为权重说值,其中w1∈(-1,0),w2∈(-1,0)。
19、作为本发明的进一步的方案:所述步骤s3中的具体步骤包括:
20、步骤s31、基于多层感知机进行状态特征提取:
21、设定四向交叉口i,通过输入时刻t的状态si,t,以及时刻t+1的状态si,t+1,经过内在奖励网络以输出编码后的状态特征zi,t以及zi,t+1;其中,内在奖励网络由3个线性层以及2个relu层组成,其参数为ηi,具体公式如下:
22、
23、
24、步骤s32、基于行列式点过程进行内在奖励求解:
25、对于一个离散集合z={1,2,3,...,m},当一个行列式点过程对空集给出一个非零概率时,存在一个半正定核函数矩阵使得对于每个子集y出现的概率求解公式为:
26、p(y)∝det(ly)
27、其中,det(ly)表示矩阵ly的行列式;
28、则计算核函数矩阵计算公式如下:
29、mi=[zi,t,zi,t+1]t
30、
31、根据核函数矩阵,以及概率求解公式,得到内在奖励ri,t,in,具体公式如下:
32、
33、其中,表示元素相乘,表示的对角元素。
34、作为本发明的进一步的方案:所述步骤s4中的具体步骤包括:
35、步骤s41、设定四向交叉口i,其总奖励ri,t,mix由外在奖励函数ri,t,ex以及内在奖励ri,t,in组成,具体计算公式如下:
36、ri,t,mix=λ1ri,t,ex+λ2ri,t,in
37、其中,λ1与λ2均为权重值,其取值范围为(0,1];
38、步骤s42、基于总奖励,求解混合回报值gi,t,mix以及外在回报值gi,t,ex,具体计算公式如下:
39、
40、
41、其中,t表示时间步长;
42、步骤s43、根据交叉口i,则每个交叉口具备有一个强化学习网络
43、其中,强化学习网络由3个线性层以及2个relu层组成,通过输入交叉口i的状态表示oi,t,通过最大化损失函数,以更新强化学习网络参数θi,具体计算公式如下:
44、
45、其中,ε为裁剪超参数,以及表示当前网络以及旧网络,是旧网络与当前网络之间采取某些动作的概率比值,a(oi,t,ai,t)表示为使用广义优势估计后估计的优势函数;
46、步骤s44、采用双层优化架构以更新强化学习网络,以及内在奖励网络,具体优化目标如下:
47、
48、
49、
50、首先,利用混合回报值更新强化学习网络,具体公式如下:
51、
52、其中,α为强化学习学习率;
53、随后,通过最大化更新外在回报值,更新内在奖励网络参数,具体公式如下:
54、
55、
56、
57、
58、采用元梯度学习求解该过程,产生多样性的同时增加外在回报。
59、与现有技术相比,本发明存在以下技术效果:
60、采用上述的技术方案,通过设计并构建交通信号智能体来实现智能化的交通信号控制。这个智能体是基于行列式点过程进行内在奖励方法的设计,旨在通过自我学习和优化,逐步提升交通疏导能力。
61、且进一步结合了内在奖励和独立强化学习进行交通信号控制,以引入新的控制策略,鼓励智能体探索新的交通状态。这种新方法不仅提高了交通信号的响应速度和准确性,还使得强化学习代理能够通过基于确定性点过程评估相邻状态之间的多样性,从而学习到更高的奖励机制。这意味着智能体能够逐渐识别和适应复杂的交通情况,不断优化交通信号的配时,以实现更加流畅和安全的城市交通。这一创新性的技术应用,将为未来的城市交通管理带来革命性的变革。
本文地址:https://www.jishuxx.com/zhuanli/20240731/186425.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表