基于多智能体强化学习的多路口交通信号灯公平控制方法
- 国知局
- 2024-07-31 21:11:33
本发明涉及智能交通控制,特别是一种基于多智能体强化学习的多路口交通信号灯公平控制方法。
背景技术:
1、多智能体强化学习算法具有感知和自主决策的能力,已经成功应用于游戏、机器人控制等领域,但是仍面临两个亟待解决的问题:
2、(1)决策公平性欠缺。决策公平性主要用于衡量模型在应对不同群体时能否指定合理、无偏见的决策,是多智能体强化学习算法应用于实际任务的重要参考指标之一,关乎不同群体的用户体验。例如在有限资源调度任务中,决策的公平性直接关系到不同参与群体的体验和后续发展态势,甚至会影响模型性能的长期收益。在上述任务中,具备公平性感知的策略决策方式能够平衡好性能与公平性之间的关系,避免部分参与者陷入“调度饥饿”的困境,从而提升模型整体性能实现长期收益更优的目标。然而,多智能体强化学习方法是以奖励信息为主导的,容易导致动作决策具有偏向性。现有方法主要是通过改变奖励函数结构,将决策公平性度量信息结合到奖励函数中来保证决策的公平性。然而,这类方法通常以牺牲模型整体性能为代价来保证决策公平性,从而导致在模型在任务的表现不如预期。因此,如何在权衡模型总体性能和决策公平性之间找到平衡,探索能维持良好整体性能的同时确保决策公平性的策略,是一个值得研究的问题。
3、(2)训练样本效率低。大多数基于强化学习的交通信号灯控制方法忽略的另一个未解决的问题是“样本效率”。现有的方法主要依赖于模拟器,然而可用的模拟环境和真实数据集很少。一个直观的解决方案是简单地创建更多的真实数据集,然而收集交通数据需要大规模部署传感器,会带来额外的开销,并且收集和清洗交通数据的过程非常耗时。因此,一个具有样本效率的多智能体强化学习控制方法是至关重要的。
技术实现思路
1、为了解决上述技术问题,本发明提供了一种基于多智能体强化学习的多路口交通信号灯公平控制方法。
2、为达到上述目的,本发明是按照以下技术方案实施的:
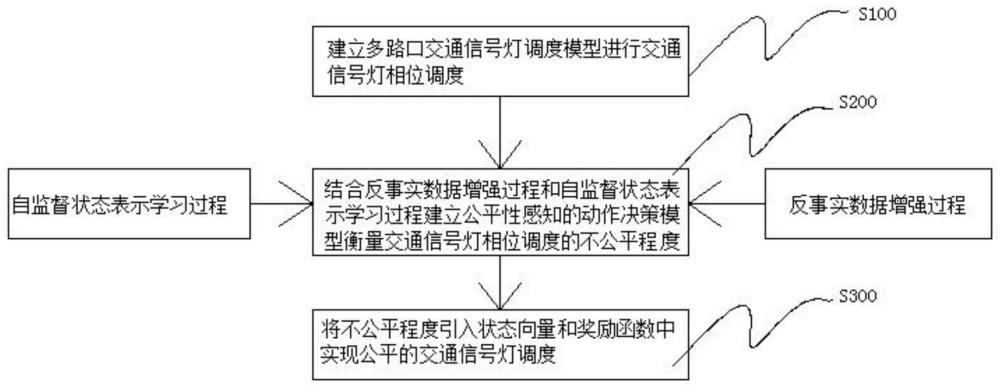
3、基于多智能体强化学习的多路口交通信号灯公平控制方法,包括以下步骤:
4、s100、建立多路口交通信号灯调度模型进行交通信号灯相位调度;
5、s200、结合反事实数据增强过程和自监督状态表示学习过程建立公平性感知的动作决策模型衡量交通信号灯相位调度的不公平程度;其中:
6、反事实数据增强过程:通过生成对抗网络近似得到环境状态转移函数,然后利用反事实学习以推断未发生的交互数据,进而丰富交互数据的多样性,帮助提升模型训练的样本效率;
7、自监督状态表示学习过程:通过自监督学习方法训练状态编码器,通过将状态编码器网络从q-网络中分离出来,并设置自监督学习辅助任务增加额外的网络训练损失,以改善状态表示,实现从高维交通数据中提取有效特征,进而提高模型的样本效率;
8、s300、将不公平程度引入状态向量和奖励函数中实现公平的交通信号灯调度。
9、进一步地,多路口交通信号灯控制问题描述为:
10、给定一个多路口交通信号灯调度任务,假设共有n个路口的信号灯需要控制;每一个路口被表示为ii,i为路口的索引值,ii包含东、南、西、北四个方向的道路并配备由强化学习策略控制的交通信号灯;每条道路包含三条车道l,根据车辆行驶方向又划分为入车道和出车道和分别表示路口ii的进车道和出车道集合;交通流m=(lin,lout)表示车辆从入车道lin驶入路口,然后从出车道lout驶离,假设有三种类型的交通流:左转、直行和右转,它们分别受交通信号灯控制;m表示所有交通流的结合;交通信号灯相位p被定义为一组允许通行的交通流;信号灯相位的集合p包含的四种信号灯相位,即其中表示东西方向的直行交通流允许通行,表示北南方向的左转交通流允许通行,每个信号灯相位的最短执行时长为δt;在某个信号灯被触发执行期间,其他道路l上等待车辆的数目表示为道路队伍长度q(l);对于路口ii而言,路口的队列长度qi被定义为所有与之相连接的入车道队伍长度之和:在此基础之上,每隔δt时长各个路口根据交通路况调度交通信号灯相位,最终实现最小化平均行驶时间。
11、进一步地,所述公平性感知的多智能体强化学习任务具体包括:
12、状态:在一个多路口交通信号灯控制任务中,每个智能体的局部观测值包含四种信息:(1)当前的信号灯相位p,(2)当前路口所有入车道中的等待车辆的数目,(3)基于额外等待时间的公平性度量指标fi以及(4)邻居路口的路况信息;其中,等待车辆数目用于反映不同信号灯相位的性能需求,公平性度量指标用于体现动作决策的不公平程度,邻居信息用于实现多个路口交通信号灯的协作调度;
13、动作:动作定义为从候选的信号灯相位集合中选取下一个时段要调度的相位,即每间隔δt时长,每个智能体选择下一个时间间隔[t,t+δt]内要调度的信号灯相位,其中候选集合中共有四种可选的相位;在动作集合a中,每个动作a由一个8-维度的向量表示,分别对应不同的交通流方向,其中1表示允许相应的交通流通行,0表示禁止相应的交通流通行;
14、奖励函数:每个智能体将从环境中获得即时奖励rt,奖励函数定义为关于路口队列长度和公平性度量指标fi的函数,具体定义如为:
15、
16、其中qt(l)表示当前路口中入车道的队列长度,表示t时刻的基于额外等待时间的公平性度量指标,ω是超参数用于权衡模型性能和决策公平性之间的重要程度;
17、在训练过程中,采取深度q-网络算法用于模型训练,它包括一对q-网络qθ和目标q-网络分别被θ和参数化。q-网络更新时采用时间差分法进行更新,其损失函数为:
18、lrl=e[(qθ(st,at)-yt)2];
19、
20、其中,γ表示用于计算累积奖励的折扣因子,以平衡长期奖励和立即奖励。
21、进一步地,反事实数据增强过程具体包括:
22、定义y={y1,…,yn}表示一组观测变量,结构因果模型的定义为yi=fi(xi,ui),其中xi表示yi的父变量,ui表示噪声。函数fi()表示因果机制,它能够建立yi,xi和ui之间的关系;在强化学习中,智能体在给定状态st执行动作a,然后观察到环境反馈的后续状态st+1;基于结构因果模型,通过推断事实情况的反事实结果,即通过在相同的环境状态st中推断执行随机动作的影响,得到预测的下一时刻状态假设t+1时刻的状态满足结构因果模型,则它的定义如下:
23、st+1:=f(st,at,ut)
24、其中f()表示因果机制函数;st和at分别表示状态和动作变量;ut表示由于未观测因素导致的噪声,它独立于st和at;
25、通过生成对抗网络近似获得状态转移函数,即因果函数f();交替地训练判别器和生成器,使得生成器生成的假样本能欺骗判别器,同时,训练后的生成器被用作因果函数,基于元组<st,at,ut>的前提下预测下一个状态生成对抗网络的损失函数定义如下所示:
26、
27、
28、其中ht表示交互数据元组,包含状态st,动作at和噪声ut;函数v(·)用于区分生成数据和原始数据的差异;函数g(·)表示生成网络用于近似替代因果函数f(·);函数d(·)表示判别器网络,用于区分真实交互数据和生成的数据;定义ρdata和分别表示下一个状态和交互元组的分布情况;
29、给定一条交互数据<st,at,st+1>,将动作a'替换原有动作a,预测下一时刻的环境状态其中,动作a'是从动作集中随机采样的,然后连同其他原始的交互信息st和ut传入生成器网络g中,输出反事实结果奖励值rt从状态信息中计算得出;得到反事实数据增强数据集有利于提高强化学习方法的样本效率。
30、进一步地,自监督状态表示学习过程具体包括:
31、状态编码器网络采用了注意力机制以实现多个交通路口之间的协作,生成的状态表示向量的定义如下:
32、
33、
34、
35、其中,embed(·)是表示函数。sim(·,·)是相似度函数,用于评估两个输入之间的相似度;ηi表示当前路口ii的邻居路口的集合;注意力权重αij用于计算最终的表示向量enco;参数wq,wc和bq是可学习的参数;
36、自监督状态表示学习包含状态编码器网络、目标状态编码器网络和转移网络;其中,状态编码器网络表示为enco负责将状态st映射到状态表示向量zt=enco(st),该表示向量同时也用作q-网络的输入信息;目标状态编码器表示为encm,它和状态编码器网络的功能相同,即以原始状态st+1为输入,输出状态表示向量zt+1=encm(st+1),它们具有相同的网络结构;转移网络表示为tr',以状态表示向量zt和动作at作为联合输入信息,然后预测下一时刻的状态表示向量z’t+1=tr'(zt,at),实现了自监督学习中正例构建的目的;最后,预期的状态表示z’t+1和原始的状态表示zt+1将用于计算自监督学习的损失函数,其定义如为:
37、
38、其中,b表示批数据的大小;在目标状态编码器网络的网络参数的更新采用指数移动平均值的方式,参考状态编码器网络的参数进行更新,更新方式的定义如下:
39、φm←τφm+(1-τ)φo;
40、其中φo和φm分别表示状态编码器网络和目标状态编码器网络的参数;
41、最终的损失中函数包含强化学习的目标函数和自监督表示学习的目标函数,它们采用随机梯度下降的方式进行联合训练,总损失函数表示为:l←lrl+λlssl,其中λ是一个超参数用于调节两种目标函数的权重。
42、与现有技术相比,本发明具有以下有益效果:
43、本发明设计了一种新型的公平性度量指标,并提出了一种公平性感知的多智能体强化学习方法,可以在确保模型性能不受影响的前提下,提供相对公平的动作决策。
44、本发明提出了反事实数据增强的模块,通过利用反事实思想,基于已有的交互数据实现数据集的扩展,有利于丰富交互数据的多样性,进而在交互数据收集受限的任务中提高训练样本效率。
45、本发明设计了辅助自监督表示学习任务,通过状态之间天然的时序关系构建自监督表示学习损失,额外训练损失的引入有利于状态信息特征提取,提升模型训练样本效率。
46、本发明在多路口交通信号灯控制(traffic signal control,tsc)任务中验证了所提出方法的有效性,实验结果表明本发明能够提供相对公平的信号灯调度策略,并且改善了模型整体性能和训练样本效率。
本文地址:https://www.jishuxx.com/zhuanli/20240731/188787.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表