一种基于对比表征的跨域离线强化学习方法及装置
- 国知局
- 2024-08-22 14:47:42
本发明涉及强化学习领域,更具体的涉及一种基于对比表征的跨域离线强化学习方法及装置。
背景技术:
1、在离线强化学习中,智能体从固定的数据集中学习策略,而无需与环境进行额外的在线交互,可以有效节约数据收集过程中的时间成本和经济成本。但在自动驾驶、健康医疗等特定现实场景中,测试环境与训练环境往往并不相同,故收集充足且具有良好状态转移覆盖率的离线数据是极其耗时且昂贵的。一种有前景的解决思路是采用跨域离线强化学习,即利用额外的、具有不同状态转移动态的源域数据集来弥补目标域数据短缺的问题,从而提高数据效力。
2、跨域离线强化学习是一种通过结合有限的目标域数据和部分存在动态偏差的源域数据来提高离线强化学习性能的方法。其主要考虑通过共享源域数据来缓解目标域数据短缺的问题,从而增加目标域的数据效力。然而,由于源域和目标域之间存在动态偏差,简单地合并两个域的离线数据集可能会导致性能退化和无法实现稳定策略改进的问题。故而,跨域离线强化学习面临两个关键问题:如何有效量化动态偏差以及如何利用跨域数据。
3、针对第一个问题,现有方法直接使用离线数据集来估计动态模型,或者训练域鉴别器来近似动态差异。然而,鉴于目标域数据有限,直接估计动态模型存在着较大的外推误差,而域鉴别器则无法对动态差异提供平滑的测量,可能会导致无界问题(即当两个域显著不匹配时,动态差异logpsource/ptarget[s′|s,a]可能会无限制增大),从而无法得到一个有效的估计。针对第二个问题,现有方法使用动态偏差作为补偿项来修改奖励函数,或者为源域数据应用悲观支持约束(即选取转移概率较高的源域样本进行训练,并对源域的动作值函数进行悲观估计),或者采用数据共享的方式进行筛选具有较小动态偏差的源域数据。尽管取得了这些进展,但当面对更大的动态差异时,这些方法通常会出现快速的性能下降。
4、综上所述,现有的跨域离线强化学习方法存在确定给定有限目标域数据时,显式估计动态模型存在误差以及域分类器并不能平滑地估计动态偏差,可能会导致无界问题。
技术实现思路
1、本发明实施例提供一种基于对比表征的跨域离线强化学习方法及装置,用于解决现有跨域离线强化学习方法存在确定给定有限目标域数据时,显式估计动态模型存在误差以及域分类器并不能平滑地估计动态偏差,可能会导致无界问题。
2、本发明实施例提供一种基于对比表征的跨域离线强化学习方法,包括:
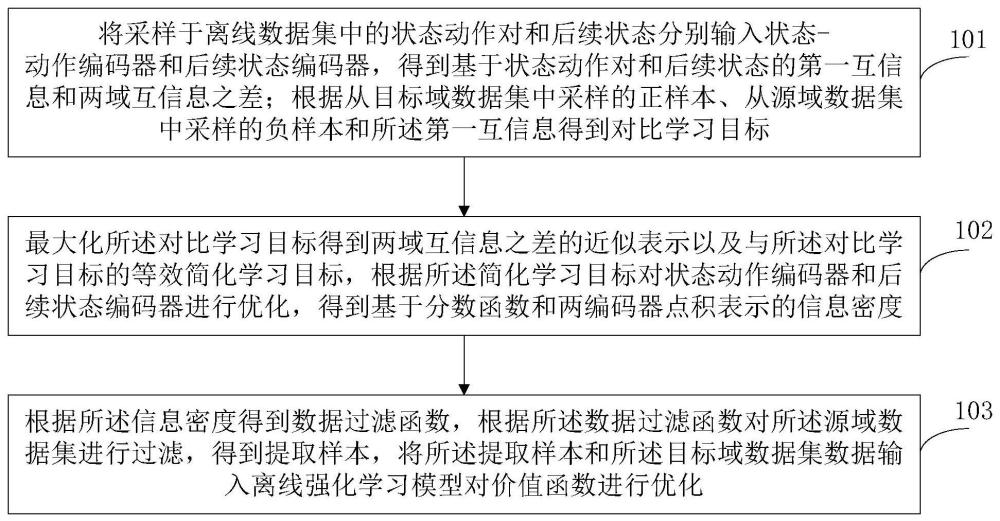
3、将采样于离线数据集中的状态动作对和后续状态分别输入状态动作编码器和后续状态编码器,得到基于状态动作对和后续状态的第一互信息和两域互信息之差;根据从目标域数据集中采样的正样本、从源域数据集中采样的负样本和所述第一互信息得到对比学习目标;
4、最大化所述对比学习目标得到两域互信息之差的近似表示以及与所述对比学习目标的等效简化学习目标,根据所述简化学习目标对状态动作编码器和后续状态编码器进行优化,得到基于分数函数和两编码器点积表示的信息密度;
5、根据所述信息密度得到数据过滤函数,根据所述数据过滤函数对所述源域数据集进行过滤,得到提取样本,将所述提取样本和所述目标域数据集数据输入离线强化学习模型对价值函数进行优化。
6、优选地,所述得到基于状态动作对和后续状态的第一互信息和两域互信息之差,具体包括:
7、基于所述第一互信息得到目标域互信息和源域互信息,根据所述目标域互信息和所述源域互信息得到两域互信息之差;
8、所述第一互信息如下所示:
9、
10、所述两域互信息之差如下所示:
11、δi=itar([s,a];s′)-isrc([s,a];s′)
12、其中,([s,a];s′)表示离线数据集中状态动作对[s,a]的联合分布与后续状态s’之间的第一互信息,es,a,s′~d表示对离线数据集d内所有样本值求期望,(s,a)表示当前状态动作对,s’表示后续状态,p(s,a,s′)表示当前状态动作对(s,a)与后续状态s’的联合概率分布函数,p(s,a)表示当前状态动作对(s,a)的边缘概率分布函数,p(s′)表示后续状态s’的边缘概率分布函数,itar([s,a];s′)表示目标域数据集中状态动作对于后续状态的目标域互信息,isrc([s,a];s′)表示源域数据集中状态动作对与后续状态的源域互信息,δi表示两域互信息之差。
13、优选地,所述离线数据集中的后续状态包括来自于所述目标数据集中的第一后续状态和来自于所述源域数据集中的第二后续状态;
14、所述根据从目标域数据集中采样的正样本、从源域数据集中采样的负样本和所述第一互信息得到对比学习目标,具体包括:
15、从所述目标域数据集中采样状态动作对和第一后续状态组成状态转移样本,将所述状态转移样本确定为正样本;将所述目标域数据集中采样状态动作对和从所述源域数据集中采样第二后续状态确定为负样本;
16、所述对比学习目标如下所示:
17、
18、
19、
20、其中,h2(s,a,s′b)表示量化目标域信息密度比的分数函数,h1(s,a,s′a)表示量化源域信息密度比的分数函数,表示所述目标域数据集中的经验动态转移函数,表示源域数据集中的经验动态转移函数,表示所述目标域数据集的归一化状态分布,表示所述源域数据集的归一化状态分布,表示对所述目标域数据集内正样本值求期望,表示对所述源域数据集内负样本值求期望,s′-∈ds,s′a∈ds,s′b∈dt。
21、优选地,最大化所述对比学习目标得到两域互信息之差的近似表示以及与所述对比学习目标的等效的简化学习目标,具体包括:
22、最大化所述对比学习目标,得到如下所示的两域互信息之差的近似估计:
23、δi≥log(k-1)-lnce:=ince
24、所述简化学习目标如下所示:
25、
26、其中,k表示所述负样本的数量,log(k-1)-lnce定义为悲观下界ince,ince与动态比率δp相比,是一个相对更紧的两域互信息差的下界,其随着k的增大而更紧,表示对所述源域数据集内所有样本值求期望,表示目标域数据集中的经验动态转移函数,表示源域数据集中的经验动态转移函数,表示简化学习目标,表示对所述目标域数据集内正样本值求期望,表示对所述源域数据集内负样本值求期望,h(s,a,s′b)表示来自目标域的正样本对应的分数函数,s′a∈s′-∪s′b表示选取来自源域的所有负样本及正样本,h(s,a,s′a)表示所有样本对应的分数函数。
27、优选地,所述基于分数函数和两编码器点积表示的信息密度,如下所示:
28、h(s,a,s′)=exp(φ(s,a)tψ(s′))
29、所述数据过滤函数如下所示:
30、
31、其中,h(s,a,s′)表示近似信息密度,φ(s,a)表示状态动作编码器,ψ(s′)表示后续状态编码器,ω(s,a,s′)表示定义的数据过滤函数,表示指示函数,如果括号内条件成立,指示函数返回1,否则返回0,hξ%表示前百分数的分数函数阈值。
32、优选地,所述价值函数如下所示:
33、
34、其中,表示对目标域数据集内所有样本值求期望,表示对源域数据集内所有样本值求期望,lq(θ)表示用于价值函数学习的贝尔曼损失函数,α表示使用分数函数加权td-error的重要性系数,tqθ表示用于离线强化学习的贝尔曼算子,qθ表示离线强化学习的动作值函数,h(s,a,s′)表述近似信息密度、ω(s,a,s′)表示据过滤函数。
35、优选地,所述得到基于状态动作对和后续状态的两域互信息差之后,还包括:
36、将从所述源域数据集中得到的所述提取样本添加到所述目标域数据集时,若所述源域数据集和所述目标域数据集存在大偏差时,则确定所述提取样本在所述目标域数据集中出现的状态概率趋于零,所述源域数据集和所述目标域数据集之间的动态偏差趋于无穷小;
37、所述源域数据集和所述目标域数据集之间的动态偏差如下所示:
38、
39、其中,δp表示源域数据集和所述目标域数据集之间的动态偏差,表示对源域数据集内的所有样本求期望值,为目标域数据集的经验动态转移函数,为源域数据集的经验动态转移函数。
40、本发明实施例提供一种基于对比表征的跨域离线强化学习装置,包括:
41、第一得到单元,用于将采样于离线数据集中的状态动作对和后续状态分别输入状态动作编码器和后续状态编码器,得到基于状态动作对和后续状态的第一互信息和两域互信息之差;根据从目标域数据集中采样的正样本、从源域数据集中采样的负样本和所述第一互信息得到对比学习目标;
42、第二得到单元,用于最大化所述对比学习目标得到两域互信息之差的近似表示以及与所述对比学习目标的等效简化学习目标,根据所述简化学习目标对状态动作编码器和后续状态编码器进行优化,得到基于分数函数和两编码器点积表示的信息密度;
43、优化单元,用于根据所述信息密度得到数据过滤函数,根据所述数据过滤函数对所述源域数据集进行过滤,得到提取样本,将所述提取样本和所述目标域数据集数据输入离线强化学习模型对价值函数进行优化。
44、本发明实施例提供一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行上述任意一项所述的基于对比表征的跨域离线强化学习方法。
45、本发明实施例提供一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行上述任意一项所述的基于对比表征的跨域离线强化学习方法。
46、本发明实施例提供一种基于对比表征的跨域离线强化学习方法及装置,该方法包括:将采样于离线数据集中的状态动作对和后续状态分别输入状态动作编码器和后续状态编码器,得到基于状态动作对和后续状态的第一互信息和两域互信息之差;根据从目标域数据集中采样的正样本、从源域数据集中采样的负样本和所述第一互信息得到对比学习目标;最大化所述对比学习目标得到两域互信息之差的近似表示以及与所述对比学习目标的等效简化学习目标,根据所述简化学习目标对状态动作编码器和后续状态编码器进行优化,得到基于分数函数和两编码器点积表示的信息密度;根据所述信息密度得到数据过滤函数,根据所述数据过滤函数对所述源域数据集进行过滤,得到提取样本,将所述提取样本和所述目标域数据集数据输入离线强化学习模型对价值函数进行优化。该方法通过利用离线数据集中状态动作对与下一状态之间的联合经验分布来计算俩个域之间的互信息,并建立了两域互信息之差与动态偏差之间的定量关系,该衡量方法相比之前直接计算动态比率的方法更加鲁棒,避免了动态偏差较大时存在的无界问题;通过引入基于神经网络的变分估计器,法可以有效地在高维状态空间对互信息进行估计,通过近似信息密度的方法得到一个更紧的悲观估计下界;通过两编码器点积值对过滤的状态转移对进行排序,提取用于数据共享的提取样本,有选择性地共享动态偏差较小的源域数据进行训练;通过使用分数函数对过滤数据的时间差分误差进行加权,相比于修改价值函数用于悲观估计的方式更加便捷,并进一步提高了算法的性能。解决了现有跨域离线强化学习方法存在确定给定有限目标域数据时,显式估计动态模型存在误差以及域分类器并不能平滑地估计动态偏差,可能会导致无界问题。
本文地址:https://www.jishuxx.com/zhuanli/20240822/279904.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。