基于数字孪生的多智能体交通区域信控方法与流程
- 国知局
- 2024-07-31 20:34:29
本发明涉及智能交通,具体涉及基于数字孪生的多智能体交通区域信控方法。
背景技术:
1、传统的交通信号灯控制方式往往是固定的时序控制,缺乏灵活性和智能性,无法根据实时交通状况进行灵活调整,这导致了拥堵、延误等问题的存在。随着技术的发展,智能交通系统成为了解决城市交通管理难题的重要手段之一,与其他信号灯控制方法相比,基于强化学习的方法凭借其交互式学习最优策略的特征,十分适用于交通信号控制,可以有效的改善交叉路口的拥堵情况。然而面对大规模多路网的交通信号控制问题,基于单智能体的强化学习交通信号控制方法没有考虑到相邻路口之间存在相互影响,难以适应复杂的城市交通环境。
2、基于强化学习交通信号灯控制方法需要借助仿真或现实环境进行模型训练,一般的仿真技术仅仅能以离线的方式模拟物理世界,不具备分析优化功能,同时,仿真环境中学习到的策略不能直接部署在现实世界上,其次,使用历史交通数据或者其他仿真方式来训练模型,难以适用于实时,动态的交通状态。数字孪生技术的出现为这类问题提供了新的解决思路。
3、随着数字孪生技术的提出和发展,使用数字孪生技术构建智能交通区域信控方法成为了可能。数字孪生技术是一种将物理世界与数字世界相连接的技术,结合物联网、云计算和大数据,可以实时创建并更新物理世界的虚拟镜像,进而实现对物理世界的实时模拟和预测。将数字孪生技术和深度强化学习算法结合起来应用在区域交通路网的信号灯控制,可以对环境进行精确建模,为深度强化学习模型提供更优质精确的环境数据,提高模型的训练效率和模型拟合度,为交通信号灯控制提供更加准确的决策支持,实现对实际交通状况的智能化调控。
4、综上所述,需要设计一种基于数字孪生的多智能体交通区域信控方法,实现对大规模多路网交通区域信号灯的动态调控。
技术实现思路
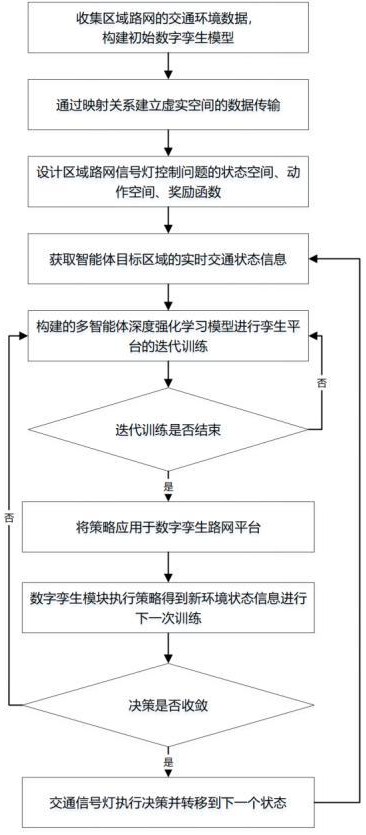
1、本发明的目的是针对大规模多路网的交通信号灯控制问题,提出一种基于数字孪生的多智能体交通区域信控方法,通过现实世界与虚拟平台的交互式训练,实现区域路网的实时动态协调控制,疏解交通拥堵情况。为了实现该目的,本发明公开了一种基于数字孪生的多智能体交通区域信控方法,所采用的步骤是:
2、步骤1:收集区域路网的交通环境数据,构建初始数字孪生模块,形成数字路网,并通过映射技术建立数字孪生平台和实体交通流之间的数据传输通道,随后感知检测模块和数据语义提取模块对交通路网中的车辆运行数据,信号灯数据等状态信息进行采集;
3、步骤2:设计区域路网交叉路口信号灯控制问题的状态空间。状态空间由三部分组成,分别为车辆状态信息、信号灯状态信息和邻居节点车辆状态信息;
4、步骤3:设计区域路网交叉路口信号灯控制问题的动作空间。动作空间由三部分组成,分别为维持当前相位、下一个信号灯相位和随机选取一个信号灯相位;
5、步骤4:设计基于深度强化学习的多智能体交通区域信控的奖励函数。奖励函数由三部分组成,分别为车辆延迟时间子奖励函数、交通饱和度等级子奖励函数和交通安全系数子奖励函数,最终的奖励函数为三类子奖励函数的线性耦合;
6、步骤5:构建基于深度强化学习的多智能体交通区域信控的网络架构,每一个智能体都采用actor-critic的强化学习网络架构,actor和critic都有两个子网络,分别为目标网络和评估网络;
7、步骤6:构建的多智能体深度强化学习模型进行迭代训练,且每一轮迭代训练后得到交叉路口的信号灯控制策略,将该策略应用于数字路网中进行区域交通信号灯控制,深度强化学习模型迭代训练至策略收敛稳定后,停止训练,输出最终的交叉路口的信号灯控制策略用于控制区域交通路网的信号灯,数字孪生模块根据采集到的新环境状态信息更新自身状态用于进行下一轮迭代训练,形成实体交通和虚拟平台的交互式训练和动态调控闭环。
8、作为本发明的优选,在步骤1中,所述状态信息是指将目标区域路网中用于控制交叉路口的每一个信号灯都视为一个智能体,收集其控制的交通道路、车辆运行数据、配套的检测传感器组件、周边环境、信号灯数据等。所述车辆运行数据包括车辆速度、车辆等待时间、车辆排队长度、车辆位置、车辆延迟时间、车辆间相隔距离、以及交通饱和度。所述信号灯数据是指当前的信号灯相位。
9、作为本发明的优选,在步骤2中,所述设计区域路网交叉路口信号灯控制问题的状态空间具体为:
10、智能体信号灯i在第t个时间步长内的观测信息由三部分组成,车辆状态信息,信号灯状态信息和邻居节点车辆状态信息。
11、第一部分是车辆状态信息,包括了车辆位置,车辆速度,车辆排队长度。车辆位置由矩阵表示,车辆速度由矩阵表示,车辆排队长度由矩阵表示,其中表示第t个时间步长内第i个车道的排队长度,n表示智能体能观测到的车道数量;
12、第二部分信号灯状态信息是指当前信号灯相位,信号相位是一种显示红、黄、绿三种信号灯色的时间顺序,本发明的十字路口均设置四个相位,主要分为南北方向和东西方向的通行,由矩阵表示;
13、第三部分是邻居节点车辆状态信息,critic网络在获得全局策略和状态时,引入折扣因子来平衡不同邻居智能体的状态输入,根据节点集合和空间上的距离由近到远逐渐衰弱,解决了多智能体算法中普遍存在的由于智能体数量的增加而导致环境不稳定的问题,同时为了保证各交叉路口的交通流量有相互影响的关系,不属于同一干线的智能体,哪怕空间距离很近也不考虑,如高架桥上方和下方的红绿灯,虽然空间距离很近,但是双方之间的车流没有影响关系,因此不考虑。若智能体仅根据自己观察到的交叉路口的交通状况进行决策分析,可能会导致其他相连车道车流量承载超出负荷,无法到达区域协调控制,因此本发明将邻居节点的状态考虑进去,邻居节点的车辆状态信息由矩阵表示;
14、综上,第i个智能体在第t个时间步长内的观测信息为 。
15、作为本发明的优选,在步骤3中,所述设计区域路网交叉路口信号灯控制问题的动作空间具体为:智能体信号灯i的动作空间。其中是指选择维持当前相位,是指选择下一个信号灯相位,是指随机选取一个信号灯相位。智能体需要先判断采取哪个动作。当选择维持当前相位时,信号灯相位不变;当智能体选择下一个信号灯相位,信号灯相位按照南北直行、南北左转、东西直行、东西左转顺序进行变换;当智能体选择随机动作时,信号灯相位会从维持不变、南北直行、南北左转、东西直行、东西左转动作空间中随机选择。
16、作为本发明的优选,在步骤4中,所述设计基于深度强化学习的多智能体交通区域信控方法的奖励函数具体为:为了提高模型的收敛精度和加快模型的训练速度,在疏解交通拥堵的同时,兼顾信号灯相位变换时的安全性,设计奖励函数包括三个部分,分别为车辆延迟时间子奖励函数、交通饱和度等级子奖励函数和交通安全系数子奖励函数,最终的奖励函数为三类子奖励函数的线性耦合;
17、(1)车辆延迟时间子奖励函数:
18、,
19、其中为越过停车线的时间,为车辆第一次被观察到的时间,为车道长度,为车辆第一次被观察到时的速度。
20、(2)交通饱和度等级子奖励函数:
21、,
22、,
23、其中,为i车道的车辆排队数,为车辆长度,为车辆与前车的相隔距离,为车道长度。
24、(3)交通安全系数子奖励函数:
25、当智能体选择动作“维持”时,=0,当智能体切换信号灯相位时其子奖励函数为:
26、,
27、其中,为车辆与前车的相隔距离,为车辆与后车的相隔距离。
28、因此,第i个智能体的奖励函数为,分别为子奖励函数的权重,。
29、作为本发明的优选,在步骤5中,所述构建基于深度强化学习的多智能体交通区域信控方法的网络架构是指路网中每个智能体都采用actor-critic网络架构,拥有四个子网络,分别为评估actor网络、目标actor网络、评估critic网络和目标critic网络。其中actor网络用于根据智能体当前状态决定采取的动作,critic网络用于根据全局的状态空间和动作空间信息评估当前状态或动作的价值,目标actor网络和目标critic网络,由各自的评估网络定期根据soft update复制得到。此外,还引入了经验回放池将收集到的历史轨迹存放在经验池中,更新时取一个小批量的数据来计算均值,通过轨迹和动态规划方法,生成若干行为策略μ,以探索一个目标策略π,能极大化目标函数:
30、,
31、其中表示目标策略 π 下的最优价值函数,e{}表示期望,n表示轨迹的时间长度,表示衰减因子,k表示t时刻之后的时间步。
32、所述actor-critic框架存在两个更新任务:actor网络的策略梯度更新和critic网络的值函数更新。所述actor网络的策略梯度更新为
33、,
34、,
35、其中表示策略梯度,为目标策略的性能,为目标策略,表示状态下选择的概率。
36、critic网络的值函数更新为使用td误差计算当前状态值和下一时刻状态值之间的误差,进而更新critic网络的参数。均方差损失函数为:
37、,
38、训练时,actor和critic网络都需要参与,actor网络首先根据当前的环境状态选择一个动作,critic网络根据actor网络的动作和全局的状态计算得到q值,来评判该动作的好坏,然后分别进行上述actor网络的策略梯度更新和critic网络的值函数更新。在执行阶段,只需要actor网络根据自身观察到交通环境状态,来完成策略的选择。经过多轮的迭代,actor和critic网络的参数逐渐趋于收敛,得到当前状态下区域交通路网信号控制的最优策略。
39、作为本发明的优选,在步骤6中,所述构建多智能体深度强化学习模型是指:
40、将数字孪生技术和多智能体算法结合起来应用在区域交通路网的信号灯控制。交通环境和多智能体深度强化学习算法嵌套在数字孪生平台中,可进行算法的多次迭代训练,不断探索和试错,直到找出最优策略。
41、采用“集中式训练,分布式执行”的方式实现模型的搭建和训练。在训练阶段,利用数字孪生技术对交通环境状态进行高精度的动态捕捉和仿真模拟,各传感器和感知组件采集交通状态信息,通过数据传输通道将数据传输到数字孪生平台,平台根据环境的动态变化更新自身的状态,并将状态发送至孪生决策模块,通过观察全局的交通状态和智能体的联合动作进行集中式的深度强化学习网络模型的迭代训练;在执行阶段,先将每一轮迭代训练后得到交叉路口的信号灯控制策略应用于数字路网中进行区域交通信号灯控制,策略收敛稳定后,输出最终的交叉路口的信号灯控制策略分布式的用于区域交通路网的信号灯,得到实体交通的下一个环境状态,同时数字孪生模块根据采集到的新环境状态信息更新自身状态,用于孪生决策模块的持续训练,形成实体交通和虚拟平台的交互式训练和动态调控闭环。
42、相较于现有技术,本发明的有益效果包括以下几方面:
43、(1)本发明使用高精度数字孪生技术构建多交叉路口区域路网,将数字孪生技术和多智能体算法结合起来应用在区域交通路网的信号灯控制,使得算法在模型训练阶段可以在与实际交通环境相同的虚拟空间中进行,有效提升了解决实际信号灯控制问题的安全性和算法策略的可用性。
44、(2)本发明采用“集中式训练,分布式执行”的合作式多智能体算法实现模型的搭建和训练,结合实际交通路网中,相邻信号灯的相关性会随着距离远近变化,引入折扣因子来平衡不同邻居智能体的状态输入,具有明确的现实指导意义。
45、(3)本发明设计的奖励函数不仅考虑了信控方法疏解交通拥堵的效果,还考虑到了信号灯变换过快可能会导致车辆发生交通事故的情况,充分保障了信号灯相位变换时的安全性。
本文地址:https://www.jishuxx.com/zhuanli/20240731/186946.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。