一种基于任务导向预训练的法律事件检测模型构建方法与应用
- 国知局
- 2024-08-05 12:06:33
本发明属于人工智能,更具体地,涉及一种基于任务导向预训练的法律事件检测模型构建方法与应用。
背景技术:
1、法律事件检测旨在自动识别出法律案件中的事件候选触发词的事件类型,从而完成案件事实的快速重构,是实现智能辅助办理和管理决策的重要环节;因此,法律事件检测逐渐开始成为重要的研究热点。
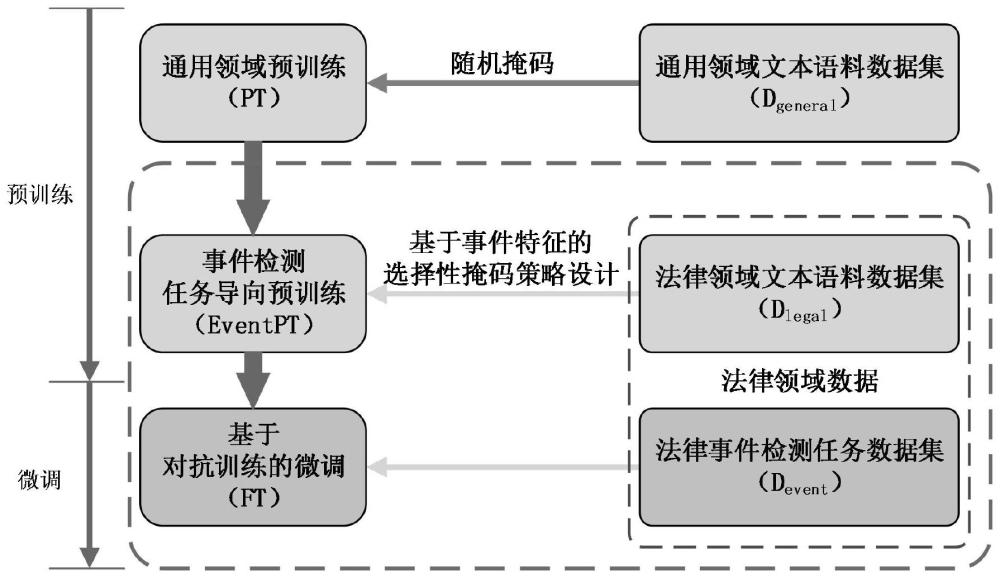
2、现有的法律事件检测模型通常基于大量公开的裁判文书数据构建无监督的领域预训练语料,并基于随机掩码策略来训练法律领域的预训练语言模型,进而基于预训练语言模型所提取的特征来实现法律事件检测。虽然法律领域的预训练语言模型与法律领域相关,但是掩码过程存在随机性,并未与下游的事件检测任务紧密关联,无法准确地进行法律事件检测。
技术实现思路
1、针对现有技术的以上缺陷或改进需求,本发明提供了一种基于任务导向预训练的法律事件检测模型构建方法与应用,用以解决现有技术无法准确地进行法律事件检测的技术问题。
2、为了实现上述目的,第一方面,本发明提供了一种基于任务导向预训练的法律事件检测模型构建方法,包括:
3、将预采集的法律领域文本语料数据集中的每一个法律判决文书事实部分文本token化,得到对应的token序列;对token序列中表征法律事件语义特征的token进行掩码,并输入至文本特征提取模块中进行mlm预训练,得到训练好的文本特征提取模块;其中,文本特征提取模块包括级联的嵌入层和预训练语言模型;
4、将预采集的事件检测任务数据集中的每一个法律文本与对应的预设触发词进行拼接,得到拼接文本后,输入至法律事件检测模型中进行法律事件类型检测,通过最小化检测得到的法律事件类型与对应法律事件类型标签之间的差异,对法律事件检测模型进行训练;
5、其中,事件检测任务数据集包括:带有预设触发词以及对应法律事件类型标签的法律文本;法律事件检测模型包括:级联的token化层、训练好的文本特征提取模块和分类模块。
6、进一步优选地,token序列中表征法律事件语义特征的token包括:词性为动词的token。
7、进一步优选地,token序列中表征法律事件语义特征的token包括:将token序列输入至触发词检测模型后所得的触发词token;
8、其中,触发词检测模型通过以下方式获取得到:
9、将事件检测任务数据集中的每一个法律文本token化,得到对应的token序列,并输入至第一神经网络模型中,以对该token序列中每一个token是否为触发词token进行检测,通过最小化检测结果与对应的触发词判断真实结果之间的差异,对第一神经网络模型进行训练;将训练完成后的第一神经网络模型作为触发词检测模型;
10、触发词判断真实结果基于法律文本所对应的预设触发词获取得到,包括法律文本的token序列中每一个token是否为触发词token的真实信息。
11、进一步优选地,token序列中表征法律事件语义特征的token包括:将token序列输入至重要token检测模型后所得的重要token;
12、其中,重要token检测模型通过以下方式获取得到:
13、对于事件检测任务数据集中的每一个法律文本:对其进行token化,并将所得的token序列中的每一个token按照先后顺序依次加入至初始为空的序列q中;将每加入一个token后的序列q输入至检测模型m0中进行法律事件类型检测,获取检测结果为对应法律事件类型标签的概率;对于每一个token,计算加入该token前、后所得的概率之差的绝对值,作为该token的贡献度;将贡献度大于预设阈值的token作为该法律文本所对应的重要token标签;
14、将事件检测任务数据集中的每一个法律文本token化,得到对应的token序列后,输入至第二神经网络模型中,以对该token序列中每一个token是否为重要token进行检测,通过最小化检测结果与对应的重要token判断真实结果之间的差异,对第二神经网络模型进行训练;将训练完成后的第二神经网络模型作为重要token检测模型;
15、其中,检测模型m0通过将事件检测任务数据集中的法律文本token化后输入至第三神经网络模型中进行训练后得到;重要token判断真实结果基于法律文本所对应的重要token标签获取得到,包括法律文本的token序列中每一个token是否为重要token的真实信息。
16、进一步优选地,token序列中的第i个token的贡献度为:
17、
18、其中,xi为token序列中的第i个token;为将加入前i个token后的序列q输入至检测模型m0中所得的检测结果为对应法律事件类型标签的概率;为将加入前i-1个token后的序列q输入至检测模型m0中所得的检测结果为对应法律事件类型标签的概率。
19、进一步优选地,上述法律事件检测模型的构建方法还包括:
20、为每一个拼接文本生成对应的对抗样本,并将该拼接文本中法律文本所对应的法律事件类型标签作为该对抗样本的法律事件类型标签;
21、将每一个对抗样本输入至法律事件检测模型中进行法律事件类型检测,通过最小化检测得到的法律事件类型与对应法律事件类型标签之间的差异,对法律事件检测模型进行训练,以实现法律事件检测模型的对抗训练。
22、第二方面,本发明提供了一种法律事件检测方法,包括:
23、将待检测的法律文本与对应的预设触发词拼接后,输入至法律事件检测模型中,得到其法律事件类型的检测结果;
24、其中,法律事件检测模型通过本发明第一方面所提供的法律事件检测模型构建方法构建得到。
25、第三方面,本发明提供了一种电子设备,存储器和处理器,包括:存储器存储有计算机程序,处理器执行计算机程序时执行本发明第一方面或第二方面所提供的方法。
26、第四方面,本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时执行本发明第一方面或第二方面所提供的方法。
27、总体而言,通过本发明所构思的以上技术方案,能够取得以下有益效果:
28、1、本发明第一方面提供了一种基于任务导向预训练的法律事件检测模型构建方法,所构建的法律事件检测模型包括:级联的token化层、训练好的文本特征提取模块和分类模块;在对文本特征提取模块进行训练的过程中,将法律领域文本语料数据集中的法律判决文书事实部分文本对应的token序列中表征法律事件语义特征的token进行掩码后,再输入至文本特征提取模块中进行mlm预训练;本发明通过基于法律事件特征的选择性掩码策略实现了法律事件检测任务导向的领域预训练,从而将文本特征提取模块中预训练语言模型的训练与法律事件检测任务相关联,对法律事件关键要素具备良好的感知理解与特征提取能力,显著提高了法律事件检测的准确性。
29、2、进一步地,本发明所提供的法律事件检测模型构建方法,提出了一种基于动词的选择性掩码策略,考虑到文本中的动词往往表示相关事件的动作触发词,因此在预训练阶段可以对这些动词进行选择性掩码,能够以较低的计算成本进一步实现与下游的法律事件检测任务的紧密关联。
30、3、进一步地,本发明所提供的法律事件检测模型构建方法,考虑到包含丰富法律事件特征信息的触发词并非都是动词,还有可能是其他词性,因此基于动词的选择性掩码策略可能无法使得文本特征提取模块能够全方面地理解事件特征,基于此,本发明提出了一种基于触发词的选择性掩码策略,基于携带有预设触发词的事件检测任务数据集来训练触发词检测模型,作为选择性掩码模型,以对法律领域文本语料数据集中的文本进行选择性掩码,该方法能够进一步优化法律事件检测模型对特定裁判文书事件特征的理解和处理能力。
31、4、进一步地,本发明所提供的法律事件检测模型构建方法,考虑到一种基于触发词的选择性掩码策略中所采用的选择性掩码模型的准确性,依赖于训练集中触发词的设定,受制于标注人员主观判断的影响,特别在文本复杂且专业性极强的法律领域;基于此,本发明提出了一种基于token贡献度的选择性掩码策略,通过训练重要token检测模型来获取输入文本中对下游的法律事件检测任务贡献度更高的重要token,对其进行掩码,不仅考虑了词本身是否为潜在的触发词,还要考虑了其所在的具体上下文,识别哪些上下文环境下的特定词汇对下游的法律事件检测任务贡献度更高,然后优先对这些情境下的词汇进行掩码,以进一步提高了法律事件检测的准确性。
32、5、进一步地,本发明所提供的法律事件检测模型构建方法,对法律事件检测模型在事件检测任务数据集上基于对抗训练策略进行微调,使得法律事件检测模型对法律事件之间细微差别具备优异地捕捉与分辨能力,进一步提高了法律事件检测模型的准确性、泛化性和鲁棒性。
本文地址:https://www.jishuxx.com/zhuanli/20240802/261102.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表