一种索引布隆过滤器以及基于索引布隆过滤器的DDS自动发现算法
- 国知局
- 2024-08-08 16:58:33
本发明属于计算机,特别是涉及一种索引布隆过滤器以及基于索引布隆过滤器的dds自动发现算法。
背景技术:
1、在当今复杂的飞机、汽车和火车系统设计中,分布式系统的应用愈发重要。dds中间件作为可靠的数据通信技术,在分布式环境中实现高性能、实时的数据传输,发挥着重要作用。它提供通信、消息传递和协议适配等功能,协调和管理分布式系统的各个部分。
2、在dds的通信过程中,节点发现机制至关重要,它帮助分布式系统中的节点相互发现和建立通信关系,使节点能自动地发现其他节点,并获取相关信息,如其可用性、qos(quality ofservice)要求等。通过节点发现机制,节点能够动态地加入或离开dds系统,而无需手动配置或静态预定义节点的信息。
3、为了实现在不同dds之间的互操作性和透明度,omg标准化了dds互操作性有线协议(dds interoperabilitywire protocol),其规定任何兼容的dds-rtps实现必须至少支持sdp协议。
4、然而,对于民用飞机等大规模分布式系统设计,sdp协议存在匹配效率低下,匹配时间过长和高带宽消耗等问题,无法满足大规模的数据传输需求。布隆过滤器(bloomfilter,bf)是一种经典的数据结构,具有高效的查询速度和低内存消耗的特点,在分布式系统中应用广泛。在dds中,布隆过滤器可以应用于节点发现过程中的信息压缩和快速匹配,减少网络负载和节点资源消耗,提高节点发现的效率和性能。
5、但需要注意的是,布隆过滤器在判断元素是否存在于集合中时可能产生误判。其误判率与它的大小和所使用的哈希函数数量相关,基于布隆过滤器的dds自动发现算法研究也大都建立在其改良之上,如符号布隆过滤器(symbol bloom filter,sbf)和单哈希多维布隆过滤器(one hash many dimensions bloom filter,ombf),前者通过增加符号向量来降低误判率,但增加了查询和插入操作的复杂性;后者使用单个哈希函数,通过多维不同分区位向量的映射操作保证哈希函数的均匀性和随机性,以一定的误判率换取更快的查询时间。然而这些单一性能的改良对于dds自动发现算法的提升有限,随着网络规模的增大,另一性能的短板也会影响到发现算法的匹配效率。
6、因此,需要提出一种更全面的布隆过滤器来进行dds自动发现算法,以应对日益复杂的分布式系统挑战。
技术实现思路
1、针对这些问题,本发明提出了一种用于大规模分布式系统的索引布隆过滤器(index bloom filter,ibf),并结合sdp实现了基于该过滤器的dds自动发现算法。在多维位图的基础上,将标准bf中存储信息的位向量替换成根据端点信息生成的索引向量,并通过索引间的异或操作来进行元素的插入和查找,这种方式仅需要两个哈希函数就可以保证可接受的误判率,同时还能保证快速的查找时间,提高了自动发现的匹配效率和速度,能够满足类似机载信息系统这种大规模分布式系统的通信需求。
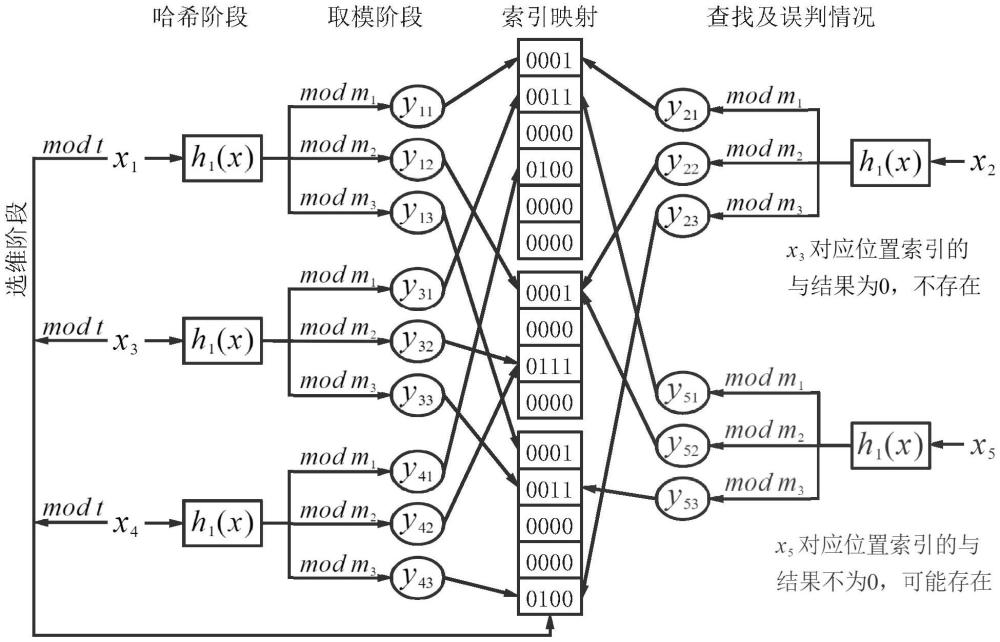
2、本发明提供了一种索引布隆过滤器,其特征在于,包括:多维分区的索引向量位图和哈希函数,所述索引向量位图用于保存过滤器中元素的存在信息,所述哈希函数包含第一哈希函数和第二哈希函数,所述第一哈希函数和所述第二哈希函数分别用于生成索引值和锁定映射位置。
3、优选地,索引向量位图为t维位向量,其中每一维有3个分区,大小分别为m1、m2、m3,分区的大小设置为互不相同的质数。
4、本发明还提供了一种基于索引布隆过滤器的dds自动发现算法,使用上述的索引布隆过滤器,其特征在于,包括如下流程:s1,分区阶段;s2,哈希阶段;s3,取模阶段;s4,索引映射阶段。
5、优选地,在s1中,将给定的m大小的位向量分成k个大小不一的分区{m1,m2,...,mk},分区的大小设置为质数,分区中的每个位置是一个z位的索引。
6、优选地,在s2中,将待插入元素x通过第一哈希函数h1(x)映射,得到机器字。
7、优选地,在s3中,利用分区,对机器字进行取模运算,得到元素x在每个分区中的映射位置。
8、优选地,在s4中,通过第二哈希函数h2(x)对元素x进行计算,并利用2z对计算结果进行取模得到元素x对应的索引值,随后与s3中得到的所有映射位置的索引值分别进行或运算,更新索引布隆过滤器中每个映射位置的索引值。
9、与现有技术相比,本申请的技术方案具有以下有益技术效果:
10、本发明基于多维位向量结构和索引值间的位操作设计出一种索引布隆过滤器,用于压缩分布式系统网络节点间的传输信息,同时提供比标准布隆过滤器更低的误判率。通过将索引布隆过滤器与sdp结合,能够减少dds自动发现过程中的资源消耗并提高匹配效率。实验结果表明,在节点匹配率10%的情况下,本发明提出的dds自动发现算法相比基于标准布隆过滤器的sdpbloom算法,发现过程的数据包数量减少了46.39%,匹配时间缩短了73.30%。
技术特征:1.一种索引布隆过滤器,其特征在于,包括:多维分区的索引向量位图和哈希函数,所述索引向量位图用于保存过滤器中元素的存在信息,所述哈希函数包含第一哈希函数和第二哈希函数,所述第一哈希函数和所述第二哈希函数分别用于生成索引值和锁定映射位置。
2.根据权利要求1所述索引布隆过滤器,其特征在于,所述索引向量位图为t维位向量,其中每一维有3个分区,大小分别为m1、m2、m3,所述分区的大小设置为互不相同的质数。
3.一种基于索引布隆过滤器的dds自动发现算法,使用权利要求1所述的索引布隆过滤器,其特征在于,包括如下流程:
4.根据权利要求3所述的基于索引布隆过滤器的dds自动发现算法,其特征在于,在所述s1中,将给定的m大小的位向量分成k个大小不一的分区{m1,m2,...,mk},所述分区的大小设置为质数,所述分区中的每个位置是一个z位的索引。
5.根据权利要求4所述的基于索引布隆过滤器的dds自动发现算法,其特征在于,在所述s2中,将待插入元素x通过第一哈希函数h1(x)映射,得到机器字。
6.根据权利要求5所述的基于索引布隆过滤器的dds自动发现算法,其特征在于,在所述s3中,利用所述分区大小,对所述机器字分别进行取模运算,得到所述元素x在每个分区中的映射位置。
7.根据权利要求5所述的基于索引布隆过滤器的dds自动发现算法,其特征在于,在所述s4中,通过第二哈希函数h2(x)对所述元素x进行计算,并利用2z对计算结果进行取模得到所述元素x对应的索引值,随后与s3中得到的所有映射位置的索引值分别进行或运算,更新索引布隆过滤器中每个映射位置的索引值。
技术总结本发明提出了一种用于大规模分布式系统的索引布隆过滤器(IBF),并结合SDP实现了基于该过滤器的DDS自动发现算法。在多维位图的基础上,将标准BF中存储信息的位向量替换成根据端点信息生成的索引向量,并通过索引间的异或操作来进行元素的插入和查找,这种方式仅需要两个哈希函数就可以保证可接受的误判率,同时通过将索引布隆过滤器与SDP结合,减少DDS自动发现过程中的资源消耗并提高匹配效率。实验结果表明,在节点匹配率10%的情况下,本发明提出的DDS自动发现算法相比基于标准布隆过滤器的SDPBloom算法,发现过程的数据包数量减少了46.39%,匹配时间缩短了73.30%。技术研发人员:刘黄彪,宋歌,张琦,张小贝受保护的技术使用者:上海大学技术研发日:技术公布日:2024/8/5本文地址:https://www.jishuxx.com/zhuanli/20240808/271570.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表