一种InfluxDB时序数据库的自适应内存索引管理策略的制作方法
- 国知局
- 2024-08-05 11:42:01
本发明涉及计算机科学,尤其涉及一种influxdb时序数据库的自适应内存索引管理策略。
背景技术:
1、在influxdb时序数据库中,每个数据点(point)是由标签集(tag set)、字段集(field set)以及时间戳组成的数据集合,标签和字段作为元数据信息,用于描述相应的数据点,其中标签的作用是过滤和聚合数据。在influxdb中,我们通常会使用大量的标签,时间线(series)由测量值(measurement)、标签集和字段键(field key)组成。
2、当我们有一个包含大量标签集和字段键组合的测量值时,就会产生大量的时间线,进而可能产生高基数(high cardinality)问题,特别是在处理大规模的时间序列数据时,随着数据的不断写入,时间线的数量会持续增长。在influxdb进行压缩(compaction)的过程中,这可能导致内存溢出。
3、在实际应用场景中,选择合适的标签或避免使用过多的标签可以缓解高基数问题。然而,在许多实际应用中,这种策略可能难以实施,例如,在云原生场景中,我们通常使用containerid,prodid和e-mail等作为标签,在物联网(iot)场景中,我们可能会使用devid,userid等作为标签,由于这些字段通常是唯一的,它们可能会导致高基数问题,从而导致时间线数量急剧增加。
4、鉴于以上缺陷,提出一种influxdb时序数据库的自适应内存索引管理策略。
技术实现思路
1、本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本申请的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
2、鉴于上述的问题,提出了本发明。
3、为解决上述技术问题,本发明提供如下技术方案:一种influxdb时序数据库的自适应内存索引管理策略,包括:
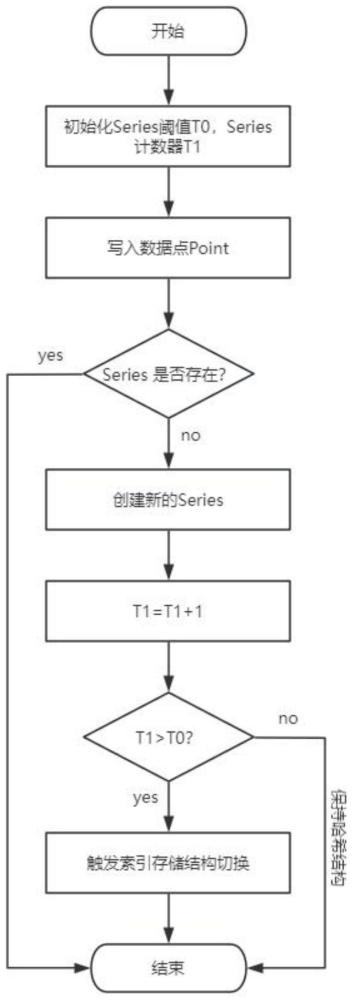
4、s1,对可能发生时间线膨胀的measurement的时间线进行统计,设置measurement时间线阈值为t0。
5、s2,在series index增加cache type表示作为当前measurement的索引存储进行标识,索引标识取值为0和1两种情况,分别表示哈希结构的索引和b+树结构的索引,默认为0。
6、s3,当measurement的时间线数量超过时间线阈值时将哈希结构切换为b+树结构,完成切换后将cache type赋值为1。
7、作为本发明所述一种influxdb时序数据库的自适应内存索引管理策略的一种优选方案,其中,s3中measurement的时间线数量超过时间线阈值的判断方法为:判断t1是否大于t0。
8、作为本发明所述一种influxdb时序数据库的自适应内存索引管理策略的一种优选方案,其中,s3中具体切换流程为:
9、s31,创建新的b+树对象;
10、s32,复制哈希map中的数据;
11、s33,设置series index的数据结构类型;
12、s34,设置cache type值;
13、s35,删除哈希map中的数据。
14、作为本发明所述一种influxdb时序数据库的自适应内存索引管理策略的一种优选方案,其中,s31具体为:创建两个新的b+树对象,分别用于存放keyidmap和idoffsetmap的数据。
15、作为本发明所述一种influxdb时序数据库的自适应内存索引管理策略的一种优选方案,其中,s32具体为:在切换数据结构时需要将哈希map中的所有数据复制到新的b+树中。
16、作为本发明所述一种influxdb时序数据库的自适应内存索引管理策略的一种优选方案,其中,s33具体为:将series index中keyidmap和idoffsetmap的数据结构类型使用新创建的b+树对象替换。
17、作为本发明所述一种influxdb时序数据库的自适应内存索引管理策略的一种优选方案,其中,s34具体为:将cache type设置为1,标志当前索引存的储结构类型为b+树,完成series index时间线索引存储结构的切换。
18、作为本发明所述一种influxdb时序数据库的自适应内存索引管理策略的一种优选方案,其中,s35具体为:完成数据复制后,删除哈希map中的所有数据,并释放相关的内存空间。
19、作为本发明所述一种influxdb时序数据库的自适应内存索引管理策略的一种优选方案,其中,将所有数据复制到新的b+树中具体为:遍历keyidmap和idoffsetmap中的所有数据,将每对series key-series id和series id-offset的映射关系插入到b+树中。
20、本发明的有益效果:
21、1、可以动态地根据measurement时间线设定的阈值调整内存索引存储结构,对于时间线数量超出阈值的measurement,将series索引信息的存储结构从哈希map结构切换到b+树,对于不膨胀的时间线,则继续使用哈希map结构。
22、2、通过这种策略,能够以比较小的源码改造便可解决时序数据库的时间线膨胀问题,提升influxdb时序数据库的可靠行和稳定性。
技术特征:1.一种influxdb时序数据库的自适应内存索引管理策略,其特征在于,包括:
2.根据权利要求1所述的一种influxdb时序数据库的自适应内存索引管理策略,其特征在于,s1中对measurement的时间线进行统计的方法具体为:为measurement创建时间线计数器t1,当写入数据的时候需要创建新的时间线时,对t1进行累计。
3.根据权利要求2所述的一种influxdb时序数据库的自适应内存索引管理策略,其特征在于,s3中measurement的时间线数量超过时间线阈值的判断方法为:判断t1是否大于t0。
4.根据权利要求1所述的一种influxdb时序数据库的自适应内存索引管理策略,其特征在于,s3中具体切换流程为:
5.根据权利要求4所述的一种influxdb时序数据库的自适应内存索引管理策略,其特征在于,s31具体为:创建两个新的b+树对象,分别用于存放keyidmap和idoffsetmap的数据。
6.根据权利要求5所述的一种influxdb时序数据库的自适应内存索引管理策略,其特征在于,s32具体为:在切换数据结构时需要将哈希map中的所有数据复制到新的b+树中。
7.根据权利要求6所述的一种influxdb时序数据库的自适应内存索引管理策略,其特征在于,s33具体为:将series index中keyidmap和idoffsetmap的数据结构类型使用新创建的b+树对象替换。
8.根据权利要求7所述的一种influxdb时序数据库的自适应内存索引管理策略,其特征在于,s34具体为:将cache type设置为1,标志当前索引存的储结构类型为b+树,完成series index时间线索引存储结构的切换。
9.根据权利要求8所述的一种influxdb时序数据库的自适应内存索引管理策略,其特征在于,s35具体为:完成数据复制后,删除哈希map中的所有数据,并释放相关的内存空间。
10.根据权利要求6所述的一种influxdb时序数据库的自适应内存索引管理策略,其特征在于,将所有数据复制到新的b+树中具体为:遍历keyidmap和idoffsetmap中的所有数据,将每对series key-series id和series id-offset的映射关系插入到b+树中。
技术总结本发明公开了一种InfluxDB时序数据库的自适应内存索引管理策略,包括:对可能发生时间线膨胀的Measurement的时间线进行统计并设置阈值、时间线数量超过时间线阈值时将哈希结构切换为B+树结构,其有益效果为:可以动态地根据Measurement时间线设定的阈值调整内存索引存储结构,对于时间线数量超出阈值的Measurement,将Series索引信息的存储结构从哈希map结构切换到B+树,对于不膨胀的时间线,则继续使用哈希map结构;通过这种策略,能够以比较小的源码改造便可解决时序数据库的时间线膨胀问题,提升InfluxDB时序数据库的可靠行和稳定性。技术研发人员:黎海育,朱志鹏,沈治廷,杨傲受保护的技术使用者:天翼云科技有限公司技术研发日:技术公布日:2024/8/1本文地址:https://www.jishuxx.com/zhuanli/20240802/258889.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。